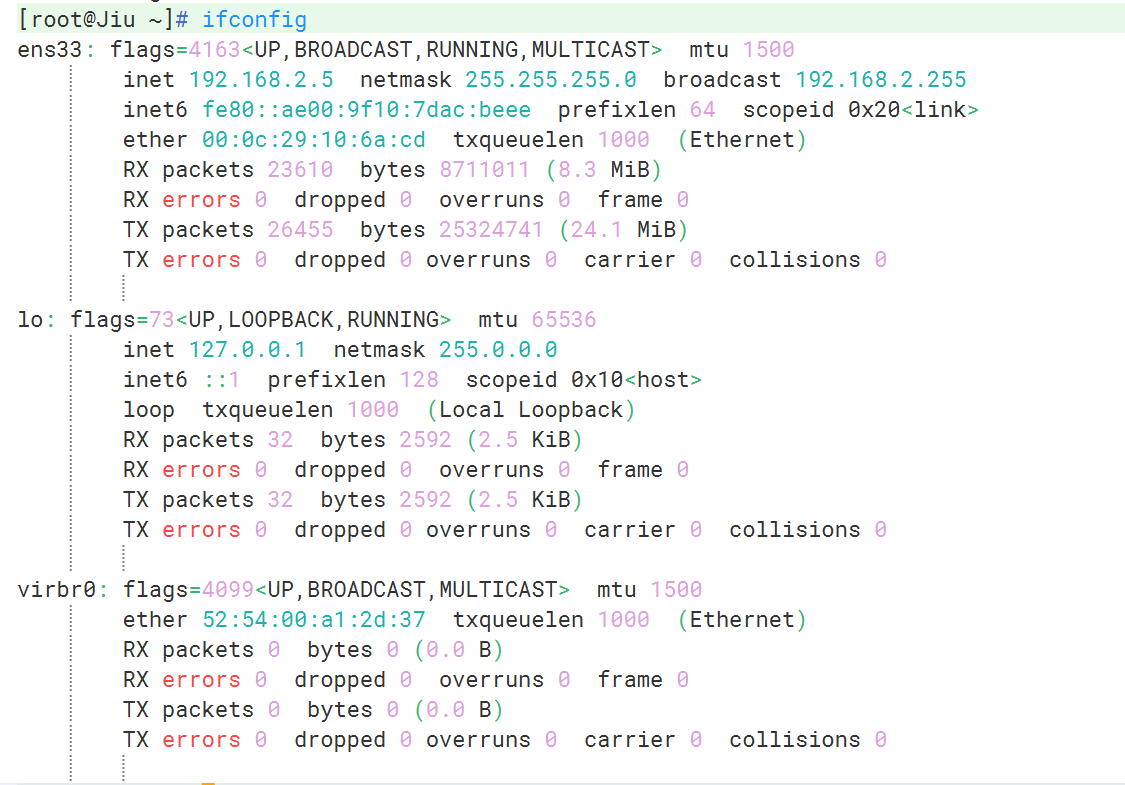
为什么页面接收到的中文是乱码?
在开发中,我们也许会遇到在页面之间传递参数的时候,传递因为参数是没有什么问题的,但是传递中文参数缺是乱码,本文大致讲解下一些关于中文乱码的一些问题。
一、 几种常用编码
1. ASCII编码
产生目的:解决英文字符与二进制位之间的对应关系
原理:由于计算机中的所有信息都是采用二进制位(bit)表示的字符串,一个字节(byte)由8个二进制位组成,所以最多可以表示256个英文字符。由于ASCII码只有128个字符,所以只用一个字节的后边7位已经足够,最前面的1位统一用0表示。
字符个数:128个
2. ISO-8859-1编码
产生目的:解决ASCII码在不同国家不够用的情况,是一个单字节编码(该编码是JAVA网络传输使用的标准字符集,)
原理:对于ASCII编码剩下的最前面的1位进行编码,所以个数是ASCII码的2倍,也就是256个
字符个数:256个
3. 编码
产生目的:中华人民共和国国家汉字信息交换用编码,主要是我国为了表示汉字而颁发的一种编码
字符个数:7445个(汉字6763个)
4. GBK编码
产生目的:由于编码支持的汉字只能有6763个,为了支持能够支持更多的汉字而开发的一种编码,支持编码的6763个字符。(也就是编码的扩充)
字符个数:21886个(汉字20902个)
5. UTF-8编码
产生目的:是编码的一种编码方式,为了解决能够表达全球不同国家的不同字符,在不同国家打开同一文件不再是乱码。
原理:采用8位序列来编码,用一个字节或者几个字节来表示一个字符。UTF-8是一种变长的编码方式,一个字符的长度为1-4个字节。
6. 其他
UTF-16和UTF-32也是的2中不同编码方式,他们分别是采用16位和32位的序列来编码,通常说的编码指的是UTF-16。由于在HTML4中已经能够很好的支持UTF-8了,所以现在因特网的编码方式首选还是UTF-8。
二、 页面传递参数原理
上图的说明:
第一步:
用户填写表单信息
第二步:
IE对用户填写的表单信息进行编码,优先采用IE的设置,其次采用的值进行编码(IE默认采用UTF-8编码)
第三步:
应用服务器根据对象上设置的的值对中获取到的值进行解码(服务器默认是ISO-8859-1),
第四步:
在页面中接收参数,调用.(“”)方法获取参数值
三、 实例
四、 应用服务器传递参数解
1. .xml中节点监听的线程从中获取数据的类
org....
2. 类的调用关系
3.看看org....的方法
4. 再来看看org...util.http.的的调用过程
5. 的时候参数是已经编码,具体的编码跟踪之后可以确定是跟有关,下图是调用在方法:org...util.http.的方法
6. 的默认编码设置见.方法
7. 为什么接受中文是乱码?
在上图中,当我们第二步采用的编码是UTF-8,如果我们没有指定.()的值,那么在第三步应用服务器采用默认的iso-8859-1进行解码,这样导致编码和解码不一致,所以读取中文的时候是乱码了。