5、递归算法实现冒泡排序算法的函数MpSort
文章目录
1、分段函数1
本题目要求根据以下分段函数的定义,计算输入的x对应的y值,
输出结果保留两位小数;
如果输入的x是非数值型数据,输出'Input Error'。(注意:使用math库)
输入格式:
在一行中输入x的值。
输出格式:
按“f(x) = ”的格式输出,其中x与都保留两位小数,注意’='两边有空格。
如果输入的x是非数值型数据,输出:Input Error
import math
try:x=eval(input())if x>0:print("f({:.2f}) = {:.2f}".format(x,math.exp(x)+math.cos(x)))elif x<=0:print("f(-{:.2f}) = 0.00".format(abs(x)))
except NameError :print("Input Error")
``
2、分段函数2
本题目要求根据以下分段函数的定义,计算输入的x对应的y值,
输出结果保留两位小数; 如果输入的x是非数值型数据,输出'Input Error'。
输入格式:
在一行中输入x的值。
输出格式:
按“f(x) = ”的格式输出,其中x与都保留两位小数,注意’='两边有空格。
如果输入的x是非数值型数据,输出:Input Error
import math
try:x=eval(input())if x>0:print("f({:.2f}) = {:.2f}".format(x,math.log(x)+x**0.5))elif x<=0:print("f(-{:.2f}) = 0.00".format(abs(x)))
except NameError :print("Input Error")
3、分段函数3
本题目要求根据以下分段函数的定义,计算输入的浮点数x对应的y值,
输出结果保留两位小数。
输入格式:
在一行中输入x的值。
输出格式:
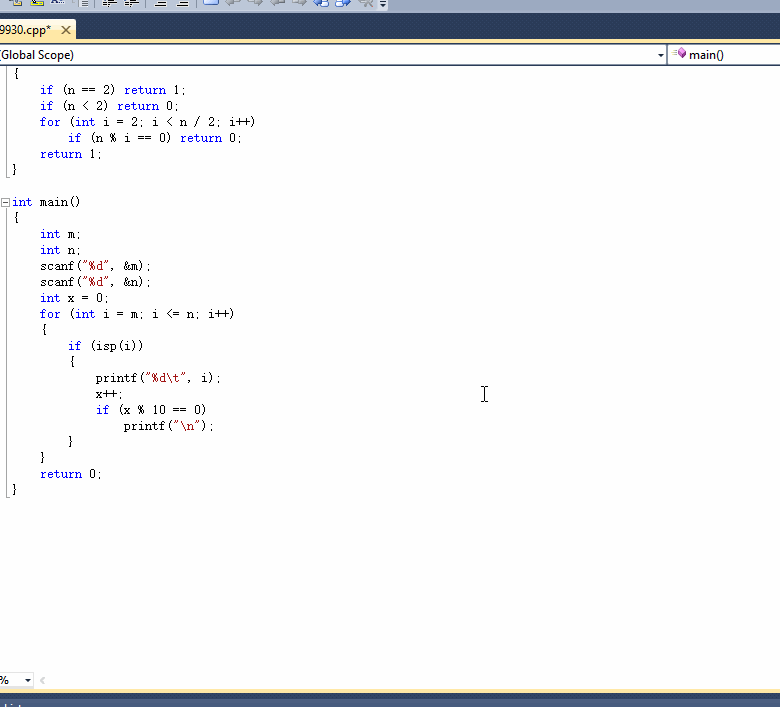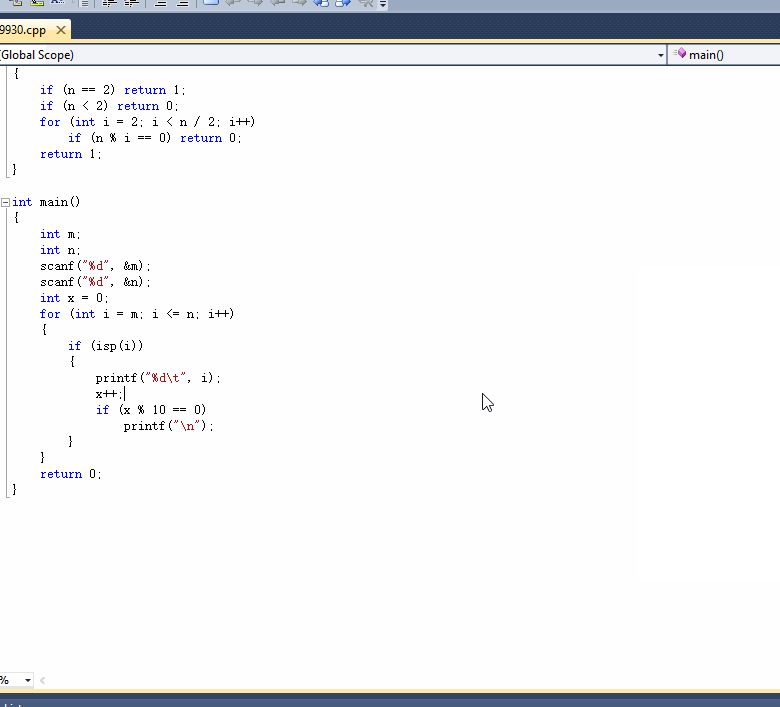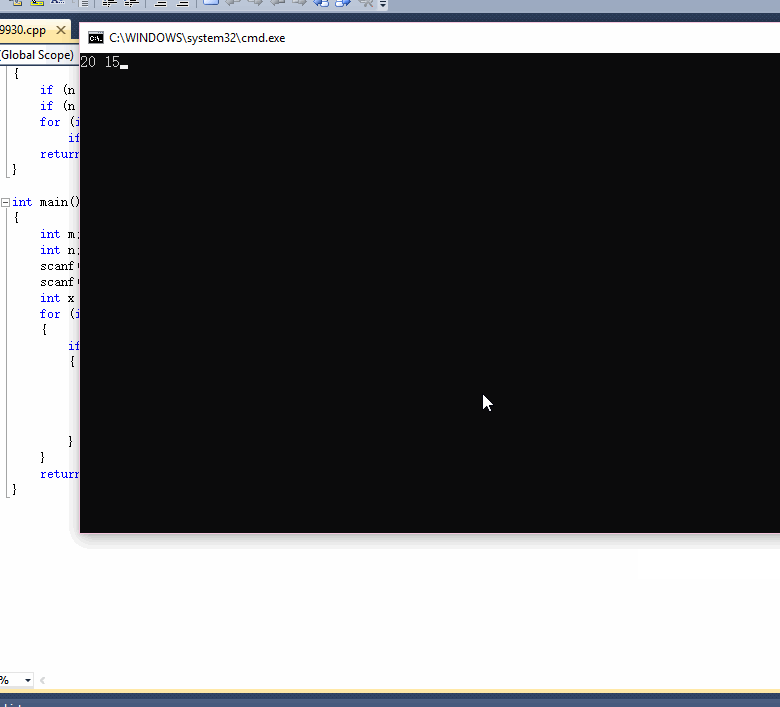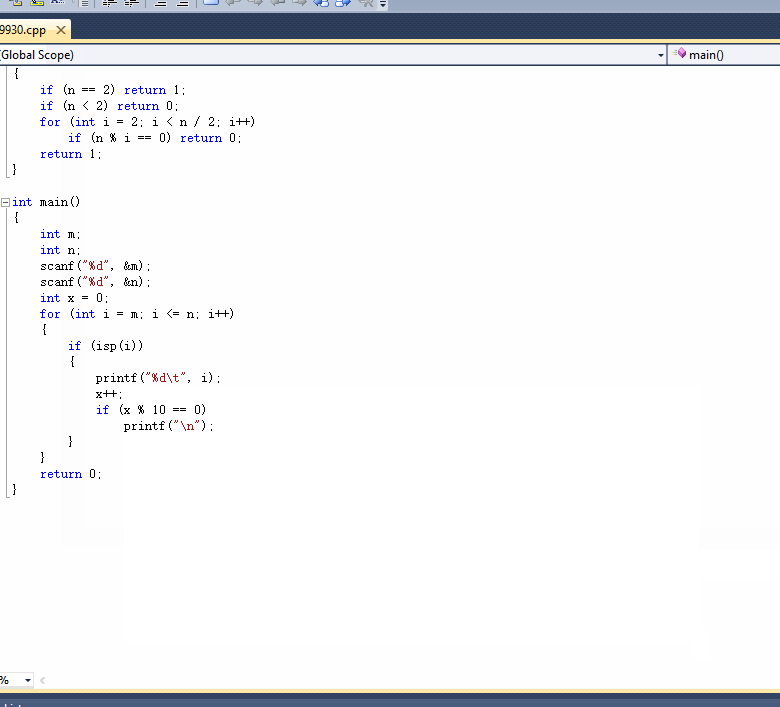
计算结果保留两位小数输出。
import math
try:x=eval(input())if x>3.5:y=math.cos(x)+math.exp(x)print("{:.2f}".format(y))if 0<x<=3.5:y=math.tan(x)+math.log(x+1)print("{:.2f}".format(y))if x<=0:y=0print("{:.2f}".format(y))
except NameError :print("Input Error")
4、分段函数4
本题目要求根据以下分段函数的定义,计算输入的浮点数x对应的y值,
输出结果保留两位小数。
输入格式:
在一行中输入x的值。
输出格式:
计算结果保留两位小数输出。
import math
try:x=eval(input())if x>=3:y=math.exp(x)+math.sqrt(x)print("{:.2f}".format(y))if 0<x<3:y=math.sin(x)+math.log2(x+1)print("{:.2f}".format(y))if x<=0:y=-1print("{:.2f}".format(y))
except NameError :print("Input Error")
5、递归算法实现冒泡排序算法的函数
定义一个函数MpSort实现对一组数据的从小大排序。编写程序,
实现读入若干个整数存入合适的数据结构类型的对象中。再调用MpSort函数,
对该对象中的元素进行排序后输出。
输入格式:
一组用空格隔开的整数。
输出格式:
排序好一组用空格隔开的的整数。例如:尾部带空格。
def MpSort(a):for i in range(0,len(a)-1):for j in range(i+1,len(a)):if(a[i]>a[j]):t=a[i]a[i]=a[j]a[j]=tfor i in range(0,len(a),1):print(a[i],end=' ')
a=list(map(int,input().split()))
MpSort(a)
6、判断两个字符串是否为变位词
如果一个字符串是 另一个字符串的重新排列组合,那么这两个字符串互为变位词。
比如,”heart”与”earth”互为变位 词,”Mary”与”arMy”也互为变位词。
输入格式:
第一行输入第一个字符串,第二行输入第二个字符串。
输出格式:
输出“yes”,表示是互换词,输出“no”,表示不是互换词。
word1=list(input())
word2=list(input())
count=0
for i in range(len(word1)):if word1.count(word1[i])==word2.count(word1[i]):count+=1
if count == len(word1):print("yes")
else:print("no")
7、求矩阵鞍点的个数
一个矩阵元素的“鞍点”是指该位置上的元素值在该行上最大、在该列上最小。
本题要求编写程序,求一个给定的n阶方阵的鞍点。
输入格式:
输入第一行给出一个正整数n(1≤n≤6)。随后n行,每行给出n个整数,其间以空格分隔。
输出格式:
鞍点的个数
n = int(input())
ls = []
c,d = [],[]
f = 0
for i in range(n):a = list(map(int,input().split()))ls.append(a)
for p in range(n):a = []b = []for q in range(n):a.append(ls[p][q])b.append(ls[q][p])x = max(a)c.append(x)y = min(b)d.append(y)
for i in c:for j in d:if i==j:f = f+1
print(f)8、求两个集合的差集
输入格式:
首先输入一个正整数T,表示测试数据的组数,然后是T组测试数据。每组测试数据输入1行,每行数据的开始是2个整数n(0 < n ≤ 100)和m(0 < m ≤ 100),分别表示集合A和集合B的元素个数,然后紧跟着n+m个元素,前面n个元素属于集合A,其余的属于集合B。每两个元素之间以一个空格分隔。
输出格式:
针对每组测试数据输出一行数据,表示集合A-B的结果,如果结果为空集合,则输出“NULL”(引号不必输出),否则从小到大输出结果,每两个元素之间以一个空格分隔。
T= int(input())
for i in range(T):lis = list(map(int, input().split()))lis1, lis2 = lis[2: 2 + lis[0]], lis[2 + lis[0]:]lis3 = []for i in lis1:if i not in lis2:lis3.append(int(i))lis3.sort()if len(lis3) != 0:for i in range(len(lis3) - 1):print(lis3[i], end=' ')print(lis3[len(lis3) - 1])else:print('NULL')
9、单词统计,并按顺序打印
输入一些英文单词,统计每个单词出现的次数(大小写,如‘At’和‘at’算不同的单词),
并按次数从多到少打印结果,如果次数一样就按单词的字典顺序打印(大写先于小写)。
输入格式:
在一行中输入一些英文单词,单词之间使用空格分隔,输入中没有数字和其他符号。
输出格式:
输出每个单词出现的次数,每行输出一个单词,以及对应的出现次数,中间用英文冒号分隔。
list=input().split()
d={word:list.count(word) for word in set(list)}
res=sorted(d.items(),key=lambda x:(-x[1],x[0]))
for item in res:print('{}:{}'.format(item[0],item[1]))10、查单词所在页码
输入一组单词在字典中的页码。而后得出多个单词在字典中的页码分别是多少。
输入格式:
首先输入的是一组单词及其在字典中的页码。其中,第一行一个整数 N,表示字典中一共有多少单词(N≤20000)。接下来每两行表示一个单词,其中: 两行中的第 1 行是一个长度≤100 的字符串,表示这个单词,全部字母小写,单词不会重复。两行中的第 2 行是一个整数,表示这个单词在字典中的页码。
接下来输入的是要查询页码的单词。其中的第一行是一个整数 M,表示要查的单词数(M≤10000)。 接下来 M 行,每行一个字符串,表示要查的单词,保证在字典中存在。
输出格式:
M 行,每行一个整数,表示第 i 个单词在字典中的页数。
n=int(input())
p=[]
for i in range(n):m=input().split()s=input().split()m.extend(s)p.append(m)
x=int(input())
for j in range(x):l=input()for k in range(len(p)):if p[k][0]==l:print(p[k][1])