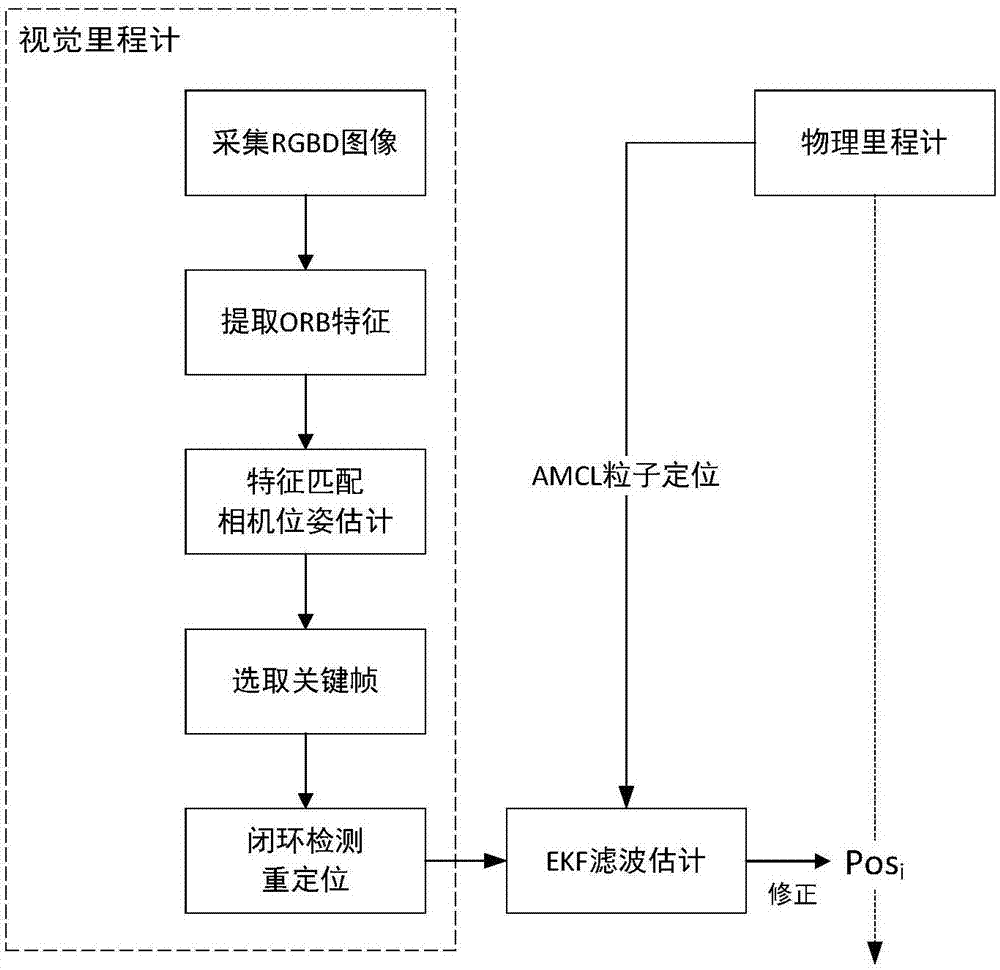
基于马尔科夫决策的路径规划(MDP Based)
文章目录 解法 MDP in (马尔科夫决策) Cost RTDP算法
前言
这里的更多的是决策树的概念,从起点到终点可能存在多条路径,需要我们根据环境的变化,选择最优的去执行。并且当前的都是假设在最完美的情况下执行的,且机器人对状态估计也是完美的。
但是现实中是不会这么完美的。
in
现在假设所有干扰都是自然产生的,现在的路径规划是机器人与自然两者博弈的结果。这与之前的是有很大的不同的。
Model
通常会假设两个空间,一个是机器人的动作空间,一个是自然的扰动空间,两空间相互独立,通过优化损失函数,来找到一条最优路径。
Model
同样假设机器人与自然的空间,现在是自然动作空间条件依赖于机器人空间,两者不相互独立了。现在就是在自然参与情况下,为机器人寻找最优的路径。
以上这是两种不同的模型,会采用不同的解决方法。
解法 Model 解法
机器人无法预测自然的行为,现在采取类似贪心的思想,就是无论机器人怎么做,自然的动作都是最不利的行为,先穷举所有自然扰动,再选一个最不利的,看机器人如何把这个最不利的降低到最低。
Model解法
这种情况是机器人每做一个动作,自然就施加一个扰动,决策树思想,需要走一步看一步。
从One Step推广到多步
一个 With 的定义,主要包括如下几个要素,State Space X {X} X,还包括了 State x s {x}_{s} xs,以及Goal Set X F {X}_{F} XF,需要定义机器人动作空间以及自然动作空间。
再一个就是State ,其描述了在 X {X} X状态下,机器人执行 u {u} u,自然执行 θ {\theta} θ,我们的状态是怎样变化的。
同时,从单步扩展到多步,我们需要一个 K {K} K来表征机器人在每一步都遇到了什么状态,执行了什么动作。最后是 k {k} k个连续的step实现从初始状态到终点的规划。
同时,为了评价规划的好坏,我们定义了这个cost ,这个cost L {L} L是对所有可能的 x k , u k , θ k {x}_{k},{u}_{k},{\theta}_{k} xk,uk,θk的组合的评价,这个公式是囊括了每一个路径的评价。
MDP in (马尔科夫决策)
问题描述:在一个栅格地图当中,机器人如何从 X I {X}_{I} XI的位置移动到黄色区域 X G {X}_{G} XG周边,中间绿色为障碍物。
最难的一步是,机器人一个 X K {X}_{K} XK的位置执行了一个 U K {U}_{K} UK的动作,然后把动作的执行模拟成一个高斯分布,就是实际上机器人到达的位置,除了从起点加上所执行的动作,还存在一些误差 σ ( θ 1 , θ 2 ) \sigma({\theta}_{1},{\theta}_{2}) σ(θ1,θ2)。相当于是一种连续的Model方式了。
之前的路径规划当中,因为没有的存在,找到一条可行的路径就直接走过去了,但是现在因为有了这些不确定的约束,就会导致每执行一步,就是走一个栅格,都会出现一些偏差。决策树的形式,每走一步,都会产生干扰,所以需要“走一步看一步。”
MDP的输出不像是传统的路径规划的输出一条准确的路径,这MDP的路径因为每走一步都会产生一些随机的误差,所以需要利用决策树的思想,每走一步再来规划下一步,所以基于MDP的路径规划的解的输出是一种决策树的形式,那这样会不会使得效率低下?
Cost-to-Goal
根据不同的Plan,又可以诱导出不同的 set,在这个set的基础上,又定义出了cost to goal,针对不同的 model,给出了不同的cost to go的定义方式。
如何用以上这两种cost to go去解决的问题?
比如在 的Model下,我们倾向于使用多步的Worst-case 去定义cost to go;在下,我们更倾向于-case。
Worst-Case
假设已知了一个MDP的Model,求解MDP的问题,给定了起始点到终止点的这个Plan,来寻找一个最优的Plan,使得整体的Cost最小。在这个Nd的Model之下,机器人并不知道自然会给自身施加什么影响,所以一般假设,自然动作空间会最大程度上去对机器人进行干扰(贪婪最大化,使得机器人处于最不利的情况),以下便是Worst-Case 的执行流程,其服从以下的这个公式,
G π ∗ ( x s ) G_{\pi*}(x_{s}) Gπ∗(xs)的解释,就是先选用最差的一种情况的Cost,即 m a x [ L ( x ~ , u ~ , θ ~ ) ] max[{{L(\{x},\{u},\{\theta})}]} max[L(x,u,θ)],之后再用这个最差的Cost,去进行Cost to go,定义了每一个 π {\pi} π的cost to go之后,我们再进行筛选,找到Cost to go当中最小的那一组 π {\pi} π,这样,就相当于找到了最优的那一Plan。直接的去求,会很困难,因为要用枚举法枚举所有的 π {\pi} π,枚举每一个 π {\pi} π诱导的那些路径,去计算Cost。这是一个组合爆炸的问题。目前求解这类方法常用的问题就是动态规划,通过第 k 、 k + 1 k、k+1 k、k+1之间的递归关系,来求得最优的Plan。
动态规划
Cost to go 对于最终的状态是 G F ∗ = l F ( x F ) {G}_{F*}={l}_{F}(x_{F}) GF∗=lF(xF)这样的从 K {K} K一直到最终的 K + 1 {K+1} K+1的Cost,就是由以上两部分组成可以把第 K {K} K步的分解成第 K + 1 {K+1} K+1步的形成递归关系
Nd
基本思想就是动态规划思想,从最后一个节点出发,往前推,计算前继节点到终点的距离(Cost),然后因为每走一步就考虑一步,所以所得的路径是最优的路径,也是Cost最少的路径。
阶段总结
Cost
其主要是求解Pb Model的问题,与上方不同的是ECP在做之前会有一个估计,我们能大体知道当机器人做一个动作后,这个自然大体上会做什么动作来干扰。行为具体上是具备了一些可预测性。
现在的评估是通过Set当中的平均表现,作为评估 π {\pi} π的一个指标。
解法还是动态规划,不过这次解法要加上权重的条件概率。
阶段总结
RTDP算法
RTDP是对 Cost 解法的一种补充,加速。
首先初始化G ,这里的 与上方是一样的,一般来说这个数值要小于实际的Cost to go的数值。然后我们按照初始化的G 去贪婪的选择动作,直到到达终点。这样就可能找到一条路径,但是这条路径可能不是最优的,是冗余的。
RTDP伪代码