对链表进行插入排序
给定单个链表的头head,使用插入排序对链表进行排序,并返回排序后链表的头。
插入排序算法的步骤:
插入排序是迭代的,每次只移动一个元素,直到所有元素可以形成一个有序的输出列表。每次迭代中,插入排序只从输入数据中移除一个待排序的元素,找到它在序列中适当的位置,并将其插入。重复直到所有输入数据插入完为止。
下面是插入排序算法的一个图形示例。部分排序的列表(黑色)最初只包含列表中的第一个元素。每次迭代时,从输入数据中删除一个元素(红色),并就地插入已排序的列表中。
对链表进行插入排序。
示例 1:
输入: head = [4,2,1,3] 输出: [1,2,3,4]
示例2:
输入: head = [-1,5,3,4,0] 输出: [-1,0,3,4,5]
关键词1:插入排序
遍历数组,把遍历到的数字插入到有序序列的合适位置,形成一个新的有序序列
关键词2:链表
任务:
对链表做插入排序
任务1:遍历链表
任务2:找到合适的位置,插入节点
任务1:
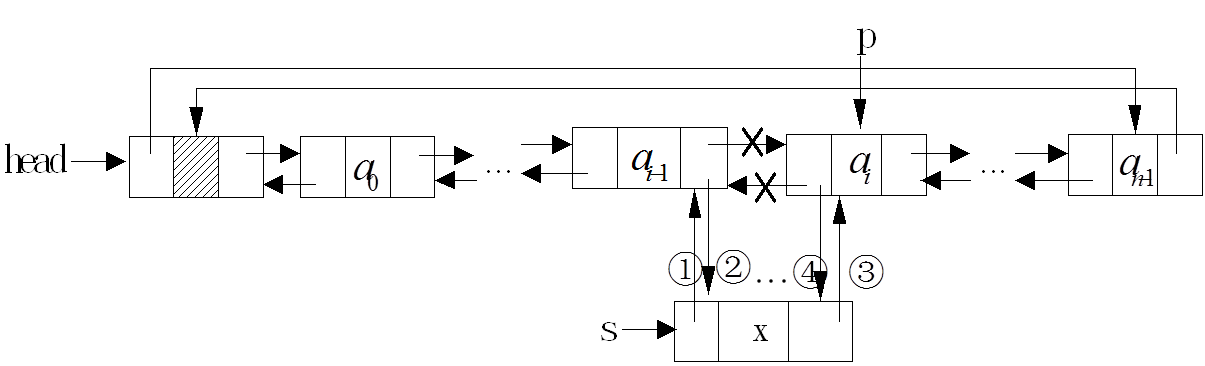
遍历链表。只需要一个cur指针,指向有序序列之后的第一个节点,将该节点插入到合适位置后,指针后移一位。直至遍历到空节点。
同时,维护一个last指针,指向有序序列的最后一个数字。
当然,最好设置一个空的头结点dinny。避免,在节点v需要插入到头结点head之前的时候,做多余的处理。
dinny=ListNode()
dinny.next=head
last = head #有序序列的最后一个
cur = last.next#待排序的第一个任务2:
寻找合适的位置,进行插入
对于数组来说,因为有随机访问的特点,可以从后往前遍历,找到一个适合节点v的位置。但是单链表只能从前往后遍历,找到第一个大于节点v的节点m,并将节点v插入到节点m之前。
寻找节点v的合适位置的步骤如下:
1、设置一个用于判断大小的临时指针,该指针指向头结点
2、比较的下一个节点和v的大小
3、如果的下一个节点小,说明节点v要插到节点的下一个节点的后边位置,指针后移,直至找到的下一个节点的值大于v的值;如果v的小,说明找到了第一个比v大的节点,将v插在该节点的前面。该位置是节点的后边和节点的下一个节点的前面。
至于为什么比较的下一个节点和v的大小,而不是直接比较v和节点的大小。是因为,在单链表中插入链表要知道其前一个节点,如果直接比较的话,需要重新寻找节点的前一个节点。当然可以在设置一个指针,指向的前一个节点。但是太麻烦了,还不如用的下一个节点作比较。
在遇到cur和last已经处于一个有序的情况下,只需要将last和cur后移一格位置即可。这样可以,减少从头遍历链表,以寻找合适位置的时间。
if cur.val>=last.val:last=curcur=last.next以下是完整的代码:
class Solution:def insertionSortList(self, head: Optional[ListNode]) -> Optional[ListNode]:dinny=ListNode()#设置一个空的头结点dinny.next=headlast = head #有序序列的最后一个cur = last.next#待排序的第一个while cur :if cur.val>=last.val:last=curcur=last.nextelse:comparetemp=dinny #插入时的临时节点,用来做判断while cur.val>=comparetemp.next.val and comparetemp.next != cur:comparetemp=comparetemp.next#找到合适的位置了,开始插入last.next=cur.nextcur.next=comparetemp.nextcomparetemp.next=curcur = last.nextreturn dinny.next打家劫舍
是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
给定一个代表每个房屋存放金额的非负整数数组,计算你不触动警报装置的情况下,一夜之内能够偷窃到的最高金额。
示例 1:
输入:[1,2,3,1] 输出:4 解释:偷窃 1 号房屋 (金额 = 1) ,然后偷窃 3 号房屋 (金额 = 3)。偷窃到的最高金额 = 1 + 3 = 4 。
示例 2:
输入:[2,7,9,3,1] 输出:12 解释:偷窃 1 号房屋 (金额 = 2), 偷窃 3 号房屋 (金额 = 9),接着偷窃 5 号房屋 (金额 = 1)。偷窃到的最高金额 = 2 + 9 + 1 = 12 。
提示:
任务:
找到一串序列,使得其金额最大化,要求序列中的元素不相邻
对于某个房子,有两种可能:偷和不偷
1、偷。意味着他的前一个房子不能被偷,此时的最大金额是,不偷前一个房子的最大金额加上他自己本身。
2、不偷。意味着他的前一个房子可以被偷或者不被偷。此时的最大金额是,前一个房子的能承受的最大金额
所以考虑到这些,可以使用动态规划的方法。
维护一个数组dp。dp[i]表示,前i个房子能偷到的最大金额。
对于dp[i]来说,有两种选择:偷和不偷。
偷:dp[i-2]+nums[i] 不偷:dp[i-1] 选择两者最大值就好了
边界条件为:
i==1时,只有一间房子,必然偷 dp[0]=nums[0]
i==2时,只有两间房子,选择最贵的一间偷 max(nums[0],nums[1])
class Solution:def rob(self, nums: List[int]) -> int:if not nums:return 0n = len(nums) #有几间房屋if n==1:return nums[0]dp = [0]*ndp[0]=nums[0]dp[1]=max(nums[0],nums[1])for i in range(2,n):dp[i]=max(dp[i-2]+nums[i],dp[i-1])return dp[n-1]李沐深度学习笔记
函数将线性模型输出的实数域映射到[0, 1]表示概率分布的有效实数空间
=多标签分类问题=多个正确答案=非独占输出(例如胸部X光检查、住院)。构建分类器,解决有多个正确答案的问题时,用函数分别处理各个原始输出值。
函数是一种函数,它将任意的值转换到[0,1]之间。
=多类别分类问题=只有一个正确答案=互斥输出(例如手写数字,鸢尾花)。构建分类器,解决只有唯一正确答案的问题时,用函数处理各个原始输出值。函数的分母综合了原始输出值的所有因素,这意味着,函数得到的不同概率之间相互关联。
函数是二分类函数在多分类上的推广,目的是将多分类的结果以概率的形式展现出来。如图2所示,直白来说就是将原来输出是3,1,-3通过函数一作用,就映射成为(0,1)的值,而这些值的累和为1(满足概率的性质),那么我们就可以将它理解成概率,在最后选取输出结点的时候,我们就可以选取概率最大(也就是值对应最大的)结点,作为我们的预测目标。
的含义就在于不再唯一的确定某一个最大值,而是为每个输出分类的结果都赋予一个概率值,表示属于每个类别的可能性。
引入指数函数:指数函数的曲线斜率逐渐增大虽然能够将输出值拉开距离,但是也带来了缺点,当输出值非常大的话,计算得到的数值也会变的非常大,数值可能会溢出。
逻辑回归:两分类问题,是单一输出的回归,只输出1(有时候是-1),那么剩下的就是n-(1的个数),他是回归的一个特例。
为什么不在函数中除以len?
在读batch的时候,最后一批的样本很有可能是缺斤少两的(=100,但最后一批只有20个样本)。此时,除以len(y)是除以20,之前都是除以100的。所以,应该要得到所有正负例之后,再除以总数。
感知机
感知机就是一个二分类问题
只有xw+b大于0,且有余量的时候,才是分类正确。(输出1,而不是-1)
r为数据大小,r很大的话收敛很慢。p为数据好不好,好的话很快收敛
不论怎么切,都不能把所有红色都分一边,把所有绿色都分另一边
解决办法:多层感知机
激活函数为什么要非线性?
如果激活是线性的话,对线性结果做线性处理,最终的结果还是线性结构。那多层感知机模型就会变成一个简单的线性模型。
一般都是,上一层的个数小于下一层。因为大部分情况都是很大的输入类别,和很小的输出类别(10种衣服、3种动物之类的)所以隐藏层要处于慢慢压缩 ->64->32->16.....如果一次性压缩的话(128->2)会损失很多信息
或者在底层进行一次扩张 128->258->128->64.......扩张可以进行细节的一些处理