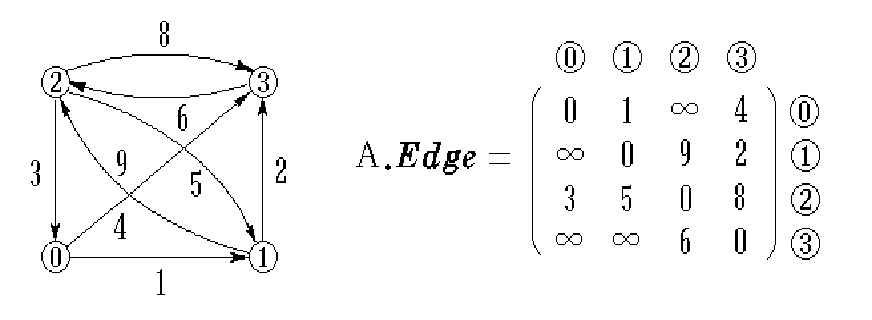文本预处理技术
自然语言处理简介:
自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。
自然语言处理(NLP)=自然语言理解(NLU)+ 自然语言生成(NLG)。
这三者的关系如下图:
在NLP工程中,文本预处理通常包含以下几个步骤:
分词: 一、分词需要工具,以下是常用开源分词工具:
Jieba分词
LTP
二、一般的分词方法: 1 最大匹配算法 1.1 正向最大匹配
正向先从左到右取个词,每次右边减一个字,直到词典中存在或剩下1个单字。
比如:
= ‘今天要学习自然语言处理’
= [‘今天’, ‘要’, ‘学习’, ‘自然’, ‘语言’, ‘处理’, ‘自然语言处理’]
词典最大长度 = 5
第1轮扫描:
第1次:“今天要学习”,扫描词典,无
第2次:“今天要学”,扫描词典,无
第3次:“今天要”,扫描词典,无
第4次:“今天”,扫描词典,有
至此切分出“今天”,然后再对剩下“要学习自然语言处理”句子继续上面操作,这里需要注意的是,要切分出最大匹配的词。
最后切分结果:=[‘今天’,‘要’,‘学习’,‘自然语言处理’]
1.2、逆向最大匹配
逆向先从右到左取个词,每次左边减一个字,取右边跟词典匹配,直到词典中存在或剩下1个单字。
比如:
= ‘今天要学习自然语言处理’
= [‘今天’, ‘要’, ‘学习’, ‘自然’, ‘语言’, ‘处理’, ‘自然语言处理’]
词典最大长度 = 5
第1轮扫描:
第1次:“然语言处理”,扫描词典,无
第2次:“语言处理”,扫描词典,无
第3次:“言处理”,扫描词典,无
第4次:“处理”,扫描词典,有
至此切分出“处理”,然后再对剩下“要学习自然语言处理”句子继续上面操作,这里需要注意的是,要切分出最大匹配的词。
最后切分结果:back=[‘今天’,‘要’,‘学习’,‘自然’,‘语言’,‘处理’]
1.3、双向最大匹配
双向最大匹配法是将正向最大匹配法和逆向最大匹配法分布得到的分词结果进行比较,从而决定分词方法。
(1)正向最大匹配,得到分词结果
(2)逆向最大匹配,得到分词结果back
(3)若等于back,即词数和单词都相同,返回任意一个
(4)若不等于back
········返回与back词语数量较少的
(5)若与back词语数量相等,但分词得单词不同,返回与back单字较少的(单字数量还相等,任意返回一个)
1.4、最大匹配的缺点
(1)使用的是贪心算法,得到的解是局部最优解。
(2)长度限制。通过来提高效率,但是也牺牲准确率。
(3)效率低,复杂度高。这个也是在字长和牺牲准确率间平衡。
(4)无法表达分词的歧义性,没有考虑上下文信息。如下:
“有意见分歧”(正向最大匹配和逆向最大匹配结果不同)
有意/见/分歧/
有/意见/分歧/
2 通过n-gram
思路:生成所有的分割,然后对所有分割组合通过n-gram计算概率,取概率最大的分割。
优点:考虑上下文信息s
缺点:复杂度高,效率低。
3 最短路径分词算法
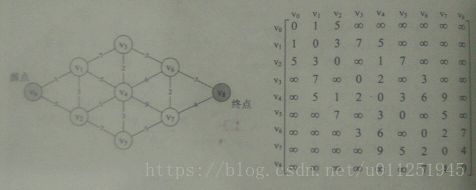
最短路径分词算法首先将一句话中的所有词匹配出来,构成词图(有向无环图DAG),之后寻找从起始点到终点的最短路径作为最佳组合方式,引用《统计自然语言处理》中的图:
3.1 最短路径分词算法
基于算法求解最短路径。该算法适用于所有带权有向图,求解源节点到其他所有节点的最短路径,并可以求得全局最优解。本质为贪心算法,在每一步走到当前路径最短的节点,递推地更新原节点到其他节点的距离。针对当前问题,算法的计算结果为:“他/说/的/确实/在理“。可见最短路径分词算法可以满足部分分词要求。但当存在多条距离相同的最短路径时,只保存一条,对其他路径不公平,也缺乏理论依据。
3.2 N-最短路径分词算法
N-最短路径分词是对算法的扩展,在每一步保存最短的N条路径,并记录这些路径上当前节点的前驱,在最后求得最优解时回溯得到最短路径。该方法的准确率优于算法,但在时间和空间复杂度上都更大。
4 基于HMM模型的分词算法
HMM模型认为在解决序列标注问题时存在两种序列,一种是观测序列,即人们显性观察到的句子,而序列标签是隐状态序列,即观测序列为X,隐状态序列是Y,因果关系为Y->X。因此要得到标注结果Y,必须对X的概率、Y的概率、P(X|Y)进行计算,即建立P(X,Y)的概率分布模型。
要注意的是,该模型创建的概率图与上文中的DAG图并不同,因为节点具有观测概率,应该使用算法求解最大概率的路径。
文本清洗
一般清理需要清洗以下数据:
1、大写转小写
对于计算机而言,一个单词的大写和小写是同一个意思。
2、无用的标签
例如:“”,这些在文本中没有表达实质意义。
3、特殊的符号
例如:标点符号和表情符号。当然,我在用生成摘要时,是要保留标点符号的,需要结合业务场景处理。
4、停用词
对于无含义的词,例如介词,需要清除,以便为后续处理降低复杂度。
5、拆分黏在一起的词
我们人类在社交论坛上产生的文本数据,本质上是完全非正式的。多数推特都伴随着很多黏着在一块的单词比如,等等。这些用简单的规则和正则表达式就可以把它们拆分成正常的形式。
6、查找俚语
社交媒体上充斥着俚语单词。在制作自由文本(free text)时这些词都应该被转换成标准词。像luv这样的词会被转成love,Helo转成Hello。查找上撇号的相似方式也可以用来将俚语转换成标准词。网上有很多资源,提供了所有可能的俚语的列表。这应该是你的圣杯,你可以将他们作为你的查询字典来转换。
7、 解码数据
这是一个信息转换的过程,将复杂符号转换成简单易于理解的字符。文本数据可能受到不同形式的编码,像是“Latin”,“UTF8”等。因此,为了更好的分析,必须让所有的数据保持标准的编码格式。UTF-8编码是被广泛接受的编码形式,推荐使用。
标准化
对于标准话,主要是对英文单词的不同变化和变形标准化,有两种方法,分别是:词干提取()和词形还原()。
1、
提取是将词还原成词干或词根的过程。
例如:’’/‘’/‘’等,都可以还原成’’。总而言之,它们都表达了分成多个路线或分支的含义。这有助于降低复杂度,并同时保留词所含的基本含义。 是利用非常简单的搜索和替换样式规则进行的。
这样可能会变成不是完整词的词干,但是只要这个词的所有形式都还原成同一个词干即可。因此 它们都含有共同的根本含义。
2、
就是去掉单词的词缀,提取单词的主干部分,通常提取后的单词会是字典中的单词,不同于词干提取(),提取后的单词不一定会出现在单词中。比如,单词“cars”词形还原后的单词为“car”,单词“ate”词形还原后的单词为“eat”。
特征提取和特征选择
特征提取:根据目前的一组特征集创建新的特征子集。即将机器学习算法不能识别的原始数据转化为算法可以识别的特征的过程。
特征选择:从所有的特征集选出一个特征子集。即去掉无关特征,保留相关特征的过程,特征选择本质上可以认为是降维的过程,不产生新的特征
对比图:
一、特征提取方法
1、主成分分析(PCA)
2、线性判别分析法(LDA)
3、多维尺度分析法(MDS)
4、独立成分分析法( ICA )
5、核主成分分析法(如核方法KPCA,KDA)
6、基于流型学习的方法
二、特征选择方法
1、按搜索策略分类
2、按评价准则分类