常用的几种排序,卖菜的王婆已经学废了,你不来瞅瞅?
常用的八种排序
对一个数组进行排序你该不会只会用库函数的sort函数吧?没关系,看完这篇,分分钟带你学废八种排序
1.冒泡排序
冒泡排序( Sort),这是排序算法里面最简单的一个,这个名字由来就是把越大的元素经过慢慢的交换慢慢“浮”到最上面,就好像碳酸饮料中的二氧化碳一样最终会上浮到顶端,所以取名“冒泡排序”。
动图演示:
可以看出来,数组的长度是多少,就需要进行比较几趟,每一趟结束最大的元素都会“浮”上去
程序源代码:
public static void bubbleSort(int[] array){for (int i = 0; i < array.length; i++) {for (int j = 0;j < array.length-1-i;j++){if (array[j] > array[j+1]){int temp = array[j];array[j] = array[j+1];array[j+1] = temp;}}}}
这算代码大家应该都可以写出来,但是从上图可以看出来,在执行到绿色部分的时候,数组就已经有序了,不用进行后面的比较了,所以,我们对代码进行优化,当数组有序的时候就不再往下执行了,优化代码如下:
public static void bubbleSort(int[] array){for (int i = 0; i < array.length; i++) {boolean flg = true;for (int j = 0;j < array.length-1-i;j++){if (array[j] > array[j+1]){int temp = array[j];array[j] = array[j+1];array[j+1] = temp;flg = false;}}if (flg){break;}}}
首先就是在循环之前定义一个类型的变量为true,如果循环过程中元素之间进行了交换,就讲这个值置为false。因此,我们就可以通过这个类型的变量来判断是否进行了元素的交换,如果没有交换,则类型这个变量依然为true,此时数组有序了就可以直接跳出循环,否则继续排序。
2.插入排序
插入排序( Sort)也是一种简单直观的排序算法,插入排序的基本思想是:每步将一个待排序的记录,按照其元素的大小插入到已经排好序的数组的适当位置中,直到元素全部插入。
动图演示:
插入排序就是让待插入元素“找”到适合自己的位置,然后进行插入“归位”,直到数组遍历完成。
程序源代码:
public static void insertSort(int[] array){for (int i = 1;i < array.length;i++){int tmp = array[i];int j = i-1;for (;j >= 0;j--){if (array[j] > tmp){array[j+1] = array[j];}else{break;}}array[j+1] = tmp;}}
3.希尔排序
希尔排序(Shell Sort)属于插入排序的一种,又称为“缩小增量排序”,相比于直接插入排序,希尔排序更为高效。希尔排序的主要思想:将元素按下标的一定增量分为若干个组,每组分别进行直接插入排序,然后将组数减小,随着组数的减少,每组包含的元素也越来越多,当组数减为1时,算法便终止。
演示:
程序源代码:
public static void shellSort(int[] array){int[] arr = {5,3,1};for (int i = 0; i < arr.length; i++) {shell(array,arr[i]);}}public static void shell(int[] array,int gap){for (int i = gap;i < array.length;i++){int tmp = array[i];int j = i-gap;for (;j >= 0;j = j-gap){if (array[j] > tmp){array[j+gap] = array[j];}else{break;}}array[j+gap] = tmp;}}
为什么要用希尔排序呢?因为将数组分为若干个组,数据量小,插入所需的时间复杂度就会减小,希尔排序的分组根据什么确定呢?如上述代码中,就是根据数组元素的多少而决定,组数从最开始的5先减小为3,最后减小为1。
4.选择排序
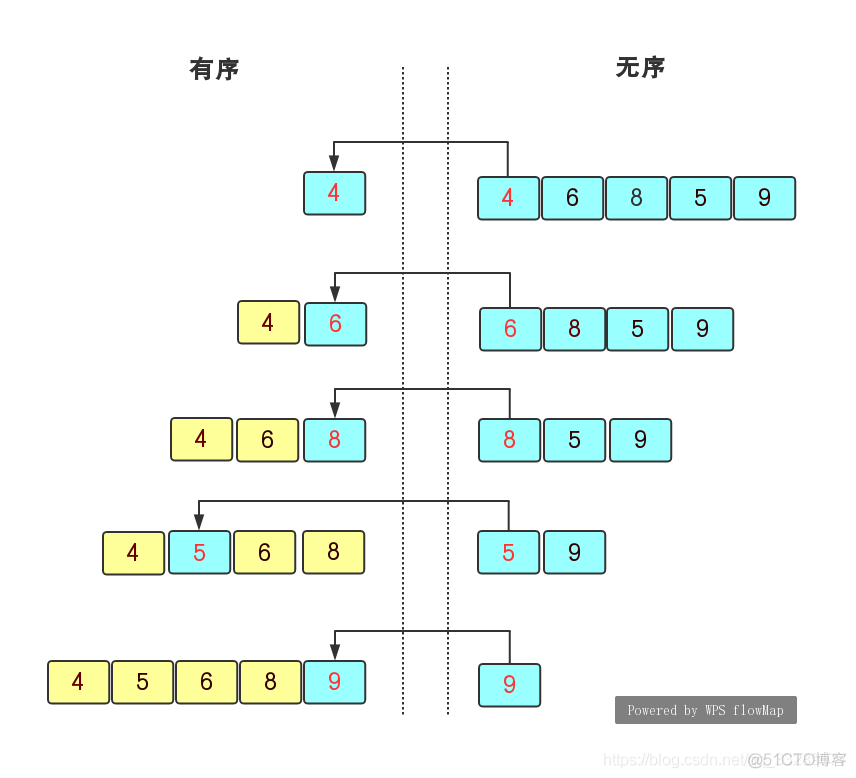
选择排序( Sort)是一种很简单直观的排序算法。选择排序的主要思想是:第一次从待排序的数组元素中选择最小(或者最大)的一个元素,放在序列的起始位置,再从数组元素中找到最小(或者最大)的元素放在已经排好序的后面,直到数组元素全部已经排序。
动图演示:
程序源代码:
public static void selectSort(int[] array){for (int i = 0; i < array.length; i++) {for (int j = i+1;j < array.length;j++){if (array[j] < array[i]){int tmp = array[i];array[i] = array[j];array[j] = tmp;}}}}
从代码量就能够看出来,选择排序的代码较少,思想也比较简单,容易理解。选择排序法,没有突破时间复杂度为O(n²)的瓶颈,但是性能上略优于冒泡排序法
什么??你觉得排序太简单了,别着急,重头戏在后面!!!
5.堆排序
堆排序()是指利用堆这种数据结构所设计的一种排序算法。堆是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
堆的操作:
在堆的数据结构中,堆中的最大值总是位于根节点(在优先队列中使用堆的话堆中的最小值位于根节点)。
堆中定义以下几种操作:
程序源代码:
public static void heapSort(int[] array){//1、建大堆 createHeap(array);//2、排序 int end = array.length-1;while (end > 0){int temp = array[0];array[0] = array[end];array[end] = temp;adjust(array,0,end);end--;}}public static void createHeap(int[] array){//p是每个子树的根节点for (int p = (array.length-1-1)/2;p >= 0;p--){adjust(array,p,array.length);}}public static void adjust(int[] array,int parent,int len){int child = 2*parent + 1;while (child < len){if (child+1 <len && array[child] < array[child+1]){child++;}if (array[child] > array[parent]){int tmp = array[child];array[child] = array[parent];array[parent] = tmp;parent = child;child = 2*parent + 1;}else{break;}}}
总结一下堆排序的流程:
1.首先将无序的数组构造一个大根堆(新插入的元素与其父类节点的值进行比较)
2.固定一个最大值,将剩余的数重新构造一个大根堆,重复此过程。
6.快速排序(重要)
快速排序()简称快排,是对冒泡排序算法的一种改进。
顾名思义快速排序最大的优点就是速度比较快,是我们后续工作中用到最多的一种排序。它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
首先定义两个指针low指向起始位置,high指向最后一个元素的位置,然后指定初始位置基数key,作为坑low寻找比基数key大的数字,找到后将low的数据赋给high,low成为一个坑,然后hight寻找比基数key小的数字,找到将hight的数据赋给low,high成为一个新坑,循环这个过程,直到low指针与high指针相遇,然后将key返回给那个坑(最终:key的左边都是比key小的数,key的右边都是比key大的数),然后进行递归操作。
动图演示:
程序源代码:
public static void quickSort(int[] array){quick(array,0,array.length-1);}public static void quick(int[] array,int low,int high){if (low >= high){return;}int par = partion(array,low,high);quick(array,low,par-1);quick(array,par+1,high);}public static int partion(int[] array,int start,int end){int tmp = array[start];while (start < end){while (start < end && array[end] >= tmp){end--;}if (start >= end){array[start] = tmp;break;}else{array[start] = array[end];}while (start < end && array[start] <= tmp){start++;}if (start >= end){array[start] = tmp;break;}else{array[end] = array[start];}}return start;}
这样我们就实现了对数组的快速排序,但是,我们还觉得这个速度不够快,还能怎样进行优化呢?
这里我们采用了两种优化方法:
第一种是三数取中,构造一个三数取中的函数,将数组的第一个元素low,中间那个元素mid和最后一个元素三个元素进行比较,取中间那个数为基准(key)。
第二种是直接插入法,构造一个直接插入的函数,当数据量较少的时候就可以使用直接插入的方法。
优化后的代码:
public static void quickSort(int[] array){quick(array,0,array.length-1);}public static void quick(int[] array,int low,int high){if (low >= high){return;}//优化2、直接插入排序if (low + high +1 <100){insertSort2(array,low,high);return;}//优化1、三数取中int mid = (low + high)>>>1;medianOfThree(array,low,mid,high);int par = partion(array,low,high);quick(array,low,par-1);quick(array,par+1,high);}public static int partion(int[] array,int start,int end){int tmp = array[start];while (start < end){while (start < end && array[end] >= tmp){end--;}if (start >= end){array[start] = tmp;break;}else{array[start] = array[end];}while (start < end && array[start] <= tmp){start++;}if (start >= end){array[start] = tmp;break;}else{array[end] = array[start];}}return start;}//三数取中函数public static void medianOfThree(int[] array,int low,int mid,int high){//array[mid] <= array[low] <= array[high]if (array[mid] > array[low]){int tmp = array[low];array[low] = array[mid];array[mid] = tmp;}//array[mid] <= array[low]if (array[low] > array[high]){int tmp = array[low];array[low] = array[high];array[high] = tmp;}//array[low] <= array[high]if (array[mid] > array[high]){int tmp = array[mid];array[mid] = array[high];array[high] = tmp;}//array[mid] <= array[high]}//对区间数据进行直接插入排序public static void insertSort2(int[] array,int start,int end){for (int i = start;i <= end;i++){int tmp = array[i];int j = i-1;for (;j >= start;j--){if (array[j] > tmp){array[j+1] = array[j];}else{break;}}array[j+1] = tmp;}}
总结一下,快速排序之所以快,因为和冒泡排序比起来每次的交换是跳跃式的,每次排序的时候设置一个基准,将小于基准的元素都放在基准的左边,将大于基准的元素都放在基准的右边。
7.归并排序(重要)
归并排序(Merge Sort)是建立在归并操作上的一种有效,比较稳定的排序算法。先将数组分为若干个子序列,将子序列先进行排序,再将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。如果将两个有序表合并成一个有序表,称为二路归并。归并排序就是用空间换取时间的实列。
程序源代码:
public static void margeSort(int[] array){margeSortRec(array,0,array.length-1);}public static void margeSortRec(int[] array,int low,int high){if (low >= high){return;}int mid = (low + high)>>>1;margeSortRec(array,low,mid);margeSortRec(array,mid+1,high);marge(array,low,mid,high);}public static void marge(int[] array,int low,int mid,int high){int s1 = low;int e1 = mid;int s2 = mid+1;int e2 = high;int[] tmpArray = new int[high-low+1];int k = 0;while (s1 <= e1 && s2 <= e2){if (array[s1] < array[s2]){tmpArray[k++] = array[s1++];}else{tmpArray[k++] = array[s2++];}}while (s1 <= e1){tmpArray[k++] = array[s1++];}while (s2 <= e2){tmpArray[k++] = array[s2++];}for (int i = 0;i < tmpArray.length;i++){array[i + low] = tmpArray[i];}}
总结一下,归并排序主要就是用到递归的思维,要注意的是哪个先比较完了之后,那么剩下的就不需要比较,直接把后面的直接移上去就好了,这个需要提前判断一下。
8.计数排序
计数排序是一个非基于比较的排序算法,它的优势在于在对一定范围内的整数排序时,它的复杂度为Ο(n+k)(其中k是整数的范围),快于任何比较排序算法,当然这是一种牺牲空间换取时间的做法。
程序源代码:
public static int[] countSort(int[]a){int b[] = new int[a.length];int max = a[0],min = a[0];for(int i:a){if(i>max){max=i;}if(i<min){min=i;}}//这里k的大小是要排序的数组中,元素大小的极值差+1int k=max-min+1;int c[]=new int[k];for(int i=0;i<a.length;++i){c[a[i]-min]+=1;//优化过的地方,减小了数组c的大小}for(int i=1;i<c.length;++i){c[i]=c[i]+c[i-1];}for(int i=a.length-1;i>=0;--i){b[--c[a[i]-min]]=a[i];//按存取的方式取出c的元素}return b;}
我们看到,计数排序算法没有用到元素间的比较,它利用元素的实际值来确定它们在输出数组中的位置。因此,计数排序算法不是一个基于比较的排序算法,从而它的计算时间下界不再是O(nlogn)。
各种排序方式的复杂度及稳定性比较