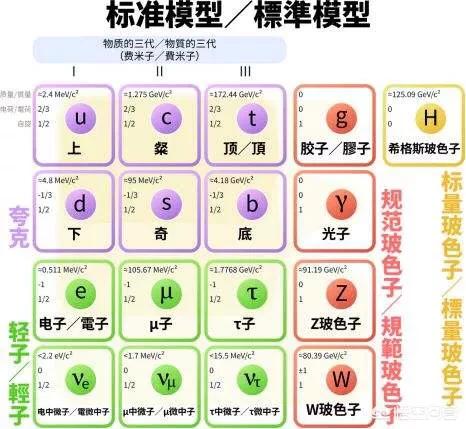
王琤:当数据治理遇上ChatGPT
以为代表的人工智能等技术正在“狂飙”,为全球带来一场翻天覆地的变革。4月27日在2023数据治理新实践峰会上,数语科技创始人&CEO王琤先生以《数据治理新实践与人工智能》为主题进行了分享,与参会同仁共同探索当数据治理遇上,这一轮AI技术浪潮将会与数据治理发生哪些“化学反应”。
以下为王琤先生的演讲实录,为了方便阅读,小编做了一些字句修改和文本优化。
大家好,首先我先代表数语感谢各位莅临2023年数据治理新实践峰会!今天的主要话题是围绕,是人类历史的一个拐点。
数据要素为什么会成为新型生产要素?
首先我们先看看数据要素这个事,目前在国内认为它是新型生产要素,这是为什么?我更多的是从经济发展的三阶段来解读,第一个阶段是农业经济,核心要素是劳动力和土地;第二个阶段是工业经济,核心要素是资金、技术等,第三个阶段也就是咱们说的数字经济,核心的变化在于前两个阶段侧重于“供需方”,也就是企业、顾客双方进行资源配置和价值交换,但当数据融入以后就会生成更多内容,就出现了AIGC(AI ),这意味着更多的企业、顾客、利益相关者共创价值。
从企业场景的角度来说,也就是数字孪生,就是把内容信息进行数字化,进而去做一些数字孪生和预测推演,进而产生对应的价值,数字孪生的1.0版本我们叫角色最优化,2.0版本叫平行世界,也就是将数字化完全做一个数字孪生提前来Run,来预测现实世界有可能会发生什么,反馈给现实世界来提前进行优化,我认为这才是数据作为生产要素被引进来的真正价值。
技术驱动数字化发展带了什么影响?
接下来我将引用几张最近很火的陆奇博士的课件。从劳动力的角度来讲,在农业社会,农民和地是关联在一起的,是强耦合关系;之后的工业社会,劳动力开始流动,生产的产品也是流动的;到现阶段在数字化进程中,其实更多是服务经济,里面的核心角色是程序员、设计师、分析师等;从数字信息无处不在到数字化模型无处不在,这是个大拐点。所以大家都在预测说,可能模型会把程序员、设计师、分析师等都替换掉,这个是当前社会比较焦虑的一件事。等模型更加成熟后,主要的工作可能是去做创业者或者高端科学家。
陆奇博士将人类环境分为三个体系。第一个是感知-信息系统,也就是信息无处不在;第二是思考-模型系统,其实就是我们的知识模型,第三个是实现-行动系统。信息系统早期像IBM、微软等都是在感知和采集信息,可以看到其中的拐点是 将人类获取信息的成本基本拉为0,当然信息系统未来会长期存在。当前我们正处于第二个思考-模型系统 Open AI拐点处, 3.5带来了质变,我们称之为新范式,它将我们获取知识(思考)的成本拉得很低,其本质就是把数据转化为知识表达,通过推理和归纳来实现预期记忆和泛化。最后的行动系统更多讲的是人跟物理世界的转换。
关于把数据转化为知识表达,通过推理和归纳来实现预期记忆和泛化,这两天有个真实发生的例子。在开源模型社区的群里,有人发起针对LD-FSM模型中当事人的关联关系设计的讨论。

大家的回复七嘴八舌,各种角度都有,但始终没有一语道破天机的感觉。这时有人开始把的回应贴了上来。
首先,给了一个上下文,“你是一个资深的数据建模专家”,但这版回复感觉还是不太对路子。
于是,要求再次回答。这次的回答已经相当靠谱了。基本可以达到行业专家的水准。
但这里面还有一些模糊的表述,如“当事人关系在建模中重点描述的是当事人之间的相互作用”,这个相互作用是指什么?于是,再要求对此进行澄清。给了个例子把这个问题阐述的很清楚。
最后,让给予再次澄清和举例。
大家看看这是不是将获取知识(思考)的成本拉得很低,背后就是把数据转化为知识表达,通过推理和归纳来实现预期记忆和泛化。
我们之前要搞定这个事可能要请个模型专家来做个咨询项目,前后得折腾几个月花几万、几十万,现在成本几乎是零。 这就像当年推出搜索引擎,我们获取信息的成本降为零是一样的。所以,我们当前站在一个大的拐点上。
成功的核心要素是什么?
的GPT模型是基于序列式的模型架构,相较于之前的知识图谱等方法,序列式的模型架构可以更高效地把大量的信息做压缩,这是最核心的突破点;其次英语是全球性的语言,信息的量其实是全世界的人都在做贡献。如果放在中文环境,可能面临的挑战还是蛮多的,因为像是西方的文化本身是有推演演绎的哲学逻辑,但中文更复杂,理解难度大,所以相对于英文语料来说差了一个数量级。从中文的角度来讲,未来这些信息的抓取和训练,到底把英文的信息转成中文的,还是从中文直接就开始去做起?这个是一个比较大的十字路口。
人工智能到底可以发展到什么程度?
以为代表的人工智能技术具有强大的能力。一般我们讲人工智能发展分为三个阶段,战胜人类国际象棋大师的阶段属于弱人工智能,目前阶段基本上快到强人工智能,跟人脑的水平差不多,甚至超过人脑,再之后就是超人工智能,就是已经到把人类的这些知识都能覆盖到的阶段,有人预测到2030年或2040年可能实现超人工智能。
美国的益智问答大奖赛,人类冠军跟机器去PK,很难赢。所以像益智问答、算数,死记硬背等这些早都被人工智能Cover到了。然后就是像自动驾驶,语音的识别、视觉、翻译等这些几乎都可以实现人工智能,但像科学、像设计,像写书、像艺术这些东西短期人工智能还难以企及的,所以有一些讨论到底人工智能可以发展到什么程度,这里要提一个有意思的理论—约翰·希尔勒的“中文屋实验”,未来机器到底能不能有一些情感,它能不能发展到不可控的程度?这个尚未有结论,是个开放思考题留给大家。
以AI赋能,数据治理智能化的引擎
其实我们也对做了蛮多研究的,首先我们先问问可以帮助数据治理干些什么?它的回答:第一、能做一些数据治理的这种制度流程。第二、能分析一些数据的有效性、一致性。第三、数据治理的一些质量监测、安全合规,同时做一些任务自动化。针对它回答的第一点,我们让它列举 100 条制造业的行业数据标准,它可以大致给出符合期望的答案。
接下来让它写了一段“用 SQL 去检查身份证号码有效性的代码”,写得非常的完美,确实很强。
那么,数据治理该如何拥抱以为代表的新一轮的AI技术浪潮?
安全分类分级智能化实践
从实践出发,其实一直在做数据安全分类分级的智能化研发。在我们的产品平台架构中,我们通过训练行业分类分级大体系形成一套分类分级的语料库。再通过 Word to 将词向量的距离进行比较,也就是拿一个分类分级跟一个元数据取向量的距离。当然这个过程中肯定也要做一些优化。对于大段信息描述,我们通常采用拆词的方法,这个可能导致拆出来的信息没有意义,这个时候就需要人工优化。
如下图所示,我们对分类的描述做分词处理,然后放在向量空间进行相关运算,看字段与分类的描述的关联度,得出向量空间值,获得与字段相关度最高的数据分类推荐。
其实,目前我们在证券包括银行行业做了很多智能安全分类分级,尤其针对人行的数据安全分类分级的行业标准,我们把这个语料库通过智能化+人工的方式做了一套训练,同时我们拥有一套1220万条的行业语料库来补充人行的这套语料库,因此,在银行业数据分类分级的首次识别率可以达到76%,加上人工优化可以达到90%,当然整个过程有自反馈的效果,也是机器自学习的过程。