「重磅综述」多智能体强化学习算法理论研究「AI核心算法」
此外,本文还给出了一些MARL理论的新观点,包括-form games, MARL with ,MARL in the mean-field ,(non-) of -based for in games, etc
1
MARL 算法的面临以下问题
2 MARL
Image
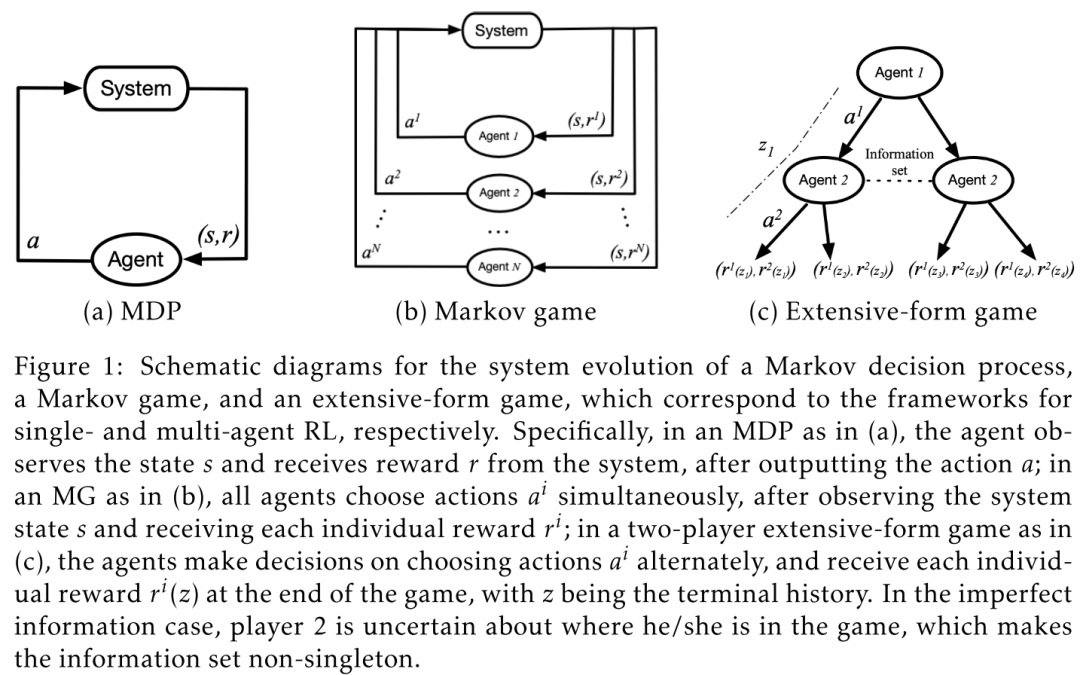
2.1 / Games
2.1. Games由五元组
定义,其中
代表
个 ,
代表所有 观测到的状态空间,
代表 agent
的动作空间和奖励,
为 。
值函数
是联合策略
的函数,联合策略定义为
, 对于每一个联合策略
和状态
因此,MG的解决方案不同于MDP,因为每个agent的最佳性能不仅受其自身策略的控制,而且还受博弈中所有其他玩家的选择的控制。这方面最重要的理论就是纳什均衡。
2.3.Nash of Games是一个服从下述不等式的联合策略
,对任意
:
纳什均衡描述了一个均衡策略
,从该均衡点上没有任何agent有任何偏离的动机。换言之,策略
is the best- of
,但这样的点通常可能并不唯一。大多数MARL算法都试图收敛到这样的平衡点。
在完全合作的设定中,所有通常共享一个 ,
。该模型每一个 agent 的值函数和Q函数均相同,因此可以将其看作一个决策智能体并应用 agent RL算法。显然这样做的全局合作最佳状态就能够达到博弈纳什均衡。
另一种合作模型是team- ,
。平均奖励模型,它允许agent商之间存在更多的异质性。此外还可以保护之间的隐私,并促进 MARL算法的发展。这种异质性必须将通信协议 整合到MARL中,并需要对通信的效率 - MARL 进行分析。、
完全竞争的MARL一般被建模为zero-sum games 马尔可夫零和博弈,
。为了便于算法的设计和分析,大部分文章只关注两个之间的竞争,一个agent的奖励正好是另一个的损失。此外,零和博弈还被用于 ,因为阻碍agent学习过程的可以被抽象为在博弈中总是与agent对抗的虚拟对手。
Mixed
混合设定一般也被称作-sum一般和博弈,其对的目标和关系没有任何限制。每个agent都是自私的,他们的奖励可能与他人的利益冲突。博弈论中的均衡解决方案概念,例如Nash均衡,对为此通用设置开发的算法具有最重要的影响。
此外,还有一些研究包同时含 fully and com- 的设置,例如,两个零和 团队,每个团队中都有 agent的情况。
2.2 -Form Games
马尔可夫博弈的问题在于:只能处理完全观察到的情况,每个智能体对整个系统的状态和动作都有很清晰的认识。将马尔可夫博弈扩展到部分可观测的情况可能是适用的,但是即使在合作环境下,这也具有挑战性。
相反,-form games 框架就可以处理信息不完备的多智能体决策问题。该框架植根于计算博弈论,并已被证明可以在温和条件下允许多项式时间复杂度的算法
2.4.-form games 定义为
部分可观测反映在智能体无法区分同一信息集中的历史记录。此外,我们始终假设博弈是回忆完备的 ,即每个agent都记住 和导致其当前信息状态的动作的顺序。更重要的是,根据著名的库恩定理 Kuhn’s ,在这样的假设下,找到纳什均衡集,就足以将推导约束为 集,后者将每个信息集
映射到
上的概率分布。对于任何
,令
是 agent i的 集。
的联合策略由
表示,其中
是的策略。对于任何历史h和任何联合策略π,我们将π下h的到达概率 reach 定义为
它指定当所有agent都遵循π时创建h的概率。类似地,我们将信息状态 s 在π 下的到达概率定义为
。Agent i 的 为
。为简单起见,以
来表示。由此可以给出 -form game 框架下的纳什均衡定义。
2.5.
-Nash of an -form game 表示为
的联合策略
,对于每一个智能体:
时,即为纳什均衡。
-form games 一般用于建模 non- 。更重要的是,不同信息结构的设置也可以通过-form game来表征。特别是,一个信息完备的博弈是每个信息集都是一个单例的博弈,即对于任何
。信息不完备的博弈是存在
的博弈。换句话说,在信息不完善的情况下,用于决策的信息状态代表了不止一种可能的历史,而agent无法区分它们。
to Games
对于同时移动的马尔可夫博弈,其他智能体对动作的选择对于某一个智能体是未知的,因此这导致可以将不同的历史汇总为一个信息状态s。这些博弈中的历史记录就是联合动作的序列,而累计折扣奖励将在博弈结束时实例化。相反,通过简单地将状态
时agent
设置为
,-form game 简化为具有 state- 的动作空间的马尔可夫博弈。
3 3.1 Non- Goals 目标不唯一
不同智能体间,学习的目标不唯一。被设计为收敛到NE的学习动力对于实际的来说可能是不合理的。, the goal may be on the best for a given agent and a fixed class of the other in the game。
用(达到平衡点)作为MARL算法分析的主要性能标准还存在争议。因为 et al. (2006) 证实基于价值的MARL算法无法收敛到一般性和马尔可夫博弈的平稳NE,这激发了 的新解决方案概念。在该概念下,agent 通过一系列 (即不收敛到任何NE策略)严格循环。或者,将学习目标分为和两个方面,前者在给定预定义的、有针对性的对手算法的情况下,确保算法收敛,而后者则要求在其他主体保持稳定时收敛到 best-。如果所有agent都既稳定又理性,则在这种情况下自然会融合到NE
此外,的概念为捕捉 agent 的 引入了另一个角度,与 the best 相比,它衡量了算法的性能(和,2001;,2005)。渐近平均零后悔的No- 保证了某些博弈的均衡收敛性(Hart和Mas-,2001;,2005;等,2008),这从根本上保证了该 agent 不会被其他 agent 利用。
Kasai等(2008),等(2016),Kim等(2019)研究了 to 的方式,以便 更好地进行协调。对通信协议的这种关注自然激发了最近对高通信效率的MARL的研究(Chen等,2018; Lin等,2019; Ren和Haupt,2019; Kim等,2019)。其他重要目标包括如何在不过度拟合某些 agent 的情况下进行学习(He等人,2016; Lowe等人,2017; 等人,2018),以及如何在恶意/对抗性或失败/功能失调的情况下稳健学习。(Gao等,2018; Li等,2019; Zhang等,2019)。
3.2 Non- 非平稳
很明显,由于多智能体动作结果的相互影响,agent 需要考虑其他 的 并相应地适应 joint ,导致了单智能体的马尔可夫假设不适用。
关于这方面的知识,可见 -Leal 2017年的综述,该文章中特别概述了如何通过最新的 MARL 学习算法对其进行建模和解决。
3.3 Issue 可扩展性
为了处理非平稳性,每个 agent 都可能需要考虑联合动作空间,然而联合行动的规模会随着智能体的增加而成倍的增加。这也被称为MARL的 (-Leal et al.,2018)。
一种可能的补救措施是,另外假设关于动作依赖的价值或奖励函数的因式分解结构。
参见(2002a,b);Kok和(2004)提出了原始的启发式思想,以及最近的 et al. (2018); et al. (2018) 等。直到最近才建立了相关的理论分析**(Qu and Li,2019)**,该模型考虑了一种特殊的依赖结构,并开发了一种可证明的基于模型的收敛算法(不是RL)。
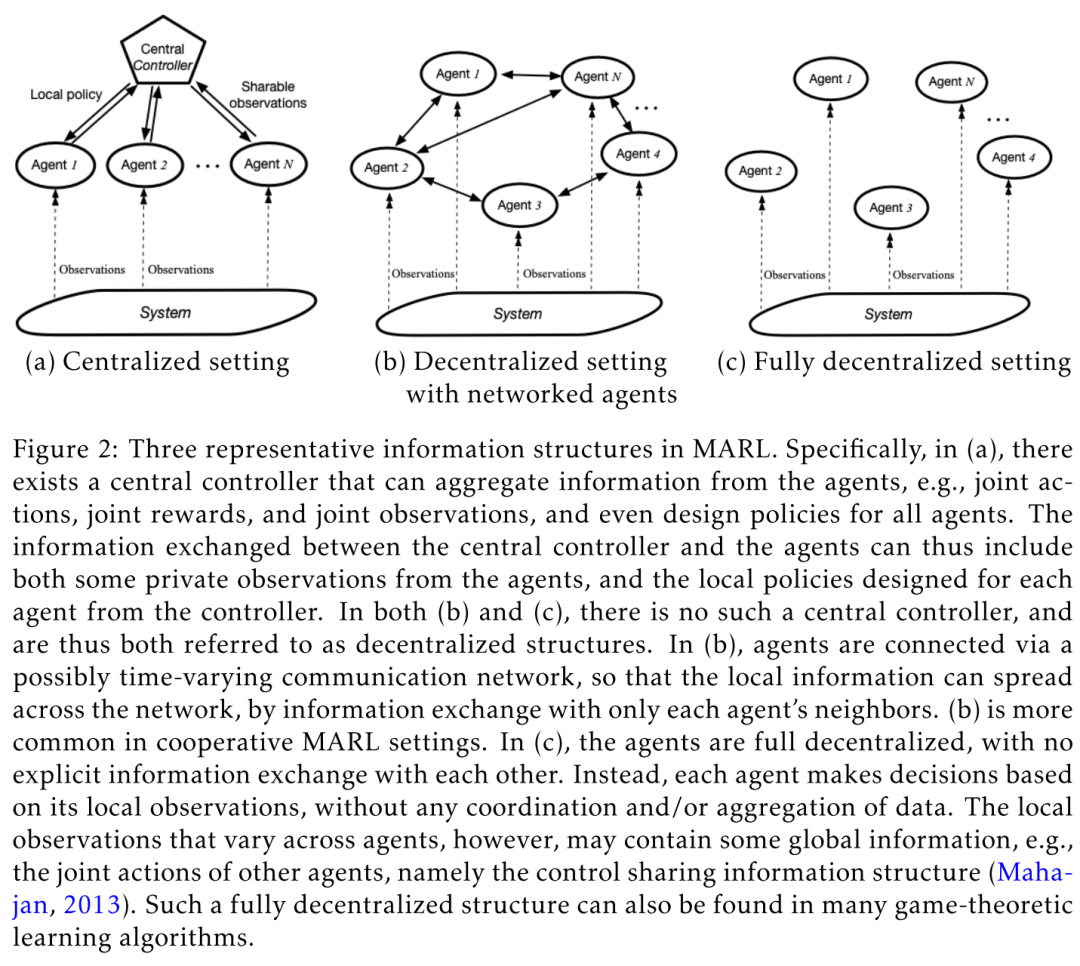
3.4 不同的信息结构
Image
中心化 MARL:大量工作都假设存在一个 ,该中央控制器可以收集信息,例如联合动作,联合奖励和联合观察,甚至为所有agent设计策略。( et al., 2004; and Amato, 2014; Lowe et al., 2017; et al., 2017; Gupta et al., 2017; et al., 2018; and , 2018; Chen et al., 2018; et al., 2018)。这种结构催生了流行的集中学习,分散执行 ---的学习方案,该方案源于为部分观察的环境进行规划的工作,即Dec-POMDP。然而,通常这种中央控制器在许多应用中并不存在,除了那些可以轻松访问模拟器的应用之外,例如 video games 和 。
完全去中心 MARL:为了解决独立学习中的收敛问题,通常允许通过通信网络与邻居交换/共享本地信息。(Kar et al., 2013; Macua et al., 2015, 2017; Zhang et al., 2018,a,b; Lee et al., 2018; Wai et al., 2018; Doan et al., 2019; et al., 2019; Doan et al., 2019; Lin et al., 2019)。我们将此设置称为a one with 。这样一来,就可以在这种情况下进行收敛的理论分析,其难度介于 SARL 和通用MARL算法之间。
4 MARL with
本文仅聚焦 的情况下的详细理论,如果想了解 和 Mixed ,可以自行阅读标题下的链接。由于 Agent 的情况过于 naive,本文就不提了,我比较感兴趣的是 with ,这也是最符合实际的模型。
with
在许多实际的multi-agent系统中, 并不总是同质的。
可能有不同的偏好,即奖励函数,这时要让团队的平均回报
最大化。有时奖励函数不能与其他 共享,因为每个 agent 的偏好都是独立的。
这种设定常出现于诸如传感器网络(和Nowak,2004),智能电网(Dall'Anese等,2013;Zhang等,2018a),智能交通系统(Adler和Blue,2002)和机器人技术(Corke等人,2005)等场景。
如果使用 的方式,上述大多数MARL算法都可直接适用,因为 可以收集平均奖励,并将信息分发给所有 。但是由于成本、可扩展性或健壮性方面的考虑,在大多数上述应用中可能都不存在这种控制器(和Nowak,2004;Dall’Anese等,2013;Zhang等,2019)。
取而代之的是, 可以通过随时间变化且稀疏的通信网络与邻居共享/交换信息。
如何仅通过网络访问本地和邻近信息来达到最优的联合策略。具有网络 的MARL 想法可以追溯到 et al.(2009)。第一个可证明收敛的MARL算法是Kar等人提出的(2013),将 + 的思想纳入标准的Q学习算法,产生了具有以下更新的QD-算法
其中:
Q- 相比,QD- 在步长上增加了 项,该项捕捉了来自其邻居的Q估计值的差异。With on the , 算法可以保证收敛到表格形式下的最优 Q 函数。
对于 -based 方法可见这篇文章Fully multi-agent with ,它提出了完全去中心化的 multi-agent actor-。每个 agent 通过某个参数
来参数化其自己的政策
,首先得出回报的策略梯度:
是在联合策略
下对于
的全局值函数。很明显,在这个设定中,单个 agent 是没有办法估计这个全局值函数的。因此,我们提出了如下的 -based TD 用于 step 来用局部
来估计全局:
请注意,上述收敛保证都是渐近的,即算法随着迭代次数达到无穷大而收敛,并且仅限于线性函数近似的情况。当使用有限迭代和/或样本时,这无法量化性能,更不用说在利用诸如 DNN 之类的非线性函数时了。
当考虑更通用的函数逼近进行有限样本分析时,详见- for fully multi-agent 和Batch 的batch RL算法,特别是the -Q (FQI)的去中心化变体。
我们研究了FQI变体,既用于与网络代理的协作环境,也用于与两个团队的网络代理的竞争环境。在前一种设定中,所有智能体都通过将非线性最小二乘法与目标值拟合来迭代更新全局Q函数估计。
让
代表 Q函数的近似函数,
为大小为n的可用于所有 的 batch 数据集,
代表每个 agent 专有的局部奖励,
为 local value。然后,所有agent通过求解下式找到一个共同的Q函数估计:
由于
只有agent i 知道, 因此其符合 / 的公式。
另一个问题:由于是对分布式系统进行有限次迭代,之间可能无法达成共识,导致了对最优 Q 值的估计偏离了实际值。我们可以根据源于 -agent batch RL 的error 分析,建立所提出算法的有限样本下的性能评估。例如,算法输出的精度多大程度取决于函数
、每次迭代 n 内的样本数以及 t 的迭代数。
5 and
在许多实际的MARL应用程序中,系统状态和其他agent的行为的部分可观察性是典型且不可避免的。通常,可以将这些设置建模为 game (POSG),在特殊情况下,该游戏包括具有 的协作设定,即Dec-POMDP模型。然而,即使合作任务也是 NEXP-hard(等,2002),难以解决。
实际上,与只需要相信状态的相比,POSG中用于最佳决策的信息状态可能会非常复杂,并且涉及 over the ’ (等人,2004年)。
这种困难主要源于从模型中获得的自身观察结果所导致的agent异质性,这是第3节中提到的MARL固有的挑战,原因是信息结构多种多样。有可能首先将解决Dec-POMDP的---方案(Amato和,2015; 和,2018)推广到解决POSGs。
Deep MARL
使用DNN进行函数逼近可以解决MARL中的可伸缩性问题。实际上,最近在MARL中获得的大部分经验成功都来自DNN的使用(和,2016; Lowe等人,2017; 等人,2017; Gupta等人,2017; 等人,2017)。但是,由于缺乏理论支持,我们在本章中没有包括这些算法的详细信息。最近,人们做出了一些尝试来理解几种 agent DRL 算法的全局收敛性,例如 TD (Cai等,2019)和 (Wang等,2019; Liu等2019年)。因此,有望将这些结果扩展到多智能体设定,作为迈向对DMARL的理论理解的第一步。
Model-based MARL
文献中很少有基于模型的MARL算法。据我们所知,目前仅有的基于模型的MARL算法包括和(2000)中的早期算法,它解决了单控制器随机游戏,一种特殊的 zero-sum MG。后来在和(2002)中对zero-sum MG进行了改进,名为R-MAX。这些算法也建立在面对不确定性时的 of 上(Auer和,2007;等,2010),就像前面提到的几种无模型的算法一样。考虑到基于模型的RL的最新进展,尤其是在某些情况下其优于无模型的RL的可证明优势(Tu and Recht,2018; Sun等,2019),有必要将这些结果推广到MARL以改进其 。
of
一般MARL中的 PG 的收敛结果大部分为负,即在许多情况下甚至会避开本地NE点,这本质上与MARL中的非平稳性挑战有关。尽管已经提出了一些补救措施(等人,2018; 等人,2019; 等人,2019; Fiez等人,2019)来稳定 games 的收敛性,但这些假设是即使在最简单的LQ设置中,也不容易在MARL中进行验证/满足(等人,2019),因为它们不仅取决于模型,而且还取决于策略参数化。由于这种微妙之处,探索基于策略的MARL方法的(全局)收敛可能很有趣,可能始于简单的LQ设置(即一般和LQ游戏),类似于 zero-sum 博弈。
MARL with /
考虑到多智能体会有不唯一的学习目标,我们认为在MARL中考虑稳健性和/或安全性约束是很有意义的。据我们所知,这仍然是一个相对未知的领域。实际上,safe RL已被认为是 agent 中最重大的挑战之一(和,2015)。由于可能存在多个目标冲突的代理,因此安全性变得更加重要,安全要求让我们必须考虑智能体间的的耦合。一种简单的模型是 multi-agent MDPs/ games,其约束条件表征了安全性要求。在这种情况下,具有可证明的安全保证的学习并非易事,但对于一些对安全性至关重要的MARL应用(如自动驾驶(-等,2016)和机器人技术(Kober等,2013))是必需的。
此外,当然也要考虑对抗对手的鲁棒性,特别是在分散/分布式合作MARL环境中,如Zhang等人所述 Zhang et al. (2018); Chen et al. (2018); Wai et al. (2018)。在这种情况下,对手可能以匿名方式干扰学习过程-这是分布式系统中的常见情况。在这种情况下,针对 的鲁棒分布式监督学习的最新发展 (Chen et al., 2017; Yin et al., 2018) 可能是有用的。
论文信息
由张凯清、杨卓然在arxiv上于2019年发表,共计72页,干货满满,欢迎大家细品、细学、细研,共同探讨。


Arxiv链接:
历史精华好文
交流合作