AI部署之路 | 模型选型、本地部署、服务器部署、模型转换全栈打通!
作者| 编辑|汽车人
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【模型部署】技术交流群
后台回复【模型部署工程】获取基于的分类、检测任务的部署源码!
好久没更文了,每次偷懒一段时间再更文的时候,总会感慨技术发展太快了,之前写的东西又有点过时了。
尤其是AI领域,变动太快,大家的风向也一直在变,前两年还在VR/XR的搞,今年因为的爆火,不少公司已经加大这方面的投入了。
最主要是在普通人中也是爆火,距我上篇文章(让回答大家喜闻乐见的深度学习部署问题)也就不到俩月吧,很多人真真确确感受到了对自己工作和效率的影响,也提升了我工作的效率。比如有些不熟悉的API终于不用查了,浪费时间,直接给一说就行。
话说回来,技术发展快,稍不留神自己用的技术就过时了(我还在用v5,别人已经V8了!)。
现在AI部署也很卷,资料繁多,开源代码也不少,学习群更是一堆。你说学这个我说学那个真有点乱,但又不想错过,所以干脆总结下,之后会找个网站放着随时更新(等我弄好语雀的图床转换就可以上传了!)。
我是卷不动了,列个清单你们卷吧!
部署之路
之前也写过不少关于部署的文章,但技术更迭很快,写出来的内容也不可能覆盖所有地方,而且很多小伙伴也会问我一些新的问题。干脆写一个比较全的总结版,挂到和自己的博客上,之后有新想法了、新点子了,也会随时更新。大家想找学习路线看这一篇跟着学就对了。当然我也不是什么大佬,难免存在纰漏,望大家及时提醒,我好及时纠正。
尽管说是部署之路,重点是部署,但多多少少也要会一些模型训练和设计,只有理解模型的具体使用场景、使用要求,才能够使用更多方式去优化这个模型
整理了下,涉及到训练、优化、推理、部署这几块,暂时把我能想到的都列出来了,后续也会不断更新(立个flag):
本文也仅仅是总结的作用,尽可能把东西都列全。每部分的细节,会总结相关文章再展开描述,可能是我写的,也可能是其他人优秀的文章。
附上之前的两篇文章:
学习建议
诚然,我们想学的东西很多。但很多方向我们不可能每个都精通、像单独领域中的大佬一样,因为我们每个人的时间精力问题,我们可以雨露均沾,但是不可能样样大神,学的再多,也是沧海一粟。
于是最好的办法就是抓重点学习,比如:
比如商汤的2023年HPC团队招聘计划,一些岗位需求也可以参照学习:
很多需要学习的点,也一一列出来了,又或者你想学习高性能计算:
这些JD已经把需要你的,你需要的技能点都列出来了,自己按需点满即可。
学习是自己的事儿,自己想干啥想学啥,最好有个明确的目标,不要瞎学不要浪费时间。
首先要有模型
搞深度学习部署最重要的当然是模型,大部分的场景都是靠模型和算法共同实现的,这里的算法又包含逻辑部分(俗称if-else)、算法部分(各种各样与场景相关的算法,比如滤波算法等)、图像处理部分(我这里主要指的是视觉场景,比如二值化、最大外接矩形等等)等等。当然这是我的经验,可能其他场景有不同的组合。
模型当然是最重要的,因为模型效果或者速度不行的话,用传统图像方法或者逻辑(if-else)捞case是比较困难的,在某些场景中模型可以直击要害,抓需求重点去学习。
举个极端的例子,比如你要识别一个人的动作,这个人跳起来然后落下来算一个,也就是无绳跳跃。如果训练一个检测模型,首先检测这个人,然后分两类,跳起来算一类,落下来算一类,产出一个分两类的检测模型,那这个问题就好解多了,逻辑只需要根据模型结果来判断即可。但如果没有这个模型的话, 你可能会通过检测人的模型+姿态检测+时序算法来判断这个人到底有没有跳跃一次了。
知道模型的重要性了,关于怎么收集数据怎么训练这里姑且先不谈了。涉及到部署的话,模型就不能只看精度了,了解些部署的算法工程师在设计模型的时候通常也会注意这一点,实用好用(好训练好部署,比如、V7)才是重点。
实际应用中的模型,往往有以下一些要求:
模型的设计需要考虑计算量、参数量、访存量、内存占用等等条件。可以参考这篇:深度学习模型大小与模型推理速度的探讨,内容很详实!
相关参考:
自己造模型
有了想法,有了目标,有了使用场景,那就训练一个模型吧!
如何设计模型
关于设计模型的思路,大部分人会直接参考上找开源的模型结构,这个没问题,根据场景选对就行:
如果自己对模型优化也有特定了解的话,可以针对特定平台设计一些对硬件友好的结构(这里举个例子,比如重参数化的),一般来说大公司会有专门的高性能计算工程师和算法工程师对齐,当然小公司的话,都要干了555。
模型结构
根据经验和理论知识来设计模型的结构(比如dcn系列、比如senet中的se模块、yolo中的fcos模块);根据任务来设计模型;NAS搜索模型;
有很多优秀的模型块结构,属于即插即用的那种,这里收集一些常见的:
训练框架
训练框架这里指的不是或者,而是类似于mmlab中各种任务框架,比如、这种的。
你如果想自己训练一个检测模型,大概是要自己基于去重新实现一些方法:数据处理、模型搭建、训练优化器、debug可视化等等。比较烦而且浪费时间,如果有这些已经完善的轮子你自己使用,个人觉着是比较舒服的,但是当然有优劣:
一些大的轮子可以参考:
一些小的轮子可以参考:
我个人之前使用的是,但是官方貌似不怎么维护了,因为我打算增加一些新功能,但是没有时间搞。后来发现.0出来了,之前那会使用过.0版本,感觉封装的太深了,训练的模型导出很费劲儿就没怎么用。后来2.0简单看了看上手稍微简单了些,打算切到mmlab系列,主要原因还是支持比较丰富,各种pr很多,有的模型不需要你移植就已经有人移过去了,省去很多造轮子的时间。
后面我也会比较下和.0这俩框架。
导出模型
自己的模型在训练完毕后,如果不是直接在训练框架中推理(好处就是模型精度和你eval的时候一致,而且不需要花时间转模型的格式,坏处就是模型运行速度不能保证,而且环境比较依赖解释器),大部分是要导出的。
导出的格式有很多,我也不一一列了,可以参考模型的介绍:
导出模型也就是模型转换,只不过因为是自己训练的,一般会从自己训练框架为起点进行转换,可以避免一些中间转换格式。
比如我经常使用,如果训练完模型后,需要转为的模型,正常来说可能会->ONNX->。但是这样会经过ONNX这个中间模型结构,可能会对最终模型精度产生不确定性,我可能也会直接从转为:
因为支持比较好,所以能这样搞,支持不好的,可能还要走ONNX这个路子。
nas搜索
nas就是搜索一个在你平台上一个速度最优的模型结构,目前我只了解过DAMO相关的一个搜索,还未深度尝试:
别人的模型
直接拿现成模型来用的情况也很多见:
不知道大家有没有这种情况,在网上寻找他人训练好的合适的模型的时候,有一种探索的感觉,类似于开盲盒,一般会看模型在某个平台的速度或者某个任务的精度,以及模型本身的一些特点啥的,我比较喜欢中的MODEL CARD介绍模型的方法,详细介绍了该模型的输入输出,训练集,特点,模型性能啥的:
个人建议,如果自己训练的模型想要被别人更好地使用,想开源模型贡献的话,也可以参考写个类似的[model card](),介绍下你的模型哈。
回到正题,拿到模型的第一点,当然是观察模型的结构。模型结构主要是为了分析这个模型是基于哪个、哪个框架训练的,可以知道模型的大概,心里有数:
一般来说要看:
一般经验丰富的算法工程师,大概看一下模型结构、模型op类型就知道这个模型坑不坑了。
分两种,一种是评测模型的精度指标,一些常见的指标:
不列了,不同任务模型评价的指标也不一样,明白这个意思就行。
另一种是模型的性能,在确认模型精度符合要求之后,接下来需要看模型的几个指标:
相关概念:
to the of time it takes for the model to make a after input. In other words, it's the time the input and the . is an for real-time where fast are , such as in self- cars or .
to the of that a model can make in a given of time. It's in per (PPS). is an for large-scale where the model needs to a large of data , such as in image or .
举个的例子:
[01/08/2023-10:47:32] [I] Average on 10 runs - GPU latency: 4.45354 ms - Host latency: 5.05334 ms (enqueue 1.61294 ms)
[01/08/2023-10:47:32] [I] Average on 10 runs - GPU latency: 4.46018 ms - Host latency: 5.06121 ms (enqueue 1.61682 ms)
[01/08/2023-10:47:32] [I] Average on 10 runs - GPU latency: 4.47092 ms - Host latency: 5.07136 ms (enqueue 1.61714 ms)
[01/08/2023-10:47:32] [I] Average on 10 runs - GPU latency: 4.48318 ms - Host latency: 5.08337 ms (enqueue 1.61753 ms)
[01/08/2023-10:47:32] [I] Average on 10 runs - GPU latency: 4.49258 ms - Host latency: 5.09268 ms (enqueue 1.61719 ms)
[01/08/2023-10:47:32] [I] Average on 10 runs - GPU latency: 4.50391 ms - Host latency: 5.10193 ms (enqueue 1.43665 ms)
[01/08/2023-10:47:32] [I]
[01/08/2023-10:47:32] [I] === Performance summary ===
[01/08/2023-10:47:32] [I] Throughput: 223.62 qps
[01/08/2023-10:47:32] [I] Latency: min = 5.00714 ms, max = 5.33484 ms, mean = 5.06326 ms, median = 5.05469 ms, percentile(90%) = 5.10596 ms, percentile(95%) = 5.12622 ms, percentile(99%) = 5.32755 ms
[01/08/2023-10:47:32] [I] Enqueue Time: min = 0.324463 ms, max = 1.77274 ms, mean = 1.61379 ms, median = 1.61826 ms, percentile(90%) = 1.64294 ms, percentile(95%) = 1.65076 ms, percentile(99%) = 1.66541 ms
[01/08/2023-10:47:32] [I] H2D Latency: min = 0.569824 ms, max = 0.60498 ms, mean = 0.58749 ms, median = 0.587158 ms, percentile(90%) = 0.591064 ms, percentile(95%) = 0.592346 ms, percentile(99%) = 0.599182 ms
[01/08/2023-10:47:32] [I] GPU Compute Time: min = 4.40759 ms, max = 4.73703 ms, mean = 4.46331 ms, median = 4.45447 ms, percentile(90%) = 4.50464 ms, percentile(95%) = 4.5282 ms, percentile(99%) = 4.72678 ms
[01/08/2023-10:47:32] [I] D2H Latency: min = 0.00585938 ms, max = 0.0175781 ms, mean = 0.0124573 ms, median = 0.0124512 ms, percentile(90%) = 0.013855 ms, percentile(95%) = 0.0141602 ms, percentile(99%) = 0.0152588 ms
[01/08/2023-10:47:32] [I] Total Host Walltime: 3.01404 s
[01/08/2023-10:47:32] [I] Total GPU Compute Time: 3.00827 s
[01/08/2023-10:47:32] [W] * GPU compute time is unstable, with coefficient of variance = 1.11717%.的场景和方式也有很多。除了本地离线测试,云端的也是需要的,举个压测--的例子:
*** Measurement Settings ***Batch size: 1Service Kind: TritonUsing "time_windows" mode for stabilizationMeasurement window: 45000 msecUsing synchronous calls for inferenceStabilizing using average latencyRequest concurrency: 1Client: Request count: 32518Throughput: 200.723 infer/secAvg latency: 4981 usec (standard deviation 204 usec)p50 latency: 4952 usecp90 latency: 5044 usecp95 latency: 5236 usecp99 latency: 5441 usecAvg HTTP time: 4978 usec (send/recv 193 usec + response wait 4785 usec)Server: Inference count: 32518Execution count: 32518Successful request count: 32518Avg request latency: 3951 usec (overhead 46 usec + queue 31 usec + compute 3874 usec)Composing models: centernet, version: Inference count: 32518Execution count: 32518Successful request count: 32518Avg request latency: 3512 usec (overhead 14 usec + queue 11 usec + compute input 93 usec + compute infer 3370 usec + compute output 23 usec)centernet-postprocess, version: Inference count: 32518Execution count: 32518Successful request count: 32518Avg request latency: 96 usec (overhead 15 usec + queue 8 usec + compute input 7 usec + compute infer 63 usec + compute output 2 usec)image-preprocess, version: Inference count: 32518Execution count: 32518Successful request count: 32518Avg request latency: 340 usec (overhead 14 usec + queue 12 usec + compute input 234 usec + compute infer 79 usec + compute output 0 usec)Server Prometheus Metrics: Avg GPU Utilization:GPU-6d31bfa8-5c82-a4ec-9598-ce41ea72b7d2 : 70.2407%Avg GPU Power Usage:GPU-6d31bfa8-5c82-a4ec-9598-ce41ea72b7d2 : 264.458 wattsMax GPU Memory Usage:GPU-6d31bfa8-5c82-a4ec-9598-ce41ea72b7d2 : 1945108480 bytesTotal GPU Memory:GPU-6d31bfa8-5c82-a4ec-9598-ce41ea72b7d2 : 10504634368 bytes
Inferences/Second vs. Client Average Batch Latency
Concurrency: 1, throughput: 200.723 infer/sec, latency 4981 usec模型的速度还是很重要的,平常我们可能习惯单压一个模型,也就是一个请求接一个连续不断请求这个模型然后看耗时以及qps,这样可以大概评估出一个模型的性能。但实际中要考虑很多种情况:
一般可以用很多压测工具对模型使用场景进行压测来观察模型的性能,但最好是实际去测一下跑一下,感受一下实际场景的请求量。
开始部署吧!
有了符合要求的模型、并且模型转换好之后,就可以集成到对应的框架中了。
本地部署其实考虑比较多就是推理后端,或者说推理框架。你要根据平台选择开源的或者自己研发的推理框架,平台很多(PC端、移动端、服务器、边缘端侧、嵌入式),一般来说有:
坑都不少,需要学习的也比较杂,毕竟在某一个平台部署,这个平台的相关知识相关信息也要理解,不过有一些经验是可以迁移的,因此经验也比较重要,什么AI部署、AI工程化、落地都是一个概念。能让模型在某个平台顺利跑起来就行。
确定好平台就可以确定推理框架了:
当然,如果你自己有实力或者有时间的话,也可以自己写一个推理框架,能学到很多东西!
本地部署
本地部署就是模型在本地跑,利用本地的计算资源。比如你的笔记本电脑有显卡,然后你想做一个可以检测手的软件,通过exe安装,安装好之后使用笔记本的显卡或者CPU去跑,这个模型会根据笔记本的硬件情况选择CPU还是GPU跑(当然你得自己写代码去检测有哪些硬件可以使用)。又比如说你有一个的服务器,插上一些摄像头完成一些工业项目,插上显卡在显卡上跑模型等等。
本地部署可以参考的项目:
本地部署需要考虑的一些点:
服务器部署相关
服务器模型部署和本地部署有类似的地方,但涉及到的知识点更多,面也更广。很多知识点和模型已经没什么关系了,我们其实也不需要深入理解架构方面的东西,简单了解一下即可,架构方面可以由公司内部专门的op去处理。
首先,可部署的模型种类更多,你有了服务器,一般来说基本都是的,基本什么模型都能跑,基本什么服务都会搞上去,甚至模型扔上去也行,当然性能不是最优的。除了模型的优化外,会涉及到模型的调度,自动扩缩,模型pack等等,大部分服务端相关的操作,不用我们参与,只需要提供模型或者前后处理代码即可,但有些我们是可以参与的。
我个人参与过一些服务端部署,基于K8s那套(仅仅是了解并没有实际使用过),说说咱们模型端需要做的事儿吧:
要学习的东西
相关参考:
嵌入式部署
嵌入式部署和本地部署类似,不过嵌入式的平台硬件相比普通电脑或者插加速卡的工业机器要弱不少。
一般都是嵌入式板卡一类的,比较好的有英伟达的 orin系列,比较差的有单片机stm32这类。
嵌入式或者说手机端部署可以说是差不多,特点就是计算资源比较紧张,功耗往往都给的很低,性能不强的同时要求很多模型需要达到实时,这个对算法工程师和算法优化工程师来说挑战不小,差不多可以达到扣QPS这个级别(为了提升模型的几个QPS努力几个月),不像服务端动不动就100多Q。嵌入式端简单转一个模型可能只有10来q,想要达到24q也就是实时的级别可能需要花不小的功夫。
举几个大家经常玩的嵌入式平台:
特点:
参考:
多模型混合部署
有时候会有很多模型部署到同一张显卡上、或者部署到同一个AI加速卡上的情况,而显卡或者说加速卡,资源都是有限的(多个卡同理)。
比如英伟达的显卡,有限的显存和计算资源(SM、 core、DLA);比如高通的AI处理器,有限的计算资源(HVX、HMX、NPU);
这个在服务器级别和嵌入式级别都会有需求。一般来说,提供加速卡的厂商也会提供相应的工具供你搜索多模型部署的最优配置,这种在实际场景中经常会用到,因为不大可能就一个模型在跑。比如自动驾驶场景中,多路摄像头每路摄像头接一个模型去跑,比如检测红绿灯的、检测行人的,而这些模型一般都会在一个加速卡上跑,
如何合理分配这些资源,或者说如何使多个模型比较好的运行在这些资源上也是需要考虑的。简单预估可以,比如一个模型单张卡压测,另一个模型,可以简单预估两个模型一起qps各缩减一半。不过其实最好的是有工具可以实际压测,通过排列组合各种配置去实际压测这些模型的各种配置,选择一个最大化两个模型QPS或者的方法。当然也可以通过硬件划分资源来执行每个模型能获取到的实际算力,再细致层面你可以通过控制每个op->执行发到内核通过内核进行控制每个的执行优先级来控制模型。
先回来最简单的在一张卡上或者有限资源内如何搜寻最优配置,最好还是有工具,没有工具只能自己造了。
闭源的在你使用硬件厂商提供的工具中就知道了,比如你使用高通的板子,高通会提供你很多软件库,其中有一个可以分析多个模型或者一个模型在特定资源下的最高qps以及最低供你参考。同理其他硬件厂商也是一样的。
开源的可以看看的:
模型加密
先说模型加密有没有这个需求,如果没有这个需求就没必要哈,模型加密主要看竞对的能力以及有多大意愿破解你的模型hh。
我知道的模型加密的几个方式:
很多推理框架也提供了方便模型加密的接口:
PS:加密模型无非就是想让破解方花点功夫去破解你的模型,花多少功夫取决你花多少功夫去加密你的模型;照这样说修改模型结构也可以达到加密模型的目的,比如模型融合,天然会实现对模型的op融合、权重合并,很多op(conv+bn+relu)转成之后结构已经面目全非了,权重也融合的融合、去除的去除,想要把模型权重提取出来也是挺难得
模型转换那些事儿
模型转换是很常见的事情,因为训练平台和部署平台大概率是不一样的,比如你用训练,但是用去部署。两者模型结构实现方式不一样,肯定会涉及到模型移植的问题,模型转换,又或是模型移植,都是苦力活。又或者你不训练模型,拿到的是别人训练的模型,如果想在自己的平台部署,你的平台和人家的模型不在一个平台,那就得模型转换了,因为你拿到的模型可能是各种格式的:
还是可以参考,看下有多少模型列表,之前有提到过:
不过如果不换平台的话,可以不考虑模型转换。
模型转换是个经验活,见得模型多了,就知道每个模型结构的特点以及转换特点。转换起来也就得心应手,少踩很多坑了。
常干的事儿
首先是看模型结构,在上文中“自己造模型”这一节中已有提及。不论是什么样的模型结构,模型肯定都是按照一定的规则组织的,模型结构和模型权重都在里头,怎么看各凭本事了。
总结一些和模型相关的例子,有更新会放这里:
排查各种问题
转模型和开盲盒一样,不能保证模型转完精度一定没问题,要做很多检查。
模型转换后一般要做的事儿 常见的问题 模型优化那些事儿
模型优化也是老生常谈的事情,小到优化一个op,大概优化整个推理,可以干的事情很多。
之后会总结一些常用的优化技巧在这里,先埋坑。
合并、替换op算子
很多框架在导出的时候就会自动合并一些操作,比如torch.onnx在导出conv+bn的时候会将bn吸到前面的conv中,比较常见了。
但也有一些可以合并的操作,假如框架代码还没有实现该则不会合并,不过我们也可以自己合并,这里需要经验了,需要我们熟知各种op的合并方式。
可以自己合并一些操作,比如下图中的+Add+BN,是不常见的的,如果自己愿意的话,可以直接在ONNX中进行合并,把权重关系搞对就行。
列举一些合并的例子,总之就是将多个op合成大op,节省计算量以及数据搬运的时间:
多路合并
既可以融合一些算子,当然也可以替换一些算子:
蒸馏、剪枝
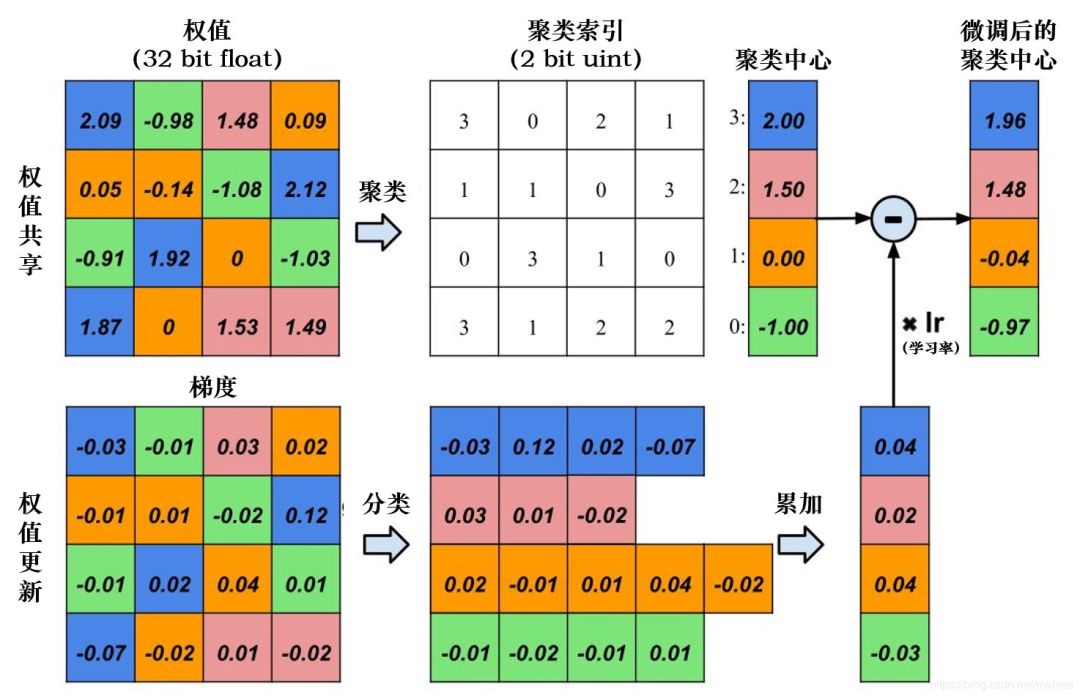
剪枝和蒸馏都是模型层面的优化,如果是稀疏化剪枝则会涉及到硬件层面。
剪枝的目的就是将在精度不变的前提下减少模型的一些层或者通道或者权重数量等等,甚至可以剪枝。可以节省计算量并且减少模型的体积,对于大模型来说是很有用的,一般来说剪枝后的模型比未剪枝的同等size大小精度更高。
具体的可以参考这篇:to prune or not to prune the of for model 。
剪枝的方法可以看zomi总结的ppt(来自 ):
蒸馏可以使同结构的小模型精度提升接近大模型的精度。
总结
剪枝类似于模型搜索,如果直接NAS的话,就没有必要剪枝了。
参考 量化
量化目前比较成熟,也有很好的教程(PPQ),很成熟的库(PPQ),新手入门建议直接看PPQ,跟着教程来大概就知道量化的很多细节了。
要学习的知识点有:
但是需要注意,不是所有模型、所有op都适合量化:
注意点:
参考 算子op优化
算子优化就是无底洞,没有尽头,要学习的东西也很多,之前我也简单深入地探索过这个领域,只不过也只是浅尝辄止,优化完就立马干其他活了。这里也不班门弄斧了,涉及高性能计算的一些入门问题,可以看下这个的回答:
大部分优化op的场景,很多原因是原生op的实现可能不是最优的,有很大的优化空间。
比如这个操作,原生的实现比较慢,于是就有了优化空间:
同理,很多CUDA实现的OP可能不是最优的,只有你有精力,就可以进行优化。也要考虑是这个优化值不值,在整个模型中的占比大不大,投入产出比怎么样。
对于CUDA还好些,资料很多,很多op网上都有开源的不错的实现(尤其是gemm),抄抄改改就可以了。
不过对于一些没有CUDA那么火的平台或者语言,比如arm平台的neon或者npu,这些开源的算子实现少一些,大部分需要自己手写。分析模型哪些op慢之后,手动优化一下。
知乎上也有很多优化系列的教程,跟着一步一步来吧:
有几种可以自动生成op的框架:
调优可视化工具
可视化工具很重要,无论是可视化模型还是可视化模型的推理时间线。可以省我们的很多时间,提升效率:
还要了解很多推理框架/AI编译器
本来这节的小标题是“还要会很多推理框架/AI编译器”,但感觉很不现实,人的精力有限,不可能都精通,选择自己喜欢的、对实际平台有相应提升的推理框架即可。
这里总结了一些AI编译器:
ONNX
ONNX不多说了,搞部署避免不了的中间格式,重要性可想而知。
Open (ONNX) is an open that AI to the right tools as their . ONNX an open for AI , both deep and ML. It an graph model, as well as of built-in and data types. we focus on the for ().
需要了解ONNX模型机构组成,和的一些细节;能够根据要求修改ONNX模型;能够转换ONNX模型;同时也需要知道、了解ONNX的一些坑。
修改ONNX模型
修改模型,如果直接使用官方的接口会比较麻烦,建议使用onnx-或者尝试尝试onnx-。
调试ONNX模型
埋坑。可以看知乎中相关文章。
ONNX学习相关建议
多找些ONNX的模型看看,转换转换,看看相关的issue
也可以加入大老师的群,群里很活跃很多大佬,相关ONNX问题大老师会亲自回答
相关文章: TVM
占坑。
不必多说,先占坑。
自定义插件
如果模型中保存不支持的算子,就需要自己实现cuda操作并且集成到中。
现在也有很多可以生成插件的工具:
相关资料:
简单好用的对模型友好的C++推理库。
借助 火了一下,其加速 的效果比要好不少。
我自己测试了一个res50的模型,利用-8.5.1.7和-0.1dev转化后简单测试了下速度,精度都是FP16,显卡是A4000。
24
2.07885 ms
3.49877 ms
1.36401 ms
2.38946 ms
看来很有潜力。
还有很多,待续
慢慢补充吧。
高性能计算
高性能计算和之前提到的op优化是强相关的,之前提到的这里就不多提了。
根据自己的场景和爱好熟悉一门并行语言是比较好的,而对于我来说,CUDA用的比较多,所以就学习CUDA了。如果你不知道该学什么,CUDA也很适合作为入门的并行计算语言,资料很多,使用场景丰富,相关讨论也很多。
如果你工作中使用的平台不是,则需要学习对应平台的相关技术栈。
未完待续。
自己的库
自己部署过程这么多,也积累了很多代码脚本,找时间整理下,供大家参考学习。
后记
这篇文章会一直更新总结,因为公众号的限制只能一篇一篇发(后续有更新说明也会发在留言中。)。所以这个清单会放到博客、、或者其他有精力之后更新的平台(知乎啥的)继续写,自己学习总结用,也可以供大家参考学习。关于链接也会在之后发出来,有兴趣的同学可以看看,目标是总结一个学习“部署”的路线吧,平民版的!
趁着新的一年到了(貌似是2023年第一篇),也给自己立个小目标吧,2023年文章输出30篇以上,尝试尝试换种方式搞一些相关的东西(视频、软件),最近好玩的太多了。
后续的文章也不会一写一大坨了,写的短一些,分篇章感觉会好一些,当然质量还会保证。
国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!
【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;
添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称