KingbaseES V8R6集群运维案例之---sys_rewind应用分析
案例说明:
是用于在数据库的时间线分叉以后,同步一个 数据库 和同一数据库另一份拷贝的工具。一种典型的场景是在失效后让一个旧的主库重新上线,同时作为一个备库连接新的主库。
成功回放后,目标数据目录的状态类似于源数据目录的基本备份。与进行新的基本备份或使用rsync等工具不同,不需要比较或复制数据库中未更改的数据块。仅复制现有数据文件中更改的块;所有其他文件(包括新的数据文件、配置文件和WAL段)都将被完整复制。因此,当数据库很大并且数据库之间只有一小部分块不同时,倒带()操作比其他方法要快得多。
适用版本: V8R6
案例环境:
[kingbase@node101 bin]$ ./repmgr cluster showID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+---------+---------+-----------+----------+----------+----------+----------+----------------------------------------------------------------------------------------------------------------------------------------------------1 | node101 | primary | * running | | default | 100 | 27 | host=192.168.1.101 user=system dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=32 | node102 | standby | running | node101 | default | 100 |27 | host=192.168.1.102 user=system dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3一、主备集群切换“双主”故障
[kingbase@node102 bin]$ ./repmgr cluster showID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+---------+---------+-----------+----------+----------+----------+----------+----------------------------------------------------------------------------------------------------------------------------------------------------1 | node101 | primary | ! running | | default | 100 | 29 | host=192.168.1.101 user=system dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=32 | node102 | primary | * running | | default | 100 | 28 | host=192.168.1.102 user=system dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3=如上所示,在集群出现切换后,原备库切换为新主库;原主库被人为作为主库启动,导致集群出现“双主”的环境。=
二、双主故障的处理
1、如果原主库有新的数据写入,需通过业务数据判断,新主和原主那个节点上的业务数据最新,确定为主库。
2、可以通过读取控制文件,判断那个节点的事务最新(、、xid等),确定主库。
3、确定主库后,将另外的节点作为备库处理。
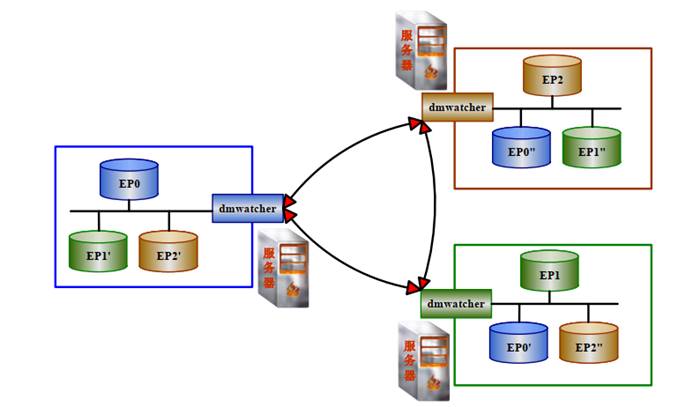
4、可以通过clone或方式将创建备库,加入到集群。
5、如果数据库数据量比较大,但新旧主库之间数据量变化差异比较小,可以考虑适用方式创建备库。
三、操作步骤1、关闭原主库(目标库)数据库服务。(如果有条件,可以先做一个备份)
[kingbase@node101 bin]$ ./sys_ctl stop -D /data/kingbase/r6ha/data/
waiting for server to shut down.... done
server stopped2、查看和配置相关配置参数
3、执行:
源 库: 新主库
目标库: 原主库(目标库的数据将被源库数据覆盖)
sys_rewind命令在目标库上执行,在执行sys_rewind之前需要关闭目标库数据库服务
(建议:关库后对数据库做物理冷备。)。[kingbase@node101 bin]$ ./sys_rewind --target-data /data/kingbase/r6ha/data--source-server='host=192.168.1.102 port=54321 user=system dbname=test' –debug4、执行过程分析
1) 读取目标和源库控制文件对比、等
datadir_source = /data/kingbase/r6ha/data
sys_rewind: fetched file "global/sys_control", length 8192
sys_rewind: fetched file "sys_wal/0000001C.history", length 11742) 读取目标和源库的文件寻找分叉点()

sys_rewind: Source timeline history:
sys_rewind: Target timeline history:
sys_rewind: 1: 0/0 - 0/690000A0
sys_rewind: 2: 0/690000A0 - 0/6A0000A0
.......
sys_rewind: 23: 3/320000A0 - 4/4B0000A0
sys_rewind: 24: 4/4B0000A0 - 4/4D0000A0
sys_rewind: 25: 4/4D0000A0 - 4/51001D00
sys_rewind: 26: 4/51001D00 - 4/520000A0
sys_rewind: 27: 4/520000A0 - 4/630000A0
sys_rewind: 29: 4/630000A0 - 0/0
sys_rewind: servers diverged at WAL location 4/540000A0 on timeline 27
sys_rewind: for record '27/4/54000028', remote hash is '0'
sys_rewind: for record '27/4/53000C20', local hash is '3038469505' and remote hash is '3038469505'
sys_rewind: rewinding from last common checkpoint at 4/53000C20 on timeline 27
sys_rewind: find last common checkpoint start time from 2022-09-13 14:18:54.005053 CST to 2022-09-13 14:18:54.123611 CST, in "0.118558" seconds.3)拷贝源库数据文件和变化的页块到目标库
sys_rewind: backup_label.old (COPY)
sys_rewind: base/1/1247_fsm (COPY)
sys_rewind: base/1/1247_vm (COPY)
.......
sys_rewind: received chunk for file "base/32955/189163", offset 4325376, size 32768
sys_rewind: received chunk for file "base/32955/189163", offset 4358144, size 32768
sys_rewind: received chunk for file "base/32955/189163", offset 4390912, size 32768
sys_rewind: received chunk for file "base/32955/2619", offset 262144, size 327684)应用后wal日志并更新目标库
sys_rewind: update the control file: minRecoveryPoint is '4/56E13200', minRecoveryPointTLI is '28', and database state is 'in archive recovery'
sys_rewind: we will remove the dir '/data/kingbase/r6ha/data/sys_replslot/repmgr_slot_2.rewind' and all the file/dir in it.
sys_rewind: rewind start wal location 4/53000BF0 (file 0000001B0000000400000053), end wal location 4/56E13200 (file 0000001C0000000400000056). time from 2022-09-13 14:18:54.005053 CST to 2022-09-13 14:19:05.426387 CST, in "11.421334" seconds.
sys_rewind: Done!三、将新备库(目标库)加入到集群
1、在目标库创建.文件[@ bin]$ touch /data//r6ha/data/.
2、启动目标库数据库服务[@ bin]$ ./ start -D /data//r6ha/data/
3、注册备库节点
[kingbase@node101 bin]$ ./repmgr standby register --force
INFO: connecting to local node "node101" (ID: 1)
DEBUG: connecting to: "user=system connect_timeout=10 dbname=esrep host=192.168.1.101 port=54321 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3 fallback_application_name=repmgr"
INFO: connecting to primary database
DEBUG: connecting to: "user=system connect_timeout=10 dbname=esrep host=192.168.1.102 port=54321 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3 fallback_application_name=repmgr"
DEBUG: remote_command():ssh -o Batchmode=yes -q -o ConnectTimeout=10 -o StrictHostKeyChecking=no -o ServerAliveInterval=2 -o ServerAliveCountMax=5 -p 22 192.168.1.102 /home/kingbase/cluster/R6HA/kha/kingbase/bin/kbha -A updateinfo
INFO: standby registration complete
NOTICE: standby node "node101" (ID: 1) successfully registered4、查看集群节点状态信息
[kingbase@node101 bin]$ ./repmgr cluster showID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+---------+---------+-----------+----------+----------+----------+----------+----------------------------------------------------------------------------------------------------------------------------------------------------1 | node101 | standby | running | node102 | default | 100 | 28 | host=192.168.1.101 user=system dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=32 | node102 | primary | * running | | default | 100 | 28 | host=192.168.1.102 user=system dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3---如上所示,集群节点恢复完成。四、总结
是主备流复制集群中一个工具,可以用于集群节点的恢复,在应用中注意,执行过程中,将源库变化的页块拷贝到目标库后,会应用分叉点之前最近的后的源库wal日志,如果wal日志缺失,将导致执行失败。执行失败后,目标将无法启动,执行前做好备份。