干货 | Elasticsearch多表关联设计指南
干货 | 多表关联设计指南 0、题记
多表关联问题是讨论最多的问题之一,如:博客和评论的关系,用户和爱好的关系。
多表关联通常指:1对多,或者多对多关系在ES中的呈现。
本文以星球问题为出发点,引申出ES多表关联认知,分析了4种关联关系的适用场景、优点、缺点。
希望对你有所启发,为你的多表关联方案选型、实战提供帮助。
1、抛出问题
1.1 星球典型问题

1.2 社区典型问题
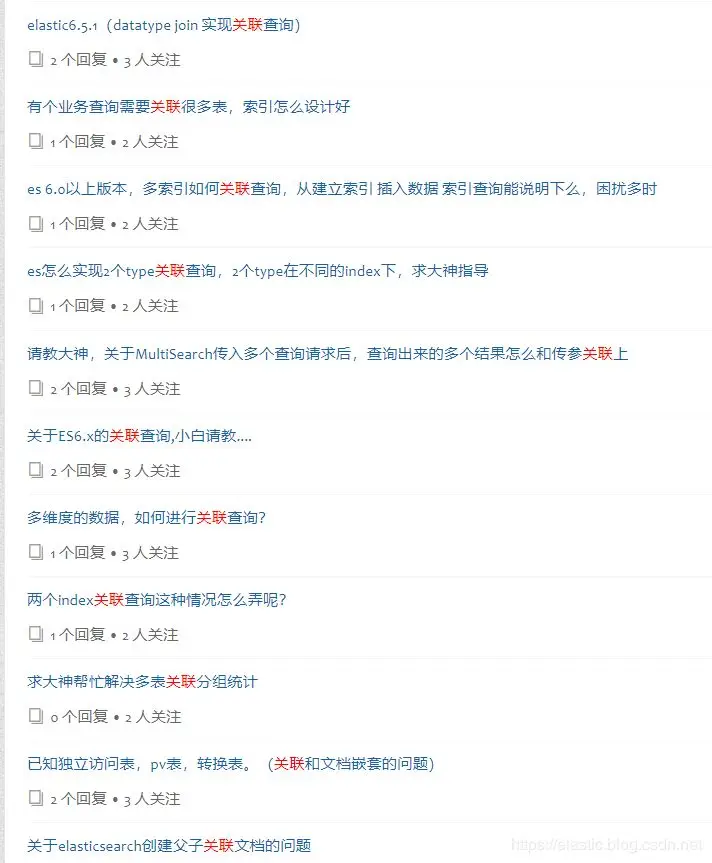
1.3 QQ群典型问题
关系型数据库中的多表之间的关联查询,ES中有什么好的解决方案?
如果我把关联关系的表迁移到ES中放到一个type下,文档结构除了对象之间的嵌套还有什么好的解决方案?
2、基础认知
2.1 关系型数据库
关系数据库是专门为关系设计的,有如下特点:
关系型数据库的缺陷:
2.2
,和大多数 NoSQL 数据库类似,是扁平化的。索引是独立文档的集合体。 文档是否匹配搜索请求取决于它是否包含所有的所需信息和关联程度。
中单个文档的数据变更是满足ACID的, 而涉及多个文档时则不支持事务。当一个事务部分失败时,无法回滚索引数据到前一个状态。
扁平化有以下优势:
索引过程是快速和无锁的。
搜索过程是快速和无锁的。
因为每个文档相互都是独立的,大规模数据可以在多个节点上进行分布。
2.3 Mysql VS
3 关联关系如何存储
关联关系仍然非常重要。某些时候,我们需要缩小扁平化和现实世界关系模型的差异。
以下四种常用的方法,用来在 中进行关联数据的管理:
3.1 应用端关联
这是普遍使用的技术,即在应用接口层面来处理关联关系。
针对星球问题实践,
存储层面:独立两个索引存储。
实际业务层面分两次请求:
第一次查询返回:Top5中文姓名和成绩;
根据第一次查询的结果,第二次查询返回:Top5中文姓名和英文姓名;
将第一次查询结果和第二次查询结果组合后,返回给用户。
即:实际业务层面是进行了两次查询,统一返回给用户。用户是无感知的。
适用场景:数据量少的业务场景。
优点:数据量少时,用户体验好。
缺点:数据量大,两次查询耗时肯定会比较长,影响用户体验。
引申场景:关系型数据库和ES 结合,各取所长。将关系型数据库全量同步到 ES 存储,不做冗余存储。
如前所述:ES 擅长的是检索,而 MySQL 才擅长关系管理。所以可以考虑二者结合,使用 ES 多索引建立相同的别名,针对别名检索到对应 ID 后再回 MySQL 查询,业务层面通过关联 ID join 出需要的数据。
3.2 宽表冗余存储
对应于官方文档中的“Data ”,官方直接翻译为:“非规范化你的数据”,总感觉规范化是什么鬼,不好理解。
通俗解释就是:冗余存储,对每个文档保持一定数量的冗余数据可以在需要访问时避免进行关联。
这点通过 同步关联数据到ES时,通常会建议:先通过视图对Mysql数据做好多表关联,然后同步视图数据到ES。此处的视图就是宽表。
针对星球问题实践:姓名、英文名、成绩两张表合为一张表存储。
适用场景:一对多或者多对多关联。
优点:速度快。因为每个文档都包含了所需的所有信息,当这些信息需要在查询进行匹配时,并不需要进行昂贵的关联操作。
缺点:索引更新或删除数据,应用程序不得不处理宽表的冗余数据;
由于冗余存储,导致某些搜索和聚合操作可能无法按照预期工作。
3.3 嵌套文档()存储
类型是ES 定义的集合类型之一,它是比类型更NB的支持独立检索的类型。
举例:有一个文档描述了一个帖子和一个包含帖子上所有评论的内部对象评论。可以借助 实现。
实践注意1:当使用嵌套文档时,使用通用的查询方式是无法访问到的,必须使用合适的查询方式( query、 、 facet等),很多场景下,使用嵌套文档的复杂度在于索引阶段对关联关系的组织拼装。
推荐实践:干货 | 类型深入详解
实践注意2:
index.mapping.nested_fields.limit 缺省值是50。即:一个索引中最大允许拥有50个nested类型的数据。index.mapping.nested_objects.limit 缺省值是10000。即:1个文档中所有nested类型json对象数据的总量是10000。
适用场景:1 对少量,子文档偶尔更新、查询频繁的场景。
如果需要索引对象数组并保持数组中每个对象的独立性,则应使用嵌套 数据类型而不是对象 Oject 数据类型。
优点:文档可以将父子关系的两部分数据(举例:博客+评论)关联起来,可以基于类型做任何的查询。
缺点:查询相对较慢,更新子文档需要更新整篇文档。
3.4 父子文档存储
注意:6.X之前的版本的父子文档存储在相同索引的不同type中。而6.X之上的版本,单索引下已不存在多type的概念。父子文档Join的都是基于相同索引相同type实现的。
Join类型是ES 定义的类型之一,用于在同一索引的文档中创建父/子关系。 关系部分定义文档中的一组可能关系,每个关系是父名称和子名称。
实践参考: 6.X 新类型Join深入详解
适用场景:子文档数据量要明显多于父文档的数据量,存在1 对多量的关系;子文档更新频繁的场景。
举例:1 个产品和供应商之间是1对N的关联关系。
当使用父子文档时,使用 或者做父子关联查询。
优点:父子文档可独立更新。
缺点:维护Join关系需要占据部分内存,查询较更耗资源。
4 小结

在开发实战中对于多表关联的设计要突破关系型数据库设计的思维定式。
不建议在es做join操作,-child能实现部分功能,但是它的开销比较大,如果可能,尽量在设计时使用扁平的文档模型。
尽量将业务转化为没有关联关系的文档形式,在文档建模处多下功夫,以提升检索效率。
&Join父子文选型必须考虑性能问题。 类型检索使得检索效率慢几倍,父子Join 类型检索会使得检索效率慢几百倍。
以上内容,实际官方文档都有明确的描述。我把内容加上自己的理解,作了精炼和解读。
再次强调:第一手资料的重要性。但本着“再显而易见的道理,也有N多人不知道”的原则,一定要读英文官方文档,加深认知理解。
多表关联你是如何做的呢?欢迎留言写下您的思考。
参考:
[1]
[2] 教程