用pyhtml2pdf(python)包自动从html生成pdf
2.基于的拓展
我们使用发现并没有提供生成pdf格式的选项,这里我们基于其代码进行拓展:
.py:
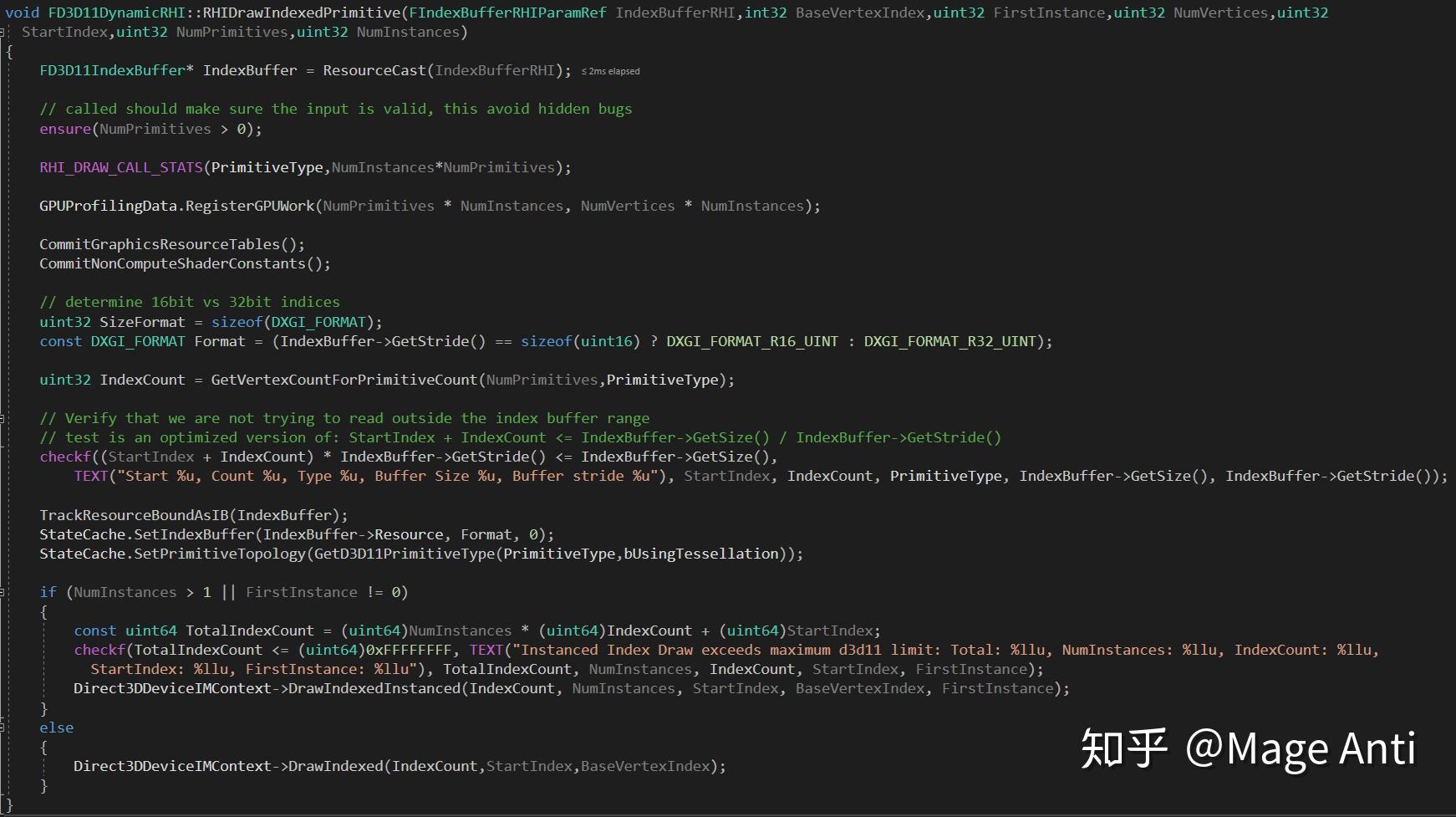
from pyhtml2pdf import converterdef convert(source: str, target: str, timeout: int = 2, print_options={}, install_driver: bool = True):'''将一个html文件转换为pdf文件:param 要转换的html文件:param 保存PDF文件的路径:param 超时时间:param 选项字典'''result = converter.__get_pdf_from_html(source, timeout, install_driver, print_options)with open(target, 'wb') as file:file.write(result)
这里主要通过对pdf生成提供更多选项,代码示例:
import my_converter
import osif __name__ == '__main__':path = os.path.abspath("index.html")my_converter.convert(f'file:///{path}', 'sample.pdf',print_options={'landscape': False, # 格式'displayHeaderFooter': False, # 页码'printBackground': False, # 背景'preferCSSPageSize': True,'marginTop': 0.39370078740157,'marginBottom': 0.39370078740157,'marginLeft': 0.39370078740157,'marginRight': 0.39370078740157,'paperWidth': 8.26,'paperHeight': 11.4,})
这里是浏览器一个默认的A4纸打印格式,由于选项中数字选项均以英寸为单位,所以有些奇怪,当然可以根据需要修改选项,其中1米=39.英寸。
查看默认值或添加更多选项,请参考 协议官网:#-
3. 多线程生成
由于中生成pdf文件为串行程序,且每生成一个文件均要关闭一次浏览器驱动,所以生成速度非常慢,这里添加了多线程选项和封装了一个多个html一起转换的方法。
'''
my_converter.py
'''
from pyhtml2pdf import converter
from queue import Queue
import threading
import base64
import json
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support.expected_conditions import staleness_of
from webdriver_manager.chrome import ChromeDriverManagerA4 = {'landscape': False, # 格式'displayHeaderFooter': False, # 页码'printBackground': False, # 背景'preferCSSPageSize': True,'marginTop': 0.39370078740157,'marginBottom': 0.39370078740157,'marginLeft': 0.39370078740157,'marginRight': 0.39370078740157,'paperWidth': 8.26,'paperHeight': 11.4,}def convert(source: str, target: str, print_options={}, timeout: int = 2, install_driver: bool = True):'''将一个html文件转换为pdf文件:param 要转换的html文件:param 保存PDF文件的路径:param 选项字典:param 超时时间'''result = converter.__get_pdf_from_html(source, timeout, install_driver, print_options)with open(target, 'wb') as file:file.write(result)html_queue = Queue(5000)def setQueue(sources: [str]):for enum in sources:html_queue.put(enum)def concertForHtmls(sources_and_targets: [(str, str)], print_options={}, thread_number: int = 1, timeout: int = 2, install_driver: bool = True):setQueue(sources_and_targets)for i in range(thread_number):t = ConverterMan(print_options, timeout, install_driver)t.start()class ConverterMan(threading.Thread):def __init__(self, print_options, timeout, install_driver, *args, **kwargs):super(ConverterMan, self).__init__(*args, **kwargs)self.timeout = timeoutself.print_options = print_optionswebdriver_options = Options()webdriver_prefs = {}self.driver = Nonewebdriver_options.add_argument('--headless')webdriver_options.add_argument('--disable-gpu')webdriver_options.add_argument('--no-sandbox')webdriver_options.add_argument('--disable-dev-shm-usage')webdriver_options.experimental_options['prefs'] = webdriver_prefswebdriver_prefs['profile.default_content_settings'] = {'images': 2}if install_driver:self.driver = webdriver.Chrome(ChromeDriverManager().install(), options=webdriver_options)else:self.driver = webdriver.Chrome(options=webdriver_options)def run(self):while True:if html_queue.empty():self.driver.quit()print("over!!!")breakhtml_path, pdf_path = html_queue.get()try:self.driver.get(html_path)try:WebDriverWait(self.driver, self.timeout).until(staleness_of(self.driver.find_element_by_tag_name('html')))except TimeoutException:calculated_print_options = {'landscape': False,'displayHeaderFooter': False,'printBackground': True,'preferCSSPageSize': True,}calculated_print_options.update(self.print_options)resource = "/session/%s/chromium/send_command_and_get_result" % self.driver.session_idurl = self.driver.command_executor._url + resourcebody = json.dumps({'cmd': "Page.printToPDF", 'params': calculated_print_options})response = self.driver.command_executor._request('POST', url, body)if not response:raise Exception(response.get('value'))result = response.get('value')data = base64.b64decode(result['data'])except Exception as b:print(html_path + "convert error!--" + str(b))continueelse:with open(pdf_path, 'wb') as file:file.write(data)print(pdf_path + " finish!")该py文件提供了两种生成方式,一种为单个html转pdf方法,前面已经做过了介绍。第二种方法用于多个html转pdf,并提供了多线程选项(默认值为1)。注意这里的html处理队列长度设置为了5000,需要更多的话自行调整代码。此外封装了A4纸默认边距的打印格式。
使用该需提供要转换的html和要转成pdf的绝对路径列表: [(str, str)],使用示例:
import my_converter
source_and_target = []
for i in range(1, 100):source = os.path.abspath('html/' + str(i) + '.html')target = os.path.abspath('pdf/' + str(i) + '.pdf')source_and_target.append((source, target))
#开启10个线程,转换成A4格式
my_converter.concertForHtmls(source_and_target, my_converter.A4, 10)