Adaptive Photographic Composition Guidan
自适应摄影构图指导 介绍相关工作相机内指导 构图指导 自适应电枢 研究设计迭代 第二次试点研究(4个条件) 形成性研究(没有指导和静态线) 总结评估和讨论 局限性和未来的工作结论附上自己的实现
摘要
摄影构图常通过贴合构图网格来实现,最常用的是三分法则。专业的摄影师使用更复杂的网格,比如谐波电枢(b站讲解)去实现一些多样化的动态构图。作者对这些复杂的网格对业余爱好者是否有帮助很感兴趣。
给出结论: 在一个形成性研究中,作者发现覆盖了谐波电枢网格的相机可以帮助经验不足的摄影师发现并完成不同的构图。但是太多的线让人会感到困惑。摄影师实际上只使用了这些线的子集。源于目前谐波电枢存在的复杂度高、不自适应的缺点,作者一行人希望将经验得出的心理模型转换为自适应拍摄当前风景的高亮线条,具体来说就是设计了基于显著性的算法来显示这些线条并评估了这个模型,证明该模型对更好地构图有帮助。
关键词
摄影;相机界面;构图;动态对称
CCS
计算摄影
介绍
图2给出了本文主要使用的三种谐波电枢,蓝色为倒数对角线,橘色为主对角线。a是宽高比大于根号2,根据比例设计,对角线始终连接到中心,从而在四分之三和四分之一处形成水平/垂直线;b是宽高比在根号2与1之间,此时倒数对角线垂直于主对角线;c即正方形;d不使用线条。
目前构建的网格(如黄金分割、三分法等)基于这样的假设:将重要的视觉元素沿其线和相交位置对齐将生成更具视觉吸引力的图像。
强调了目前的基于实践发现的拍摄元素与构图的关系常由摄影师动态选择,这是一个脱机的过程,需要摄影师手动注释。
讲述团队工作:1、创建可以自动辨别基于图片显著度的自适应电枢(框架)的算法。2、创建交互式相机内应用,可以作为构图指导给用户展示这些自适应电枢。3、进行用户评测。
其他贡献:1、众包构图注解的数据集,这些注解捕获了人们认为在谐波电枢网格的约束范围内与图像合成最相关的线的常识。2、用户评估比较了静态构图指南与无指南的使用情况,这表明参与者对构图能力更加自信并且使用该指南感到更有创造力。
相关工作
构图分析,此前工作仅关注于影响图片构图的低级图像组件。Zhou等人:估计消失点,并使用它们来检索相似的图像。Lee等人:检测主要的几何元素,并使用卷积神经网络对室外场景中的摄影构图规则进行分类。He等人:查找并突出显示图像上的三角形以创建构图意识并促进创造力。还有其他工作对图像进行分类以检索相似的高质量示例以获取灵感。作者专注于相对于构图网格的显着特征的放置,而不是特定的图像组件或构图类型。
构图增强,已有许多图片重构方法,裁剪仍然是改善构图最直接的方法。目前有人关注显式注意力模型和美学模型,但最流行的仍然是从专业摄影师或用户注释的样本中学习,虽然该方法的性能受基准测试的数据集而异,往往适用于自动化工作流程。作者并非寻找最优剪裁,而是希望在捕获(更好的裁剪)过程中,通过改变他们的观念来帮助用户积极地获取好的构图。
拍摄时间指导。现代相机有一些视觉辅助工具,比如用于曝光不足/过度的斑马图案、直方图、聚焦峰值、水平或静态构图网格。作者关注于构图指导,该指导可以提供用户对不同创造选项的认识,同时为用户提供一个心理模型。 这些界面为构建心理模型提供有限的反馈。
与作者的工作相似的是Xu等人的三相机系统,该系统可以实现实时指导反馈,所以可以使用三线法学习更好的构图,他们设计了感兴趣区域和三分法网格之间的对齐方式并显示了箭头供用户遵循以改善构图。而作者在关注肖像的构图并使用构图网格之外,还希望可以减少用户体验的局限性。即不使用箭头,而是使用自适应电枢来突出显示可能有趣的构图,使指南更加智能。当元素位置为一定的空间关系时,会为用户突出显示这种关系。
相机内指导
作者首先提出了几个问题:人们是否对相机内指导感兴趣?如果是那么指导工具应该如何工作?更特别的,构图对于机内指导是否是一个好的概念?
摄影实践调查
进行了摄影实践调查,以了解人们是否需要相机内的指导,如果需要,哪种反馈对他们的摄影实践会有帮助。共调查了127位具有一定摄影经验的参与者。作者在尝试提供基于上下文的相机内指导方向上看到了好处,可以使用户在拍摄过程中做出更好的创意决定。
此外还发现人们担心摄影时使用拍摄时间指导会分散注意力。因此,指导应该优先考虑尽量减少分心,多提供建议,而不是坚持具体的艺术选择。
最终总结调查者关于摄影改进的反馈,发现构图是重要的考虑因素,提供构图指导对减少大幅修改有效果。在调查受访者中,有89%的人愿意花费多达5秒的时间进行捕获时间指导,以获得高质量的结果。
有经验的摄影师采访
作者还对九位有经验的摄影师进行了采访,为了深入了解在摄影是什么样的指导是有帮助的。
六位摄影师表示经常使用覆盖物,聚焦点、合成网格等等,他们接受一定的视野被遮挡。
一般来说,这些经验丰富的摄影师也乐于接受任何反馈意见,以便在将来剪辑时有更多的选择。
一些人认为可以在使用指导的同时保持创造性,打破规则,遵循自己的直觉。
摄影师们也叙述了一个寻找好的构图的过程,以及预合成和等待拍摄的过程。
从采访中了解到,有经验的摄影师也会在给鼓励新的尝试中受益,有时他们需要立即捕捉一个镜头,有时愿意花费更多的时间投入到获取更高质量图像的工具上,作者希望做到这两种情况,且适用于新手和专家。
相机内指导的设计目标
1、上下文感知。视觉引导应与当前的图像相适应,并覆盖在取景器上。
2、最低限度的干扰。应易被忽略。
3、支持探索和改进。应该可以帮助摄影师发现新的想法以实现现有的意图。
构图指导
作者倾向于使用一个更通用的网格,即谐波电枢,允许更多的成分多样性谐波电枢提供不同的正交和对角线,对角线常用于动态对称,在交叉点处延伸出三分法则和黄金比例网格。
作者希望可以在摄像机内实时提供线条与图像之间关系的反馈,问题是有经验的摄影师经过训练后能否形成一致的观点,即哪些线条是相关的。
有经验的摄影师注释。
为了研究有经验的摄影师是否对线条描述的构图有一致的看法,让参与者对图片进行了注释,分为两个部分。第一部分对每个图像自由画一组线条,第二部分是在谐波电枢的叠加下,显示相同的图像,这次从谐波电枢中选择线条。共对5张给定和5-6张自带的照片进行了注释。
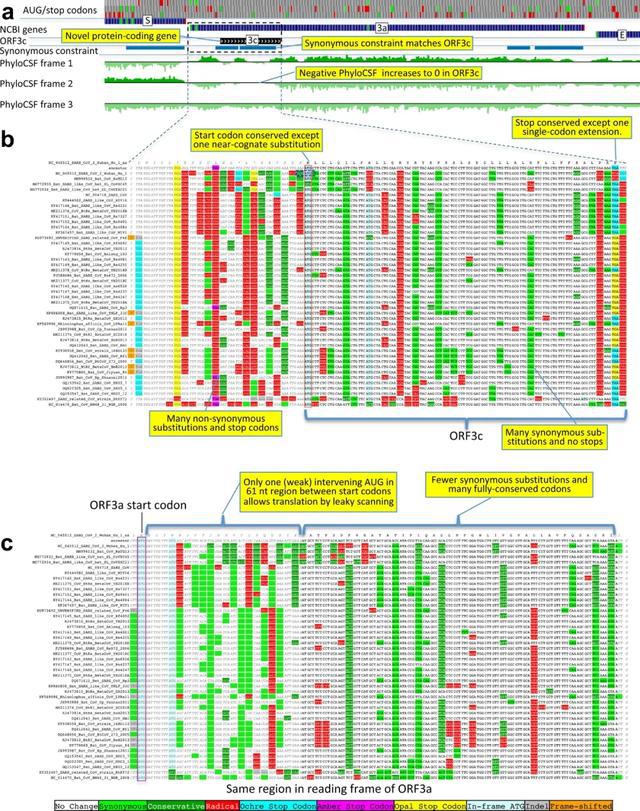
结果显示,有经验的摄影师能够识别图像构图中的线条,无论是哪种方式。考虑到合成网格的限制,他们也会选择特征不完全对齐的线条来近似地表示这些特征。在图3中可以看出,对于具有显著不同元素的图像,参与者经常在这些元素之间画线,以突出元素的排列。
许多参与者发现注释是有用的,并且享受辨别混合构图网格中的线,这会使它们调整自己的图像去符合这些线。对于摄影转接也是一样的,这会改变它们的视角以影响拍摄。
Turk注释
Turk是请求方发布人工智能任务 (HIT) 的论坛。作者希望知道新手是否可以使用同样的心理模型(构图网格到给定图像的相关线对齐),此外希望能获取更多的注释,并从中找出一致性,为构图提供一组“最相关”的线条。所以作者在 Turk上众包注释。
作者构建了一个500张图片的数据集,从-25000张图片中选出最具美感的前500张,并替换了极端长宽比和内容不恰当的图片。
在任务中,为每一个用户随机展示10张图片,并让他们从合成网格中选择1-4条最能描述物理元素构成的线。

并且前两个注释将作为验证集,来移除粗心的注释,所有工作人员需标注12个图像,4分钟,每个任务1美元,匹配15美元每小时的最低工资。
作者共收集了1004个注释任务,共11961个非验证集的图片注释,平均每张图片22个注释。从这些注释中,我们过滤掉了工作人员不能使两个验证任务正确的任务反馈,即在样例中没有选择提供的线。最终得到9133张图片的注释,平均每张图片17个注释。
目的是为每幅图像选取一组最相关的构图线作为 truth。做法是,对给定的图片定义每条线的分数为包含该线的工人注释的百分比。对最初的一批注释可以确定一个0.4的分数阈值,即是否应该选择一条线作为 truth之一,这导致选择作为 truth的线数目接近每个注释中选择的平均线数。有10幅图没有 truth,所以最终的数据集为8966个图像注释,每个图像的 truth平均数量是1.82,每个图像的注释的线的平均数量是2.17。
基本的 truth注释中的平均行数与初始注释的行数非常接近,意味着大多数行都达到了这个分数阈值。另外,只有10张图没有超过阈值的线条。这表明,在给定图像的合成网格中,什么是“最相关”的线的概念是一致的,新手也可以感知并注释这种关系。此外,还有一个可选的文本框用于反馈,很多员工表明他们觉得任务有趣,可以提高他们的摄影技巧。
注释观点
总结:
1、执行注释是很有用的。无论是专业的摄影师(new idea)还是新手摄影师(帮助理解构图),都对注释感兴趣。
2、注释易于理解。都可以依据合理的一致性注释来完成摄影任务。
故作者决定选择这条路来指导相机构图。
自适应电枢
自动检测一组相关的线条,以便在相机中给出这些注释,称这种方法为自适应电枢。
启发式算法
构图可以被认为是将图像中视觉上重要的元素与构图网格的线/交点对齐,作者用显著性来表示这种视觉上的重要性。所以自适应电枢捕获与显著性最匹配的线集。同样采用对候选线评分的做法,分数越高图像中视觉重要性高的元素就越好与该线对齐,并且它们与图像的构成越相关。
对于给定的图像,使用苹果内置的beta 库计算基于注意力的显著性图,这张图就用来投票电枢中的线的分数。对于显著性值为S的显著性图中的每个点p,其结构线L的分数贡献为该公式:
对于一个高斯核,其大小为图片长维的1/10,sigma为核大小的1/4,每条线的分数按照该线的长度进行标准化。最终选了得分前三的线作为启发式的注解/自适应电枢。
注:高斯核函数
移动实现
移动实现:作者的应用运行在IOS13.0公测版的上运行,其中显著性和自适应注释在当前相机图像的背后不断计算。该应用有一个快门按键,拍摄时会将屏幕刷成白色,除了构图没有其他相机功能。为减少计算时间,预先计算每条线的高斯映射并存成图像。每条线的分数可以通过简单地将显著性图像乘以相应的预先计算的高斯映射并计算总和来得到。为了实现视觉更新并不分散注意力,采取0.1秒的间隔来计算线的分数。
评估启发式结果
对每幅图像,计算出启发式注释与 truth相交处的平均线数除以这两种直线合并的线数。这个指标的平均值为0.38。作为参考,随机抽样10000条注释,平均值为0.11。这个指标对于单独的工作人员的注释相比于 truth线的值为0.47。这个值是合理的也是被期望的。
研究设计迭代
作者构建了两个小规模试点研究和一个形成性用户研究,作为一个迭代设计的过程的一部分。
图5:自适应构图指导的迭代过程。第一幅为初步试验,即仅显示自适应选定线,每0.1秒更新一次。第二幅为辅助参考,即以0.3的不透明度显示未选择的线,上方滑块允许用户调整更新速度(默认0.5s)。第三幅和第四幅为总结,在反复研究实验后,顶部切换在高级模式和基本模式(不选择斜线)之间,有底部的按钮可以选择打开或关闭构图可视化。
这些研究帮助解决了一些关于相机内构图指导工具的不同潜在交互条件的问题,并为随后的总结性用户研究改进了界面。
初步研究
初步研究:没有指导和自适应的线的情况下进行了一个初步研究(n=3),以评估初步研究设计在两各个不同界面条件(首先是没有指导,然后是由自适应构图指导)下的区别。
主要步骤:参与者会得到一张纸,上面描述了一些基本的构图指导线,以保证他们对于如何思考构图有一个基础观念。但是实验者与纸上都告诉他们不需要参照这些指南。他们被要求完成6个摄影任务,重点在构图。前两个参与者做了相同的三个任务两次,每次用一种工具。最后的人做6个不同的任务每个工具用三次。每个任务完成后,作者会对他们进行调查,询问他们一些与经验相关的李克特问题(在7分的范围内),并衡量他们的创造力支持指数(CSI)(0-100)。最后,他们会选择每个任务最喜欢的图片,并对他们的构图进行评级,并回答了是否喜欢这个工具,以及如何影响他们的摄影。
初步试点研究界面
无指导界面只有一个用于拍照的按钮,没有其他界面元素。自适应界面还动态显示了3条自适应电枢线。仅在选择了某条线时,该线才可见,其他是半透明的。
初步试点研究结果
重复执行相同的拍摄会产生学习效果,因此参与者第二次已经探索了选择的空间,并且知道了想要拍摄的照片的构图。他们最终使用作者的工具是为了重新确定他们已经想到的镜头。对于第三个试点,选择了第二个地点,并根据规模和环境在两个地点设计了三个任务。如图6。
图6:两个研究位置的相应照片任务。在主题和复杂性上相似,并且规模越来越大,从表面上的小物体,到桌子/椅子结构,再到建筑物的外墙。
存在的问题:辅助线出现和消失的太快了,使他们无法快速反应。作者进行了调整,即在上方添加了一个滑块,允许用户将更新速度进行调整,默认值0.5在移动较慢时感觉比较慢。
此外,参与者表示,适应性突出显示帮助他们提出了他们以前不会想到的想法。这可能是由于多种因素导致的,即在相机视图上看到了各种重叠的线条,或者线条的自适应性质。因此,作者决定尝试另外两个条件:显示静态的合成网格,以及随机选择的线以突出显示,而不是通过启发式算法选择的线。
第二次试点研究(4个条件)
作者接下来进行了另一个试点研究(n = 6),这次测试了所有4个条件:无指导,静态构图指导,随机自适应构图指导和启发式自适应构图指导。
主要步骤: 前提一样,提供一张纸,描述基本的构图准则,但不必遵循。这次使用了4个不同的位置,每个位置有3个可比较任务(小/中/大)。所有参与者都看到没有指导的工具、静态指导的工具、一半算法自适应指导和一半随机自适应指导。手动将位置平衡。没有进行中间调查,在最后进行访谈。
第二次试点研究界面
无指导界面只有一个拍摄按钮。静态构图指导以覆盖相机视图的0.3的不透明度显示了整个构图网络。自适应界面还可以动态显示叠加在摄像机视图上的注释的3条线,这些线经过随机或算法选择的。此外,自适应界面还为用户提供了一个滑块控件,调节更新速度。
第二次试点研究结果
一些参与者无法区分随机和启发式自适应指导的区别,但是可以区分的人表示随机的指导会分散注意力并且难以忽略。第二个人认为它不可用,第一个人说这个工具会降低信任度,虽然可以激发更多的创意,但是随机选择并不推荐。除此之外,两位参与者表示,构图网络太复杂,尤其是不会使用对角线。一些人表示使用更好的自适应标记算法构建的心理模型可以使他们更好地使用该工具。
形成性研究(没有指导和静态线)
第二次试点帮助作者消除了随机标记条件,最终只需考虑三个条件:无指导、静态辅助线和作者的自适应构图指导。该研究在两个实验条件下进行,即无指导和静态构图指导,以了解静态构图指导对用户摄影的影响。
主要步骤: 作者招募了12位参与者进行该研究,5位新手摄影师,4位业余爱好者和3位中级摄影师。所有参与者去了两个地点,完成6个摄影任务。在条件允许的情况下,所有人的任务相同。每项任务都提供了有关图像主题的具体说明,并限制了参与者在摄影对象周围的移动空间。实验人员将参与者带到每个任务的相同起始位置,并以相同顺序完成。
类似地,向参与者提供纸,告知任务,参与调查并选出照片并评价CSI。最终他们会选出自己喜欢的照片并对其构图进行打分(1-7)。最终接受访谈。

形式性研究界面
无指导界面只有一个摄影按钮。 静态构图指导还以覆盖相机视图的0.3不透明度显示了整个构图网格。
形式性研究结果
虽然静态构图指导并不能改善用户对图片构图的意见,但是可以使参与者对自己的构图能力更加自信。静态指导比无指导有更高的CSI,说明它为创造力提供了更好的支持。但问题同样是网格太复杂了。
总结评估和讨论
通过对静态构图指导的好处的见解,作者想知道自适应电枢的动态特性如何会类似地或不同地影响参与者构图和拍摄照片。
图7:一些来自汇总用户研究的参与者拍摄照片。这些图片显示了参与者在做任务时看到的覆盖网格。上面是静态指导,下面是自适应指导。参与者经常发现网格线与图像中的元素或边缘对齐,但有时也使用它们放宽图像的宽松准则、将图像分为多个区域(例如,三分之二),甚至不理会网格线。
表1:各项研究的CSI细分(总分1-100,各项0-20)。根据成对比较,因素按照重要性的顺序(及两项研究的顺序)排序。
总结性研究(静态和自适应线)
招募了另外24位参与者,2位为新手摄影师,16位为业余爱好者,6位是中级摄影师。采用两个实验条件:静态构图指导和启发式自适应构图指导。
主要步骤: 过程与形成性研究相似,但是添加了应用程序的简短教程,描述了界面元素并揭示了构图网格中的比例,并展示了更多使用辅助线的示例(比如三分法则)。此外作者还写了一篇教程去解释自适应算法。这些都在自适应构图网格之前提供给参与者。
总结性研究界面
在最终工具中,为进一步解决构图网格的复杂性,静态和自适应界面都有切换功能。可以在基本(中心和三分法则)和高级(全电枢)之间切换,并设置打开和关闭线的按钮。其他同之前。
总结性研究结果
与使用静态构图指导相比,使用自适应构图指导的用户认为他们的照片构图更好。尤其是对任务3有效,因为建筑物中自然存在很多的线条。参与者被问到何时使用时,也说在拍摄景观、建筑及多个物体时会使用。
虽然没有看到自适应指导在CSI上与静态指导有显著差异,但是很多参与者认为该指导使他们产生了更多的想法,激励他们去探索,因此更具有创造力。
少数人认为网格使他们更专注于对齐而非创意。
参与者使用该工具对构图更有信心。
无指导和自适应线的比较
作者的总结性研究并没有直接比较无指导和自适应指导。所以这里的结果是将总结性研究的适应性界面结果与形成性研究的无指导性结果进行了比较。要注意的是,这些结果只能暗示我们在不同人群之间进行比较时的相关性,而这两个人群都没有同时看到这两种情况。在这里,作者发现了与静态成分指导相似的结果,而形成性研究没有提供指导。
自适应指导提高了参与者对构图照片的信心,与没有指导相比,适应性指导还具有较高的CSI,并且具有相同的创造力因素,也大大改善了:探索,值得努力的结果和享受(见表1)。
用户情景
作者发现了使用静态和自适应指导的一些常用方式,这里给出了两种用户情景。
在旅行中,一个用户想要拍摄艺术照。她打开相机中的工具并浏览风景为了获取更有意思的构图。
静态情景:用户在扫描空间时会检查所有网格线。她最终注意到两条垂直的三分之二线与结构的各个部分非常吻合,因此决定尝试这种想法。她稍微调整摄像机,以将前景对象放置在右下三分之二的交点处。她水平/垂直移动相机,将对象放置在不同的交点以测试一些构图。她选择了一个,保持垂直对齐,然后拍照。她抓住了这个想法,并继续在空间中寻找不同的想法。自适应情景:用户在扫描空间时遵循突出显示的网格线。垂直的三分之二的线条亮起,与结构的各个部分很好地对齐,她决定尝试这种想法。在调整摄像头以将前景对象放置在右下三分之二的交点时,她会注意到一条不同的线高光。拍照后捕捉她当前的想法后,她决定尝试与这条新突出显示的线对齐,并拍摄另一张照片。同样,新行突出显示,使她注意到与以前从未见过的结构保持一致,这给了她另一个想法。 局限性和未来的工作
1、启发式算法。 到目前为止,作者已经基于(仅基于)显着区域的构图指导思想构建系统。由于构图的最终目标是实现某种视觉平衡(或缺乏视觉平衡),因此考虑其他高级提示会很有趣。 作者探索了在算法中使用边缘检测的方法,但这并没有提高一致性,也使得对结果的理解更加困难。因此,作者选择为参与者选择一个更简单的心理模型,以便更好地研究本文的交互作用。由于在实验中观察到参与者在许多情况下都与边缘对齐,因此作者有兴趣在将来的迭代中进一步追求这一方向。
2、界面定制。参与者表示有兴趣对构图网格线的集合进行更多控制。例如,有人提到要表达个人的风格偏好,而有人提到设置特定的模板覆盖图来约束或匹配给定的构图。通过交互选择线或使用当前的启发式方法自动从图像中提取模板,可以轻松集成此功能。这些建议加强了这种心理模型的实用性,并增强了它作为一种互动工具的参与度。
3、其他应用程序。除了相机内的指导外,自适应构图线可能对交互式裁剪工具很有用。同样,适当的显着性模型与其他网格系统结合可以在图形设计工具中提供类似的体验。感兴趣的其他领域包括基于构图的图像检索以及图像的其他在感知上有意义的分析。
结论
构图是摄影中的重要部分,学习构图可以使用使用构图网格。许多相机提供范围内的构图网格的覆盖,然而对于构图网格是否适应一个易获取和掌握的心理模型仍然缺乏支撑。作者发现,新手在注释他们相对于此类网格的构图方面相对一致。 作者还发现,在相机上进行此类指导可以帮助用户感到更加自信和创意。
作者探索一种新型的围绕自适应电枢的构图指导,并发现自适应电枢可支持用户探索新的构图思想以及在拍摄时重新构图,从而帮助他们制作他们认为构图更好的照片。
附上自己的实现 cv2显著性检测
import cv2def make_saliency(path):# load the input imageimage = cv2.imread(path)# initialize OpenCV's static fine grained saliency detector and# compute the saliency mapsaliency = cv2.saliency.StaticSaliencyFineGrained_create()(success, saliencyMap) = saliency.computeSaliency(image)saliencyMap = (saliencyMap * 255).astype("uint8")# if we would like a *binary* map that we could process for contours,# compute convex hull's, extract bounding boxes, etc., we can# additionally threshold the saliency map# threshMap = cv2.threshold(saliencyMap, 0, 255,# cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]# show the images# cv2.imshow("Image", image)# cv2.imshow("Output", saliencyMap)# cv2.imshow("Thresh", threshMap)# cv2.waitKey(0)cv2.imwrite('saliency_out.jpg',saliencyMap)
主py文件引用及变量定义
import make_saliency
from skimage import io
from PIL import Image, ImageDraw
import cv2
import heapqcomposition_imgs = [] # 存储构图线图像
lengths = [] # 存储构图线长度
composition_outs = [] # 存储高斯处理后的构图线图像
multiplication_results = [] # 存储乘法后的图像
scores = [] # 存储最终计算分数
top3_lines = [] # 存储最终top3的构图线序号
读入显著性图像函数
def read_saliency():global saliency_img # 存储显著性检测的图片saliency_img = io.imread('saliency_out.jpg')
读入14张构图线图像函数
def read_composition(path):with open(path, encoding='utf-8') as f:for l in f:l = l.strip()if l:# 按照txt中的路径读取图片img = io.imread(l)length = 0rows, cols = img.shape# 处理构图将128像素点转为255for i in range(rows):for j in range(cols):if (img[i, j] > 0):length += 1img[i, j] = 255composition_imgs.append(img)lengths.append(length)# print(img)# print(length)print(composition_imgs)print(lengths)
高斯处理14张构图线图像
def gaussian_all(width):for img in composition_imgs:out = cv2.GaussianBlur(img, (int(int(width)/10-1), int(int(width)/10-1)), int(int(width)/40))composition_outs.append(out)print(composition_outs)
乘法处理
def multiply():for out in composition_outs:result = out * saliency_imgmultiplication_results.append(result)# print(multiplication_results)
计算分数
def calculate_scores():flag = 0for result in multiplication_results:sum = 0rows, cols = result.shapefor i in range(rows):for j in range(cols):if (result[i, j] > 0):sum += result[i, j]score = sum / lengths[flag]flag += 1# print(sum)# print(score)scores.append(score)# print(scores)
输出top3构图线
def print_top3():max_num_index_list = map(scores.index, heapq.nlargest(3, scores))for l in list(max_num_index_list):top3_lines.append(l + 1)print('得出分数为前三的构图线:', top3_lines)
依据本人理解的简单实现,需定义图像大小后执行算法,供交流。