【Objects as Points】
as
目录
在本文中,我们采取了不同的方法。我们将对象建模为单个点,即其边界框的中心点。我们的检测器使用关键点估计来找到中心点,并回归到所有其他对象的财产,例如大小、3D位置、方向、设置姿势。
我们的基于中心的方法是端到端可微的,比相应的基于边界框的检测器更简单、更快、更准确。
总之我们为对象提供了一种新的表示形式:点。
我们的对象检测器建立在成功的关键点估计网络之上,查找对象中心,并回归到它们的大小。
该算法简单、快捷、准确、端到端可微,无需任何NMS后处理。这个想法是通用的,并且在简单的二维检测之外有广泛的应用。
可以在一次向前传递中估计一些列额外的对象属性,如姿态、3D方向、深度和范围。
我们的初步实验令人鼓舞,并为实时目标识别和相关任务开辟了新的方向。
我们用边界框的中心的一个点来表示对象(图2)。
然后直接从中心位置的图像特征回归其他属性,例如对象大小、尺寸、3D范围、方向和姿态。
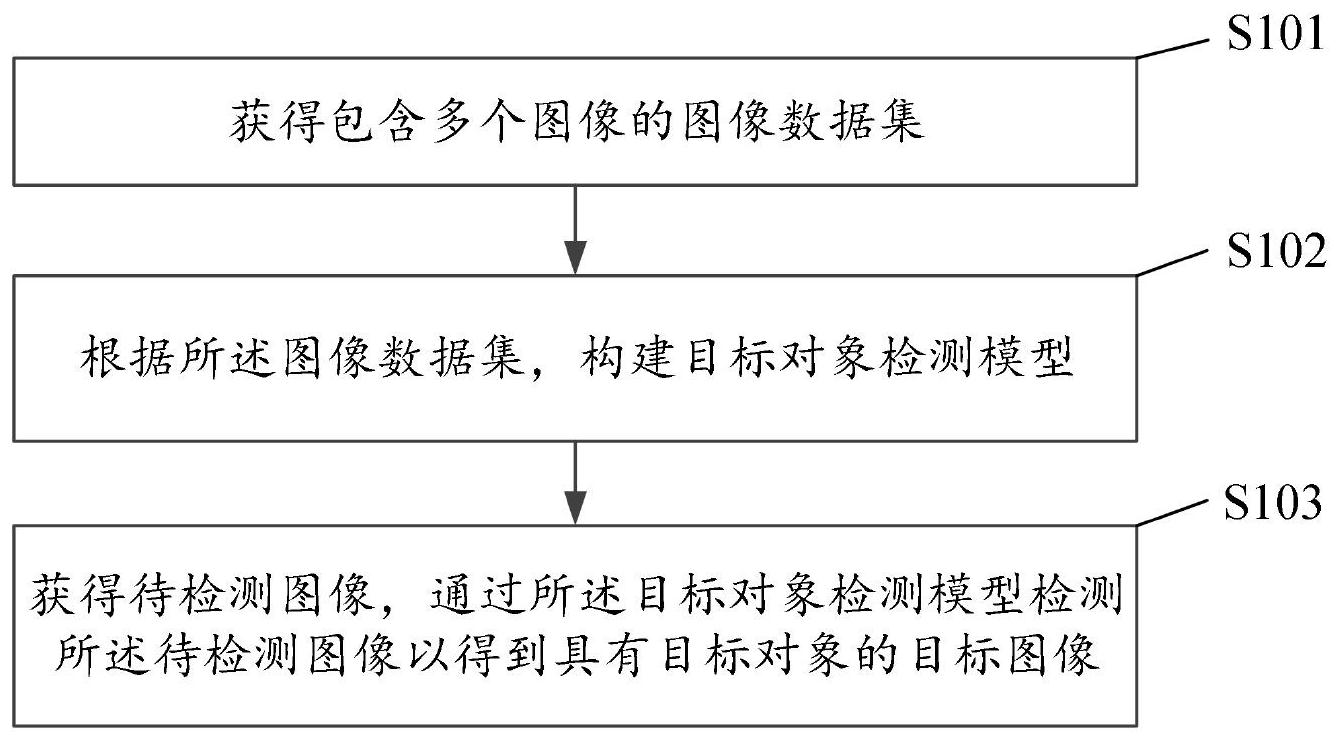
因此目标检测是一个标准的关键点估计问题。我们只需要将输入图像输入到一个全卷积网络,该网络生成热图。热图中的峰值对应物体的中心。每个峰值的图像特征预测物体边界框的高度和权重。该模型使用标准的密集监督学习进行训练。推理是一个单一的网络正向传递,没有用于后处理的非极大值抑制。
我们的方法是通用的,只需付出很小的努力就可以扩展到其他任务。
我们通过预测每个中心点的额外输出,提供了3D对象检测和多人人体姿态估计的实验。(见图4)
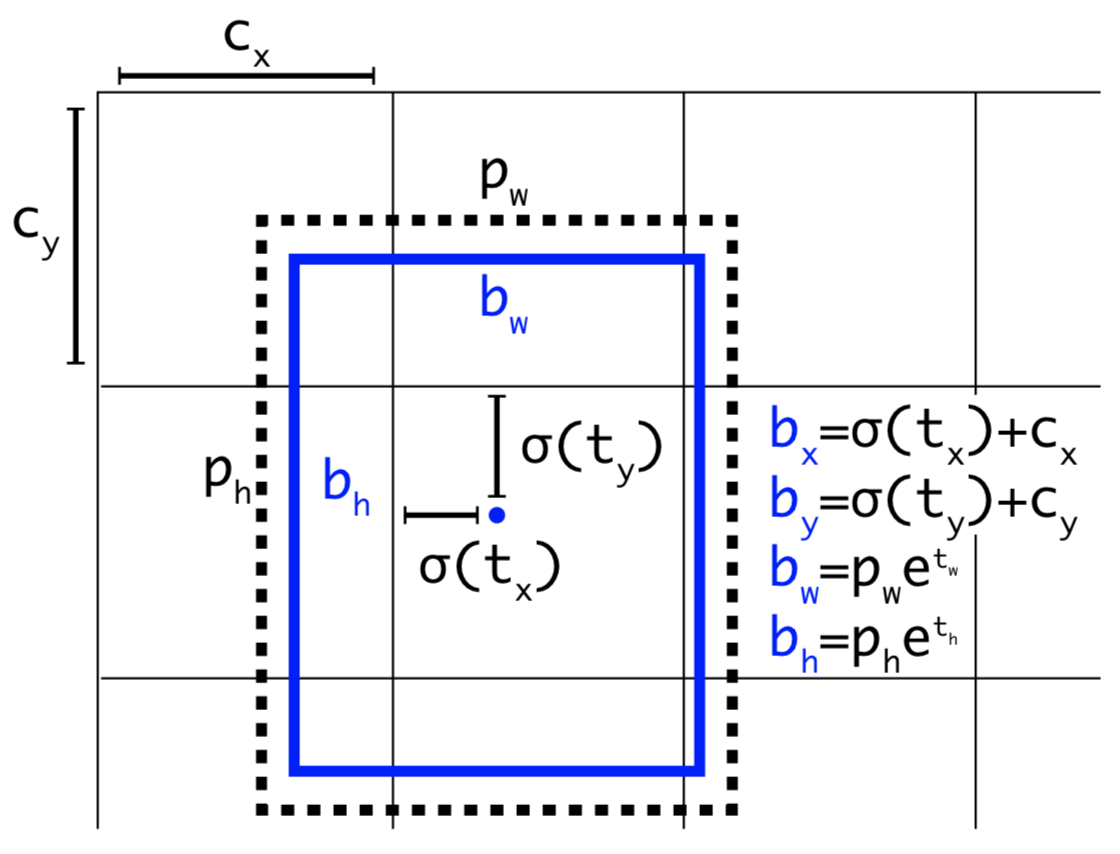
对于3D边界框估计,我们回归到对象绝对深度、3D边界框尺寸和对象方向。
对于人体姿态估计,我们将2D关节位置视为距中心的偏移,并在中心点位置直接回归他们。
work
我们的方法与基于的单阶段方法密切相关。一个中心点可以看作是一个单一的形状不可知的(图3)。但是也有一些重要的区别。首先,我们的仅根据位置而不是方框重叠来分配。我们没有用于前景和背景分类的手动阈值。其次,我们每个对象只有一个中心点,并不需要非极大值抑制。我们简单地提取关键点热图的局部峰值。第三,与传统的对象检测器相比,使用了更大的输出分辨率。这样就不需要多个。
我们不是第一个将关键点估计用于目标检测。检测两个边界框角作为关键点,而检测所有目标的顶部、左侧、底部、最右侧和中间点。这两种方法都建立在与我们的相同的鲁棒关键点估计网络上。然而,它们需要关键点检测后进行组合分组,这大大减慢了每个算法的速度。另一方面,我们的只是简单地提取每个对象的单个中心点,而不需要分组或后处理。
单目三维目标检测。3D box估计为自动驾驶提供动力。
as