爬取豆瓣Top250图书【Beautiful】
由于我有一个喜欢看书的室友,最近比较闹书荒,我想着爬取一下豆瓣评分的图书,看看他有没有想看的,我是本着学习的态度加双赢的结果(并不是为了装那啥。。。
爬取目标
+ 爬取豆瓣评分的图书
+ 获取每本图书的详细信息
+ 把爬取结果存入Excel中
0、爬取效果
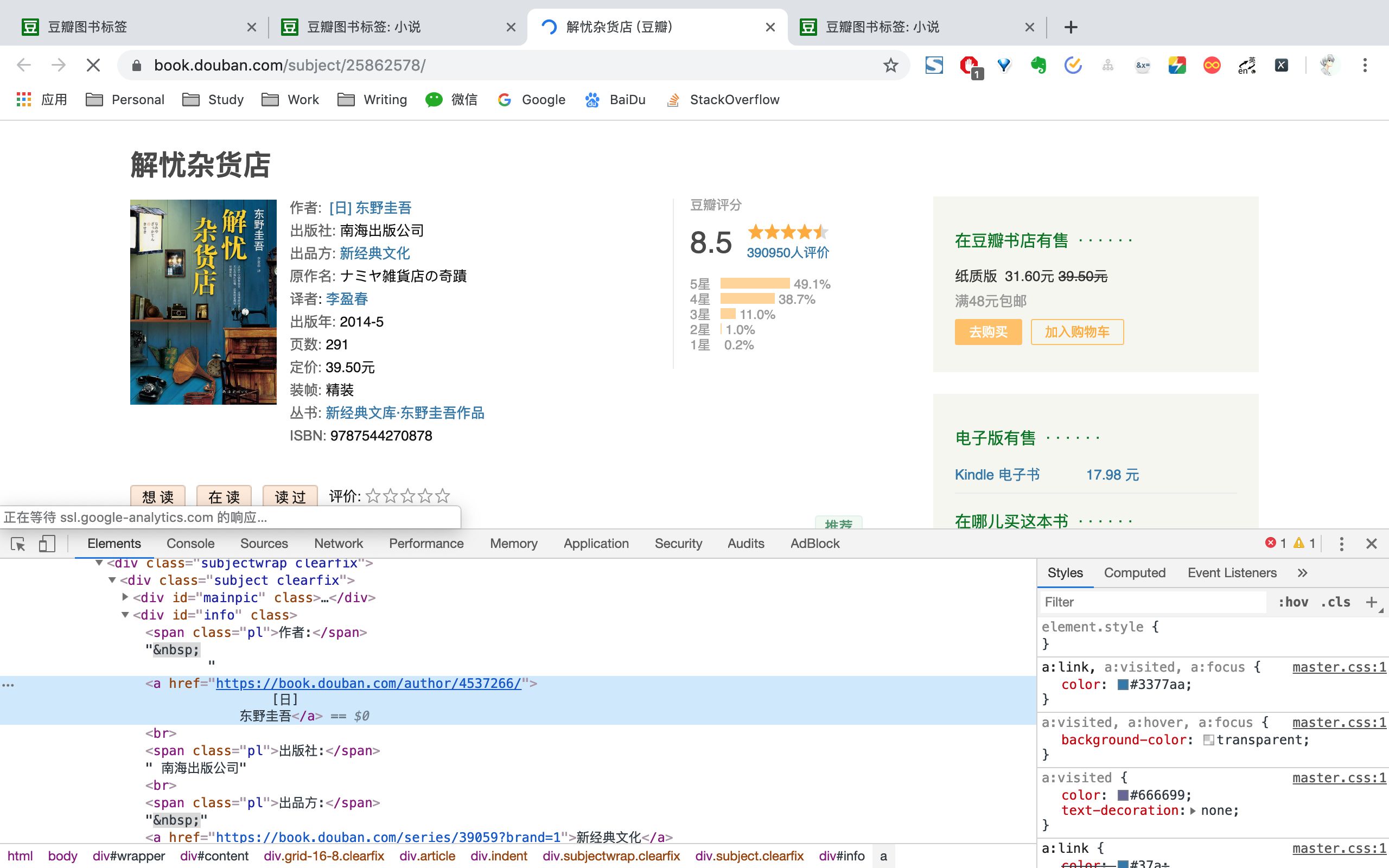
1、分析URL
爬取的目标url为,,这也是一个多页的爬取,url的规则为,start=0,25,分别为第一页,第二页,分别对应着每页的25本图书
需要爬取的整体内容
这次采用的是
def getBooks(self):pageCode = self.getPage()bsObj = BeautifulSoup(pageCode, 'lxml')for book in bsObj.findAll("td", {"valign": "top"}):if book.find('div',{'class':re.compile(r'pl[2]{1}')})==None:continuebookUrl = book.a['href'].strip() #图书详细信息的链接title = '《' + book.a['title'].strip() + '》' #图书标题detail = book.find('p',{'class':'pl'}).get_text().split('/') #图书相关细节author = detail[0].strip() #图书作者if len(detail)==5:translator = detail[1].strip() #图书译者press = detail[2].strip() #出版社date = detail[3].strip() #出版日期price = detail[4].strip() #图书价格else:translator = ''press = detail[1].strip()date = detail[2].strip()price = detail[3].strip()score = book.find('span',{'class':'rating_nums'}).get_text().strip() #图书评分scoreNum = book.find('span',{'class':'pl'}).get_text().strip('(').strip(')').strip() #图书评价人数quote = book.find('span',{'class':'inq'}).get_text() #简述self.book_list.append([title,author,translator,quote,press,date,price,score,scoreNum,bookUrl])2、爬取内容存入到EXCEl
import xlwt
def load(self,datalist):file = xlwt.Workbook()sheet = file.add_sheet('豆瓣图书Top250',cell_overwrite_ok=True)col = (u'图书名字',u'作者',u'译者',u'引述',u'出版社',u'发行日期',u'价格',u'评分',u'评价标准',u'图书详细链接')for i in range(0,10):sheet.write(0,i,col[i]) #列名for i in range(0,250):data = datalist[i]for j in range(0,10):sheet.write(i+1,j,data[j]) #数据file.save('豆瓣图书Top250.xls')3、整体代码
# coding:utf-8
"""
https://book.douban.com/top250?start=0
爬取豆瓣图书评分最高的前250本,
第一页:start=0,第二页:start=25......
"""
from urllib.request import urlopen
from urllib.request import Request
from urllib.error import URLError
from bs4 import BeautifulSoup
import re
import xlwtclass DoubanBook:def __init__(self, pageIndex):self.pageIndex = 0self.user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) ' \'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36'self.headers = {'User-Agent': self.user_agent}self.book_list = []def getPage(self):try:url = 'https://book.douban.com/top250?' + str(self.pageIndex)request = Request(url, headers=self.headers)response = urlopen(request)page = response.read().decode('utf-8')return pageexcept URLError as e:if hasattr(e, 'reason'):print("爬取失败,失败原因:", e.reason)def getBooks(self):pageCode = self.getPage()bsObj = BeautifulSoup(pageCode, 'lxml')for book in bsObj.findAll("td", {"valign": "top"}):if book.find('div',{'class':re.compile(r'pl[2]{1}')})==None:continuebookUrl = book.a['href'].strip()title = book.a['title'].strip()detail = book.find('p',{'class':'pl'}).get_text().split('/')author = detail[0].strip()if len(detail)==5:translator = detail[1].strip()press = detail[2].strip()date = detail[3].strip()price = detail[4].strip()else:translator = ''press = detail[1].strip()date = detail[2].strip()price = detail[3].strip()score = book.find('span',{'class':'rating_nums'}).get_text().strip()scoreNum = book.find('span',{'class':'pl'}).get_text().strip('(').strip(')').strip()quote = book.find('span',{'class':'inq'}).get_text()self.book_list.append([title,author,quote,press,date,price,score,scoreNum,bookUrl])def load(self,datalist):file = xlwt.Workbook()sheet = file.add_sheet('豆瓣图书Top250',cell_overwrite_ok=True)col = (u'图书名字',u'作者',u'引述',u'出版社',u'发行日期',u'价格',u'评分',u'评价标准',u'图书详细链接')for i in range(0,9):sheet.write(0,i,col[i]) #列名for i in range(0,250):data = datalist[i]for j in range(0,9):sheet.write(i+1,j,data[j]) #数据file.save('豆瓣图书Top250.xls')def start(self):print('现开始抓取豆瓣图书Top250的数据:')while self.pageIndex<=225:print('现抓取第%d页'% (self.pageIndex/25+1))self.getBooks()self.pageIndex+=25print("抓取完成")self.load(self.book_list)book = DoubanBook(0)
book.start()
tags:
豆瓣