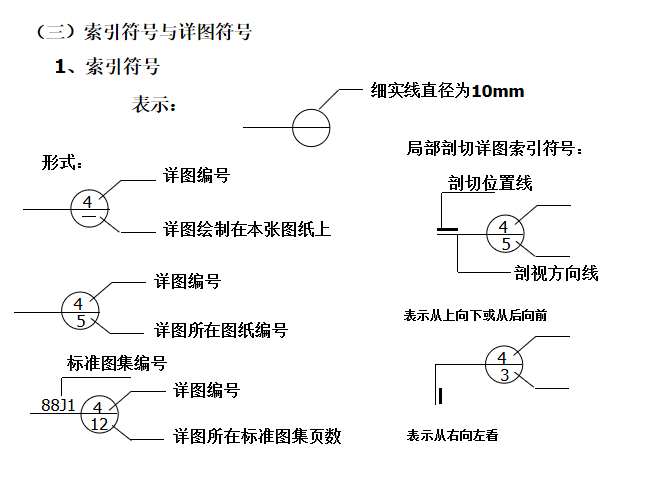
搜索引擎的极致优化——思想以及相关的数据结构
LSM 理念
LSM(Log Merge Tree),最早由谷歌“”提出,目标是保证写入性能,同时支持更高效的检索,在很多NoSQL中都用到了,而且也是用LSM的思想写的。
普通的B+树添加记录可能需要seek+操作,需要大量的磁盘seeks来移动磁头。而LSM记录在文件末尾,顺序写入减少了摇头/寻道,执行效率高于B+树。 LSM的具体原理是什么?
为了保持磁盘的IO效率,避免直接修改索引文件,所有的索引文件一旦生成,都是只读的,不能更改。操作流程如下:
将新添加的索引保存在内存中,内存缓存(也就是);当内存中的索引数量达到一定阈值时,触发写操作,将这部分数据写入新文件,我们称之为;即新文件生成后,无法修改;该操作和操作不会立即导致原始数据被修改或删除,而是以相同的方式存储和标记;最终得到大量文件,以减少对资源的占用,提高检索效率。这些小的将定期合并成大的。由于map中的数据是经过排序的,merge中不会出现随机写操作;通过合并,也可以进行求和运算。真正生效,删除冗余数据,节省空间。
合并过程:
基本
每个文件有一个固定的N个,如果超过N就创建一个新的;当数大于M时,合并大数;当大数大于M时,合并更大的文件,以此类推。
但是,这会带来一个问题,即创建了大量文件,最坏的情况是搜索所有文件。
Like and 这个问题的解决方案是实现一个分层,而不是根据文件大小执行合并操作。
每一层维护指定数量的文件,以确保键不重叠。搜索一个键只会找到一个键;每个文件只会合并到上一层的一个文件中。当一层文件数达到一定数量时,合并到上一层。
所以,LSM 在日志和传统的单文件索引(B+树,哈希索引)之间是中立的,它提供了一种机制来管理更小的独立索引文件()。
通过管理一组索引文件而不是单个索引文件,LSM 使昂贵的随机 IO 对于 B+ 树等结构更快,但代价是读取操作处理大量索引文件 () 而不是 One,另一个是合并操作消耗了一些IO。
设计思路与 LSM 类似,但有些不同。它继承了 LSM 数据写入的优点,但只能提供近实时查询,不能提供实时查询。
数据保存在内存中,在刷新或刷新之前无法搜索,这就是为什么说它提供接近实时而不是实时查询的原因。看了它的代码,发现写数据查查也不是不行,只是实现起来比较复杂。原因是中文数据搜索依赖于建好的索引(比如求逆依赖Term),而中文数据索引是在flush时建的,而不是实时建的,目的是为了建最高效的索引。当然也可以引入另外一套索引机制,在实时写入数据时构建,但是这个索引的实现会和现在的内部索引不同。它需要引入一个额外的写时索引和另一套查询机制,具有一定的复杂性。 .
FST

数据字典术语,通常从数据字典中查找指定单词的方式是对所有单词进行排序,使用二分查找。该方法的时间复杂度为Log(N),占用空间大小为O(N*len(term))。缺点是比较消耗内存,而且有完整的条款。当词条数达到千万级时,内存消耗非常大。
自 4 以来大量使用的数据结构是 FST(状态)。 FST 有两个优点:
占用空间少,通过读词拆分和重用前缀和后缀重用来压缩存储空间;查询速度快,查询时间复杂度只有O(len(term))
那么FST数据结构的原理是什么?我们先来看看什么是FSM(State),一个有限状态机,从“起始状态”到“终止状态”,接受一个字符后,循环或者转移到下一个状态。
FST是一种特殊的FSM,用于实现NLP中的字典查找功能(在NLP中也可以做转换功能),FST可以用FST的形式表示
示例:对“cat”、“deep”、“do”、“dog”和“dogs”五个词构造FST(注意:必须排序),结构如下:
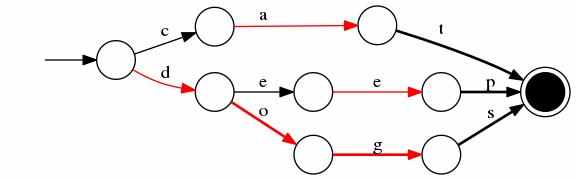 @ >
@ >
当值为对应的docId时,如cat/0 deep/1 do/2 dog/3 dogs/4,FST结构图如下:
@ >FST还有一个特点,就是在公共前缀的基础上,也会做一个公共后缀,目的也是为了压缩存储空间。
红色弧线为NEXT-,可通过绘图工具测试。
此数据结构用于快速找到 docid。它具有以下特点:
元素排序,对应我们的倒链,按照docid排序,从小到大;跳跃有固定的间隔,需要建立时指定。 ,比如下图中,区间为;,表示整体有多少层
跳表指针在哪里设置?
• 设置更多的指针,更短的步长,更多的跳跃机会
• 更多指针比较时间和更多存储空间
• 设置更少的指针,更少的指针比较次数,但需要设置更长的步长 更少的连续跳转
如果倒排表的长度为L,则每隔一个间隔,一个跳表指针以步长S均匀放置。
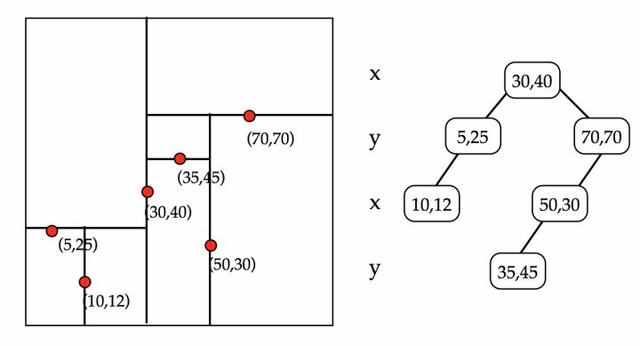
BKD树
也称为Block KD-tree。按照FST的思想,如果查询条件太多,就需要根据FST找到每个条件的结果,进行联合操作。如果是数字类型,可能会有很多潜在的词条,查询销量会很低。为了支持高效的数值类或多维查询,引入了 BKD Tree。在一个维度上,它是一个二叉搜索树。在二维中,如果要查询一个区间,logN的复杂度可以访问叶子节点对应的倒链。
确定切分维度,其中维度的选择顺序为本维度方法中数据量最大的维度优先。一个直接的理解就是数据越分散,我们优先分割。分割点就是这个维度的中点。第 1 步和第 2 步是递归执行的。我们可以设置一个阈值。点数小于点数后,直到所有点都被分割后才会停止分割。
过滤器
二进制处理,BKD-Tree找到的docID是无序的,所以要么先转换成有序的docID数组,要么构造,再与其他结果合并。
是一种预排序,只有在ES6.0之后才有。与查询时的Sort不同,它是一种预排序,即数据按照某个Index的设置进行预排序,不能更改。
每个文档都会被分配一个docID,它从0开始,按顺序分配。如果不是,则按照文档的写入顺序分配 docID。设置后,docID的顺序与.
例如,如果文档中有一列,我们设置为倒序排序,那么在一个内,docID越小,对应的文档越大,也就是按照降序排列的顺序分配了 docID。
之所以可以优化性能,是因为可以提前中断,提高数据压缩率,但不能满足所有场景,比如使用非预排序字段排序,写的时候也会消耗性能。
搜索引擎依靠优秀的理论和极致的优化来达到极致的查询性能。后期会结合源码分析和压缩算法,达到极致的性能优化。
郑重声明:本文版权归原作者所有,转载文章仅出于传播更多信息之目的。如果作者信息标注有误,请尽快联系我们修改或删除,谢谢。