VLAD特征(vector of locally aggregated desc
《 local into a image 》论文笔记
这篇论文中提出了一种新的图片表示方法,也就是VLAD特征,并把它用于大规模图片检索中,得到了很好的实验结果。
目前,BOF在图片检索和分类中应用广泛,首先是因为BOF是基于比较的local特征(如SIFT)得来的,所以表达能力很强;其次是因为计算BOF过程中用到的也是根据样本在样本空间的距离来聚类的,所以,BOF也可以输入SVM这类基于样本间隔的分类器得到较好的效果。但是在数据量很大的情况下,由于大小的限制,BOF的特征表达会越来越粗略,特征信息损失较多,使得搜索精度降低。
这篇论文在大数据量的图片搜索问题上,做了3方面的优化:
1,优化特征表示方法,使用VLAD特征;
2,对降维方法(PCA)做改进
3,对索引方法(ADC)做改进
论文的主要贡献有2个:
1,基于BOF和 这这两种聚合local特征的方法提出了VLAD特征;
BOF详细内容见:
详细内容见:
2,对降维方法和索引方法做优化,而这两个优化是trade-off的,也就是此消彼长的关系,所以,论文中通过大量实验得到一个平衡值。
VLAD: of
要在大数据量的图片中搜索图像,对图片集中的每幅图片,首先是要提取VLAD特征,把每幅图片表示成一个VLAD向量v:
其中,x是该幅图像的特征点(如SIFT),ci是该幅图像的loc点(如SIFT)做得到的聚类中心,有k个,NN(x)是离x最近的聚类中心。
可以看出,实际上vi,j是以ci为聚类中心的聚类中的特征点x的每一维的值,和聚类中心ci的每一维的值,的差,的和。
x维度为d,则i=1…k,j=1…d,那么v就是D维,D=k*d.
如下图中,是对每幅图像的SIFT特征点聚合得到VLAD特征,所以VLAD的维度是16*128,可以表示成16个4*4 grid形式:


每一个小方框对应一个聚类中心,方框中是4*4*8个值,是这个聚类中的x和聚类中心的每一维的差,8个方向上线段的长度对应差值的大小。可以看出,这些VLAD是的(因为大部分差值是一个圆点,接近0),并且very ,这里的意思是,大值常常在同一个中,也就是同一个方框中,比如第一列的前几个方框里,线段都比较长,论文中使用PCA对VLAD特征降维正是基于这一特性。
VLAD可以理解为是BOF和 的折中
BOF是把特征点做聚类,然后用离特征点最近的一个聚类中心去代替该特征点,损失较多信息;
是对特征点用GMM建模,GMM实际上也是一种聚类,只不过它是考虑了特征点到每个聚类中心的距离,也就是用所有聚类中心的线性组合去表示该特征点,在GMM建模的过程中也有损失信息;
VLAD像BOF那样,只考虑离特征点最近的聚类中心,VLAD保存了每个特征点到离它最近的聚类中心的距离;
像 那样,VLAD考虑了特征点的每一维的值,对图像局部信息有更细致的刻画;
而且VLAD特征没有损失信息。
在论文的部分,可以看到在论文设计的image 实验中,VLAD特征的实验效果要比 和BOF好。
VLAD特征:
完整介绍 方法的论文
" with the : and "
的详细概念可以见以上的几篇博文(或是直接看论文)。下面主要从FV的计算步骤的角度进行介绍。首先给出以上的论文中的算法步骤做参考:

对于一副图像,提取T个描述子(比如SIFT,比如iDT),每个描述子是D维的,那么可以用 X={xt , t= 1…T}来描述这张图片。这里做一个假设,假设这t个描述子独立同分布(i.i.d)。那么则有:
取对数后可以得到:
此处的lamda为描述独立同分布的参数。现在要用一组K个高斯分布的线性组合(即GMM混合高斯模型)来逼近这个分布,其参数即为lamda。GMM模型可以用下式描述:
其中pi为第i个高斯分布
以下参数lamda,注意此处的lamda在计算FV时是已知量,是预先通过GMM求解得到的先验值:
wi为系数,wi>=0,sum(wi)=1。另外两个参数为高斯分布中的平均值和标准差。
在计算之前先定义占有概率,即特征xt由第i个高斯分布生成的概率:
对各个参数求偏导可以得到
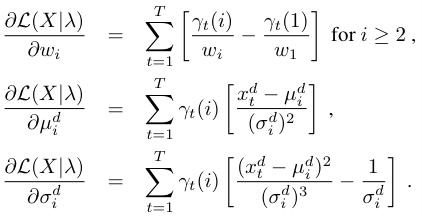
注意此处的i是指第i个高斯分布,d是指xt的第d维,因此得到的结果数目为 w:K-1个;均值:K*D个;标准差K*D个。因此共有(2D+1)*K-1个偏导结果,这里的-1是由于wi的约束。
在计算完之后,还需要进行归一化。对三种变量分别计算归一化需要的 的对角线元素的期望:
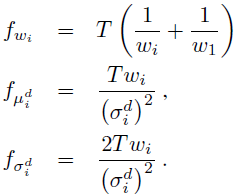
此处T为最开始的描述子的数目。最终归一化后的 的结果为:
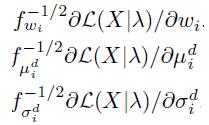
在上面提及的”Image with the : “一文中,对最后的归一化步骤进行了改进。先对 中的每个值做功率归一化,再对 做L2正则化得到最后的结果。
综上所述,基于 的图像学习的完整过程应该描述为下面几个步骤。
1.选择GMM中K的大小
1.用训练图片集中所有的特征(或其子集)来求解GMM(可以用EM方法),得到各个参数;
2.取待编码的一张图像,求得其特征集合;
3.用GMM的先验参数以及这张图像的特征集合按照以上步骤求得其fv;
4.在对训练集中所有图片进行2,3两步的处理后可以获得的训练集,然后可以用SVM或者其他分类器进行训练。
经过 的编码,大大提高了图像特征的维度,能够更好的用来描述图像。相对于BOV的优势在于,BOV得到的是一个及其稀疏的向量,由于BOV只关注了关键词的数量信息,这是一个0阶的统计信息;并不稀疏,同时,除了0阶信息, 还包含了1阶(期望)信息、2阶(方差信息),因此可以更加充分地表示一幅图片。