xml文件怎么打开?xml文件的解析
如何打开xml文件(xml文件解析)1.解析方法
1. 有两种解析方式,分别是:
区别在于:
2. xml解析开发包:三个解析包都支持xml文件的DOM和SAX解析
2. JDK中通过解析器以DOM方式解析XML文件的实现代码
1. 基本实现
import java.io.IOException;import javax.xml.parsers.DocumentBuilder;import javax.xml.parsers.DocumentBuilderFactory;import javax.xml.parsers.ParserConfigurationException;import org.w3c.dom.Document;import org.w3c.dom.Node;import org.w3c.dom.NodeList;import org.xml.sax.SAXException;/** * @ClassName:Demo1 * @Description:使用jdk中提供的包以DOM方式解析xml文件,代码步骤如下 */public class Demo1 {public static void main(String[] args) {try {//1. 获取解析器的工程类对象DocumentBuilderFactoryDocumentBuilderFactory domfac=DocumentBuilderFactory.newInstance();//2. 通过工厂类获取DOM解析器对象DocumentBuilder docb=domfac.newDocumentBuilder();//3. 解析指定路径的xml文件,并返回一个Document对象,Document对象中保存着整个xml文件中所有的元素节点Document doc=docb.parse("url");//4. 依据节点元素的名称来获取节点元素,返回的是一个NodeList对象NodeList list= doc.getElementsByTagName("name");//5. 从NodeList对象中遍历获取节点元素Node对象for(int i=0;iprintln(node.getTextContent());;//获取当前节点中的文本数据}} catch (ParserConfigurationException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (SAXException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}}
2. 添加子节点和删除子节点
import java.io.IOException;import javax.xml.parsers.DocumentBuilder;import javax.xml.parsers.DocumentBuilderFactory;import javax.xml.parsers.ParserConfigurationException;import org.w3c.dom.Document;import org.w3c.dom.Element;import org.w3c.dom.Node;import org.w3c.dom.NodeList;import org.xml.sax.SAXException;public class Demo2 {public static void main(String[] args) {try {//1. 获取解析器的工程类对象DocumentBuilderFactoryDocumentBuilderFactory domfac=DocumentBuilderFactory.newInstance();//2. 通过工厂类获取DOM解析器对象DocumentBuilder docb=domfac.newDocumentBuilder();//3. 解析指定路径的xml文件,并返回一个Document对象,Document对象中保存着整个xml文件中所有的元素节点Document doc=docb.parse("url");//4. 创建节点元素对象,并添加文本内容Element e=doc.createElement("节点元素名称");e.setTextContent("文本内容");//5. 依据节点元素的名称来获取节点元素,返回的是一个NodeList对象NodeList list= doc.getElementsByTagName("name");//6. 从NodeList对象中遍历获取节点元素Node对象for(int i=0;i
3. 对象中数据的回写:将xml文件解析成对象后,修改对象后,需要回写到xml文件中
import java.io.IOException;import javax.xml.parsers.DocumentBuilder;import javax.xml.parsers.DocumentBuilderFactory;import javax.xml.parsers.ParserConfigurationException;import javax.xml.transform.Transformer;import javax.xml.transform.TransformerConfigurationException;import javax.xml.transform.TransformerException;import javax.xml.transform.TransformerFactory;import javax.xml.transform.dom.DOMSource;import javax.xml.transform.stream.StreamResult;import org.w3c.dom.Document;import org.w3c.dom.Node;import org.w3c.dom.NodeList;import org.xml.sax.SAXException;/** * @ClassName:Demo3 * @Description:通过javax.xml.transform.Transformer类将内存中的树形结构的DOM数据回写到文件中进行保存 */public class Demo3 {public static void main(String[] args) {try {DocumentBuilderFactory domfac=DocumentBuilderFactory.newInstance();DocumentBuilder docb=domfac.newDocumentBuilder();Document doc=docb.parse("url");NodeList list= doc.getElementsByTagName("name");//进行增删改修改元素节点,然后回写,比如修改某个节点的文本内容list.item(0).setTextContent("新文本内容");/* * 数据回写代码 *///首先获取javax.xml.transform.Transformer类TransformerFactory transformerFactory=TransformerFactory.newInstance();Transformer trans=transformerFactory.newTransformer();//绑定要回写的Document对象DOMSource doms=new DOMSource(doc);//指定要回写到哪个xml文件中,参数写系统绝对路径或相对于当前类文件的相对路径//或者是一个File类型的对象,也可以是一个输出流对象StreamResult sr=new StreamResult("url");//进行回写trans.transform(doms, sr);} catch (ParserConfigurationException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (SAXException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (TransformerConfigurationException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (TransformerException e) {// TODO Auto-generated catch blocke.printStackTrace();}}}
4. 生成解析xml文件的对象,对象的回写封装可以成为一个工具类:
import java.io.IOException;import javax.xml.parsers.DocumentBuilder;import javax.xml.parsers.DocumentBuilderFactory;import javax.xml.parsers.ParserConfigurationException;import javax.xml.transform.Transformer;import javax.xml.transform.TransformerConfigurationException;import javax.xml.transform.TransformerException;import javax.xml.transform.TransformerFactory;import javax.xml.transform.dom.DOMSource;import javax.xml.transform.stream.StreamResult;import org.w3c.dom.Document;import org.xml.sax.SAXException;/** * @ClassName:MyDomUtil * @Description:解析xml文件以及部分处理操作的封装类 */public class MyDomUtil {//获取解析指定xml文件得到的Document对象public static Document readDocument(String url) throws ParserConfigurationException, SAXException, IOException{DocumentBuilderFactory domfac=DocumentBuilderFactory.newInstance();DocumentBuilder docb=domfac.newDocumentBuilder();Document doc=docb.parse(url);return doc;}//向磁盘中的文件回写Document对象中的数据,url指定文件所在的路径,doc指定要回写的Document对象public static void writeDocument(String url,Document doc) throws TransformerException{TransformerFactory fac=TransformerFactory.newInstance();Transformer trans=fac.newTransformer();DOMSource dom=new DOMSource(doc);StreamResult sr=new StreamResult(url);trans.transform(dom, sr);}}
3. JDK中通过解析器以SAX方式解析XML文件的实现代码
1. SAX原理:SAX使用事件处理来解析XML文件,主要分为解析器和事件处理程序两部分。
请注意,SAX 解析 xml 文件不能添加、删除或修改标记元素,只能查询。
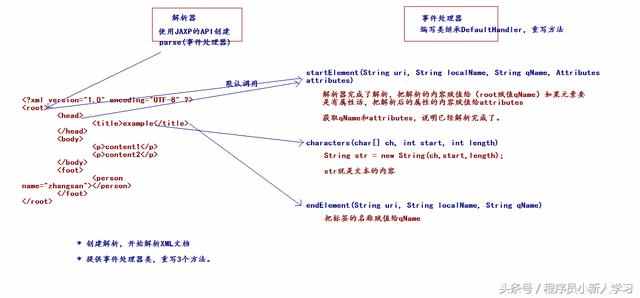
2. 代码实现:

import java.io.IOException;import javax.xml.parsers.ParserConfigurationException;import javax.xml.parsers.SAXParser;import javax.xml.parsers.SAXParserFactory;import org.xml.sax.Attributes;import org.xml.sax.SAXException;import org.xml.sax.helpers.DefaultHandler;/** * @ClassName:Demo4 * @Description:以SAX方式解析xml文件 */public class Demo4 {public static void main(String[] args) {try {//获取解析器SAXParserFactory fac=SAXParserFactory.newInstance();//解析器工厂SAXParser saxp=fac.newSAXParser();//解析器//解析XML文件,对于事件处理器需要由自己设计实现saxp.parse("url", new MyHandler());} catch (ParserConfigurationException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (SAXException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}}/** * @ClassName:MyHandler * @Description:重写事件处理器中部分方法逻辑,实现自己事件处理器类 */class MyHandler extends DefaultHandler{/** * @Title:startElement * @Description:解析器解析xml文件中每一个标签的开始标签时(即),默认调用该方法,并把解析的内容传入方法参数 * @param uri * @param localName * @param qName 标签名 * @param attributes 标签中的所有属性 * @throws SAXException * @see org.xml.sax.helpers.DefaultHandler#startElement(java.lang.String, java.lang.String, java.lang.String, org.xml.sax.Attributes) */public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {// 在此处实现自己的处理逻辑System.out.println(qName);}/** * @Title:characters * @Description:解析器解析xml文件中的标签内的文本内容时),默认调用该方法将标签中的文本内容作为参数传入 * @param ch * @param start * @param length * @throws SAXException * @see org.xml.sax.helpers.DefaultHandler#characters(char[], int, int) */@Overridepublic void characters(char[] ch, int start, int length) throws SAXException {// 在此处实现自己的处理逻辑System.out.println(new String(ch));}/** * @Title:endElement * @Description:解析器解析xml文件中每一个标签的结束标签时(即 ),默认调用该方法,并把解析的内容传入方法参数 * @param uri * @param localName * @param qName 标签名 * @throws SAXException * @see org.xml.sax.helpers.DefaultHandler#endElement(java.lang.String, java.lang.String, java.lang.String) */@Overridepublic void endElement(String uri, String localName, String qName) throws SAXException { // 在此处实现自己的处理逻辑System.out.println(qName);}}
4. 通过 Dom4J 包解析 XML 文件
首先,必须导入 dom4j 包才能使用
1.分析:
import java.util.List;import org.dom4j.Document;import org.dom4j.DocumentException;import org.dom4j.Element;import org.dom4j.io.SAXReader;public class Demo1 {public static void main(String[] args) {try {//获取解析器对象SAXReader,SAXReader是Dom4J包中SAX方式解析XML文件的类SAXReader sax=new SAXReader();//解析指定路径下的xml文件,获取该xml文件的Document对象Document doc=sax.read("url");//获取根节点,必须先获取根节点之后才能进行后续子标签的解析处理//Dom4J中解析xml文件,获取标签节点时,必须一层一层的获取,也就是说,必须先获取父节点,然后才是子节点Element root=doc.getRootElement();//获取子节点,并进行解析List list1=root.elements();//获取root节点下所有的直接子节点,并以集合形式返回List list2=root.elements("name");//获取root节点下所有的直接子节点中指定名称的节点,并以集合形式返回Element e=root.element("name");//获取root节点下所有的直接子节点中指定名称的第一个节点String text=e.getText();//获取标签节点内容} catch (DocumentException e) {// TODO Auto-generated catch blocke.printStackTrace();}}}
2. 实现节点元素的增删改查:
import java.io.FileOutputStream;import org.dom4j.Document;import org.dom4j.DocumentException;import org.dom4j.Element;import org.dom4j.io.OutputFormat;import org.dom4j.io.SAXReader;import org.dom4j.io.XMLWriter;public class Demo2 {public static void main(String[] args) throws Exception {//获取解析器对象SAXReader reader=new SAXReader();//解析获取XML文件的Document对象Document doc=reader.read("url");//获取根节点Element root=doc.getRootElement();//获取要修改的节点,在这个节点下添加一个子节点Element e=root.element("name");Element child=e.addElement("childname");//在这个节点下添加一个名为childname的子节点并返回这个子节点//设置文本内容child.setText("xxx");//回写,使用专用的一个流XMLWriterOutputFormat format=OutputFormat.createPrettyPrint();//如果使用该类,则输出到文件中后,会有对齐空格符format.setEncoding("utf-8");//设置文件编码XMLWriter writer=new XMLWriter(new FileOutputStream("目标文件路径"),format);writer.write(doc);writer.close();//关闭流}}
郑重声明:本文版权归原作者所有,转载文章仅出于传播更多信息之目的。如作者信息标注有误,请尽快联系我们修改或删除,谢谢。