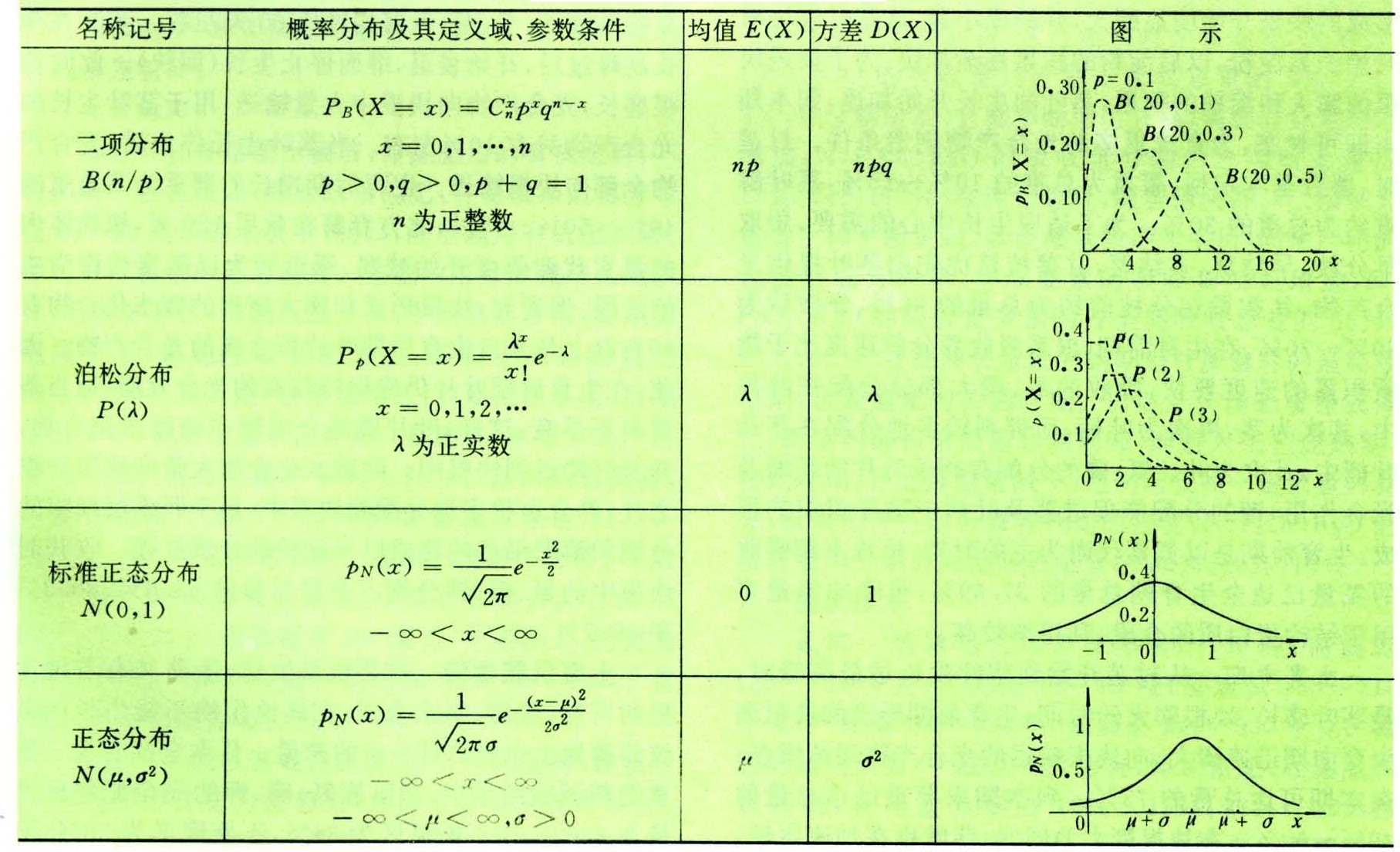
爬了杭州的租房数据,原来……
大家好,我是“猫玛尼”,一名程序员。
在外打工,大部分人每个月总要花一笔钱在租房上面,一起来看看杭州的租房情况。
数据来源是F天下,该网站,按照百度的说法:“是全球最大的房地产家居网络平台”,数据源靠谱。
一共爬取到15485条出租房源数据,按照区域分布如下:
【数据分析】
一、房源分布
我们可以清晰地看到,几大城区,房源数量基本上都比较接近。上下两城和拱墅较少一点,这也符合实际情况,近几年杭州往外扩,余杭、萧山、滨江等地区房源自然也多了。后面5个周边,桐庐、富阳、临安、建德、杭州周边,房源较少。
二、租金差异
标价大,不一定就代表实际租金高,还需要考虑标价对应的出租面积,比如A房源4000块每月(面积150平米),B房源2600块每月(面积50平米),显然不能直接说4000块每月的贵。得把月租金,均摊到每平米,就能做出公平的比较。即一平米每月需要多少钱:
A房源:4000块每月 /150平米 = 26.67
B房源:2600块每月 / 50平米 = 52
计算之后发现B房源更贵。
按照这个思路,我们计算出各个地区,一平米每月多少价格。计算的是平均数:
数值做了四舍五入,取整。其中江干、西湖、滨江、上城,价格都超过了50。
我们来计算一下各主要城区,租住一间20平米的房间,房租平均要花费多少钱:
江干:20 * 55 =1100
余杭:38 * 20 =760
西湖:53 * 20 =1060
萧山:40 * 20 = 800
滨江:60 * 20 = 1200
下城:47 * 20 =940
上城:68 * 20 =1360
拱墅:45 * 20 = 900
大家可以看下自己是高于平均还是低于平均。总体上,房租每个月花费1000,在杭州基本是少不了的。
这个统计,和我们平时的认知还是比较符合的,越往周边,租金越便宜。滨江,互联网公司较多,里面有好多拿着高工资的程序员、产品经理,他们消费能力强,当地的租金自然也水涨船高了。
从图表来看,余杭相对来说租金较便宜,如果不计较路程的话,租住在余杭也是个不错的选择。
三、租住方式
整租数量最大:
四、户型
经过统计,1室1厅、3室2厅、2室1厅、2室2厅最多,都是主流户型。再其他的户型,数量就很少了,我把他们合并成了“其他”:
五、房屋特色
这个统计,可以很清晰的看出卖家的营销套路,基本都是给房源标上类似“拎包入住”、“随时看房”、“随时入住”、“家电齐全”、“南北通透”。
这个从侧面也说明了,大家租房会比较看重:是否能够直接、简便的入住。
图中“合租男生”、“合租女生”看不太清,实际上这两个是差了一倍的,虽然数据样本总体不算大,但还是能看出来女生更受欢迎一些,我猜想可能是女生比较爱干净吧。
其实还有更多有意思的分析,篇幅原因,就分析到这里了。

【原始数据】
原始数据提取地址如下:
【代码】
数据源:F天下(机智的你,应该知道是哪个网站)的租房栏目
只需要创建两张表,如下:
BEGIN;### 房天下所有城市的主页信息
DROP TABLE IF EXISTS `sou_fang_city_index`;
CREATE TABLE `sou_fang_city_index` (`id` INT NOT NULL AUTO_INCREMENTCOMMENT '数据库自增ID',`create_time` DATETIME NOT NULL DEFAULT '1970-01-01 00:00:01'COMMENT '数据创建时间',`modify_time` DATETIME NOT NULL DEFAULT '1970-01-01 00:00:01'COMMENT '数据修改时间',`province_name` VARCHAR(40) NULLCOMMENT '省份名称',`city_name` VARCHAR(10) NOT NULLCOMMENT '城市名称',`city_index_url` VARCHAR(40) NOT NULLCOMMENT '城市首页链接',PRIMARY KEY (`id`),UNIQUE KEY `uk`(`city_index_url`)
)ENGINE = InnoDBDEFAULT CHARSET = utf8mb4COMMENT = '房天下所有城市的主页信息';# 房天下租房数据
DROP TABLE IF EXISTS `sou_fang_renting`;
CREATE TABLE `sou_fang_renting` (`id` INT NOT NULL AUTO_INCREMENTCOMMENT '数据库自增ID',`create_time` DATETIME NOT NULL DEFAULT '1970-01-01 00:00:01'COMMENT '数据创建时间',`modify_time` DATETIME NOT NULL DEFAULT '1970-01-01 00:00:01'COMMENT '数据修改时间',`city_index_id` INT NOT NULLCOMMENT 'sou_fang_city_index的自增ID',`province_name` VARCHAR(40) NULLCOMMENT '省份名称',`city_name` VARCHAR(10) NOT NULLCOMMENT '城市名称',`area_name` VARCHAR(20) NOT NULLCOMMENT '区域名称',`detail_url` VARCHAR(120) NOT NULLCOMMENT '房屋详情的url',`name` VARCHAR(50)COMMENT '名称',`rent_way` VARCHAR(4)COMMENT '出租方式',`door_model` VARCHAR(4)COMMENT '户型',`area` VARCHAR(10)COMMENT '建筑面积',`toward` VARCHAR(10)COMMENT '朝向',`unit_price` VARCHAR(10)COMMENT '单价',`feature` VARCHAR(100)COMMENT '特色',PRIMARY KEY (`id`),UNIQUE KEY (`detail_url`)
)ENGINE = InnoDBDEFAULT CHARSET = utf8mb4COMMENT = '房天下租房数据';# 搜房网-小区详情首页-小区详情-原始数据
DROP TABLE IF EXISTS `fang_community_detail`;
CREATE TABLE `fang_community_detail` (`id` INT NOT NULL AUTO_INCREMENTCOMMENT '数据库自增ID',`create_time` DATETIME NOT NULL DEFAULT '1970-01-01 00:00:01'COMMENT '数据创建时间',`modify_time` DATETIME NOT NULL DEFAULT '1970-01-01 00:00:01'COMMENT '数据修改时间',`community_id` INT NOT NULLCOMMENT 'fang_community的自增ID',# 基本信息`address` VARCHAR(128)COMMENT '小区地址',`area` VARCHAR(32)COMMENT '所属区域',`postcode` VARCHAR(8)COMMENT '邮编',`property_description` VARCHAR(32)COMMENT '产权描述',`property_category` VARCHAR(8)COMMENT '物业类别',`completion_time` VARCHAR(20)COMMENT '竣工时间',`building_type` VARCHAR(64)COMMENT '建筑类别',`building_area` VARCHAR(32)COMMENT '建筑面积',`floor_area` VARCHAR(32)COMMENT '占地面积',`current_number` VARCHAR(10)COMMENT '当期户数',`total_number` VARCHAR(10)COMMENT '总户数',`greening_rate` VARCHAR(10)COMMENT '绿化率',`plot_ratio` VARCHAR(10)COMMENT '容积率',`property_fee` VARCHAR(20)COMMENT '物业费',`property_office_telephone` VARCHAR(100)COMMENT '物业办公电话',`property_office_location` VARCHAR(40)COMMENT '物业办公地点',`additional_information` VARCHAR(32)COMMENT '附加信息',PRIMARY KEY (`id`),UNIQUE KEY (`community_id`)
)ENGINE = InnoDBDEFAULT CHARSET = utf8mb4COMMENT = '搜房网-小区详情首页-小区详情-原始数据';COMMIT;我先是爬取了所有的城市数据,虽然我们这次只关心杭州的情况,不过抓下来所有的城市,以后也用得到。打开网站我就去找Json数据API,发现并没有,所以只能采取普通的提取页面数据的方式来获取数据了。具体的代码如下:
"""
增量爬取
房天下-所有城市的主页
该爬虫,一般情况只需要爬取一次就够了:因为中国的城市变化,个人觉得是不频繁的
页面:http://www.fang.com/SoufunFamily.htm
"""from scrapy import Selector
from scrapy.spiders import Spiderfrom thor_crawl.spiders.spider_setting import DEFAULT_DB_ENV
from thor_crawl.utils.commonUtil import CommonUtil
from thor_crawl.utils.db.daoUtil import DaoUtilsclass CityIndex(Spider):name = 'sou_fang_city_index'handle_httpstatus_list = [204, 206, 404, 500]start_urls = ['http://www.fang.com/SoufunFamily.htm']def __init__(self, *args, **kwargs):super().__init__(*args, **kwargs)# ============ 工具 ============self.dao = DEFAULT_DB_ENVself.common_util = CommonUtil()# ============ 持久化相关变量定义 ============self.save_threshold = 20 # 一次性插入数据库阈值self.persistent_data = list() # 内存暂存处理的数据,批量插入数据库self.main_table = 'sou_fang_city_index' # 数据库存储表def __del__(self):self.save_final()def closed(self, res):self.save_final()def parse(self, response):try:body = response.body.decode('gb18030').encode('utf-8')except UnicodeDecodeError as e:print(e)body = response.bodyhxf = Selector(text=body)trs = hxf.xpath('//div[@id="c02"]/table/tr') # 获取所有的行数据this_province = '未知'for tr in trs[:-1]:province_name = self.common_util.get_extract(tr.xpath('td[2]/strong/text()')) # 获取省份名称文本值this_province = this_province if province_name is None or province_name == '' else province_name # 为空的话取之前的省份名称cities = tr.xpath('td[3]/a') # 获取所有的城市列表for city in cities:city_name = self.common_util.get_extract(city.xpath('text()')) # 获取城市名称文本值city_index_url = self.common_util.get_extract(city.xpath('@href')) # 获取城市首页链接self.persistent_data.append({'province_name': this_province,'city_name': city_name,'city_index_url': city_index_url})self.save()def save(self):if len(self.persistent_data) > self.save_threshold:try:self.dao.customizable_add_ignore_batch(self.main_table, self.persistent_data)except AttributeError as e:self.dao = DaoUtils()self.dao.customizable_add_ignore_batch(self.main_table, self.persistent_data)print('save except:', e)finally:self.persistent_data = list()def save_final(self):if len(self.persistent_data) > 0:try:self.dao.customizable_add_ignore_batch(self.main_table, self.persistent_data)except AttributeError as e:self.dao = DaoUtils()self.dao.customizable_add_ignore_batch(self.main_table, self.persistent_data)print('save_final except:', e)finally:self.persistent_data = list()然后是爬取杭州所有的出租房源数据,思路是通过杭州这个城市站的首页的“租房”菜单,进入房源列表,然后,根据不同的城区,去爬取数据,具体代码如下:
"""
搜房网-租房信息
"""
import reimport scrapy
from scrapy import Selector
from scrapy.spiders import Spiderfrom thor_crawl.spiders.spider_setting import DEFAULT_DB_ENV
from thor_crawl.utils.commonUtil import CommonUtil
from thor_crawl.utils.db.daoUtil import DaoUtilsclass Renting(Spider):name = 'sou_fang_renting'handle_httpstatus_list = [302, 204, 206, 404, 500]start_urls = ['http://www.souFang.com/SoufunFamily.htm']def __init__(self, *args, **kwargs):super().__init__(*args, **kwargs)# ============ 工具 ============self.dao = DEFAULT_DB_ENVself.common_util = CommonUtil()# ============ 持久化相关变量定义 ============self.save_threshold = 20 # 一次性插入数据库阈值self.persistent_data = list() # 内存暂存处理的数据,批量插入数据库self.main_table = 'sou_fang_renting' # 数据库存储表# ============ 业务 ============province_name = '浙江'city_name = '杭州'self.target = 'SELECT id, province_name, city_name, city_index_url ' \'FROM sou_fang_city_index ' \'WHERE province_name = "{province_name}" and city_name = "{city_name}"'.format(province_name=province_name, city_name=city_name)self.url_template = 'http://{city_code}.zu.fang.com/' # 租房首页的模板URLdef __del__(self):self.save_final()def start_requests(self):start_requests = list()for row in self.dao.get_all(self.target):if row['city_index_url'] != '':meta = {'city_index_id': row['id'],'province_name': row['province_name'],'city_name': row['city_name']}url = self.url_template.format(city_code=re.search(r'http://(.+)\.fang\.com', row['city_index_url']).group(1))start_requests.append(scrapy.FormRequest(url=url, method='GET', meta=meta))return start_requestsdef closed(self, res):self.save_final()# 拿到所有的地区,去掉"不限"def parse(self, response):try:body = response.body.decode('gb18030').encode('utf-8')except UnicodeDecodeError as e:print(e)body = response.bodymeta = response.metaurl = response.urlhxf = Selector(text=body)a_tag_list = hxf.xpath('//dl[@id="rentid_D04_01"]/dd/a')print('a_tag_list len: ', len(a_tag_list))if a_tag_list is None or len(a_tag_list) <= 1:print('------parse, no data in ', meta['province_name'], meta['city_name'])else:for a_tag in a_tag_list:meta['area_name'] = self.common_util.get_extract(a_tag.xpath('text()'))meta['area_url'] = self.common_util.get_extract(a_tag.xpath('@href'))meta['base_url'] = urlif meta['area_name'] is not None and meta['area_name'] != '' and meta['area_name'] != '不限':print(url + meta['area_url'])yield scrapy.FormRequest(url=url + meta['area_url'], method='GET', meta=meta, callback=self.parse_area)def parse_area(self, response):try:body = response.body.decode('gb18030').encode('utf-8')except UnicodeDecodeError as e:print(e)body = response.bodymeta = response.metaurl = response.urlhxf = Selector(text=body)dl_tag_list = hxf.xpath('//div[@class="2dff-9118-b734-1217 houseList"]/dl')print('dl_tag_list len: ', len(dl_tag_list))if dl_tag_list is None or len(dl_tag_list) <= 1:print('------parse_area, no data in ', meta['province_name'], meta['city_name'], meta['area_name'])else:for dl_tag in dl_tag_list:feature = ''feature_span_list = dl_tag.xpath('dd/p[5]/span')for feature_span in feature_span_list:feature += self.common_util.get_extract(feature_span.xpath('text()')) + ','feature = feature[:-1] if len(feature) > 1 else featureself.persistent_data.append({'city_index_id': meta['city_index_id'],'province_name': meta['province_name'],'city_name': meta['city_name'],'area_name': meta['area_name'],'detail_url': self.common_util.get_extract(dl_tag.xpath('dd/p[1]/a/@href')),'name': self.common_util.get_extract(dl_tag.xpath('dd/p[1]/a/text()')),'rent_way': self.common_util.get_extract(dl_tag.xpath('dd/p[2]/text()[1]')),'door_model': self.common_util.get_extract(dl_tag.xpath('dd/p[2]/text()[2]')),'area': self.common_util.get_extract(dl_tag.xpath('dd/p[2]/text()[3]')),'toward': self.common_util.get_extract(dl_tag.xpath('dd/p[2]/text()[4]')),'unit_price': self.common_util.get_extract(dl_tag.xpath('dd//span[@class="9118-b734-1217-963c price"]/text()')),'feature': feature})# 下一页page_a_list = hxf.xpath('//div[@class="b734-1217-963c-bfcf fanye"]/a')if len(page_a_list) > 0:for page_a in page_a_list:if self.common_util.get_extract(page_a.xpath('text()')) == '下一页':yield scrapy.FormRequest(url=meta['base_url'] + self.common_util.get_extract(page_a.xpath('@href')), method='GET', meta=meta, callback=self.parse_area)self.save()def save(self):if len(self.persistent_data) > self.save_threshold:try:self.dao.customizable_add_ignore_batch(self.main_table, self.persistent_data)except AttributeError as e:self.dao = DaoUtils()self.dao.customizable_add_ignore_batch(self.main_table, self.persistent_data)print('save except:', e)finally:self.persistent_data = list()def save_final(self):if len(self.persistent_data) > 0:try:self.dao.customizable_add_ignore_batch(self.main_table, self.persistent_data)except AttributeError as e:self.dao = DaoUtils()self.dao.customizable_add_ignore_batch(self.main_table, self.persistent_data)print('save_final except:', e)finally:self.persistent_data = list()最后是做统计的sql和代码:
SELECTarea_name,count(*) AS c
FROM sou_fang_renting
GROUP BY area_name
ORDER BY c DESC;"""
算算你再杭州的租房成本
"""from thor_crawl.utils.db.daoUtil import DaoUtils
from thor_crawl.utils.db.mysql.mySQLConfig import MySQLConfigclass RentInHz:def __init__(self, *args, **kwargs):# ============ 工具 ============self.dao = DaoUtils(**{'dbType': 'MySQL', 'config': MySQLConfig.localhost()})def calc(self):hz_data = self.dao.get_all('SELECT area_name, area, unit_price FROM sou_fang_renting')temp = dict()for row in hz_data:if row['area_name'] in temp:temp[row['area_name']].append(row)else:temp[row['area_name']] = list()temp[row['area_name']].append(row)result = list()for x, y in temp.items():total = 0num = 0for row in y:try:# print(float(row['unit_price']))# print(float(str(row['area']).replace('㎡', '')))total += float(row['unit_price']) / float(str(row['area']).replace('㎡', ''))num += 1except ValueError as e:print(e, x, row)result.append({'城市': x, '平均数': total / num})print(result)def feature(self):hz_data = self.dao.get_all('SELECT feature FROM sou_fang_renting')feature_list = list()for row in hz_data:if row['feature'] is not None and row['feature'] != '':for x in str(row['feature']).split(","):feature_list.append(x)temp = dict()for row in feature_list:if row in temp:temp[row] = temp[row] + 1else:temp[row] = 1print(temp)if __name__ == '__main__':tj = RentInHz()tj.feature()【我平时的开发环境和框架】
饭碗:Mac Pro 13寸
IDE: 、
JDK:8
打包:Maven 3
:2、3
爬虫框架:.3.3
欢迎围观《猫玛尼》