不到70行Python代码,轻松玩转RFM用户分析模型(附案例数据和代码)
本文从RFM模型概念入手,结合实际案例,详解实现模型的每一步操作,并提供案例同款源数据,以供同学们知行合一。
注:想直接下载代码和数据的同学可以空降文末
看这篇文章前源数据长这样:
学完后只要敲一个回车,源数据就变成了这样:
是不是心动了?OK,闲话少叙,我们来开动正餐!
RFM,是一种经典到头皮发麻的用户分类、价值分析模型,同时,这个模型以直白著称,直白到把需要的字段写在了脸上,让我们再念一遍:“R!F!M!”:
这三个维度,是RFM模型的精髓所在,帮助我们把混杂一体的客户数据分成标准的8类,然后根据每一类用户人数占比、金额贡献等不同的特征,进行人、货、场三重匹配的精细化运营。
用建立RFM模型,整体建模思路分为五步,一言蔽之——“五步在手,模型你有”,分别是数据概览、数据清洗、维度打分、分值计算和客户分层。
01 数据概览
我们的源数据是订单表,记录着用户交易相关的字段:
有个细节需要注意,订单每一行代表着单个用户的单次购买行为,什么意思呢?如果一个用户在一天内购买了4次,订单表对应记录着4行,而在实际的业务场景中,一个用户在一天内的多次消费行为,应该从整体上看作一次。
比如,我今天10点在必胜客天猫店买了个披萨兑换券,11点又下单了饮料兑换券,18点看到优惠又买了两个冰淇淋兑换券。这一天内虽然我下单了3次,但最终这些兑换券我会一次消费掉,应该只算做一次完整的消费行为,这个逻辑会指导后面F值的计算。
我们发现在订单状态中,除了交易成功的,还有用户退款导致交易关闭的,那还包括其他状态吗?Let me see see:
只有这两种状态,其中退款订单对于我们模型价值不大,需要在后续清洗中剔除。
接着再观察数据的类型和缺失情况:
订单一共28833行,没有任何缺失值,Nice!类型方面,付款日期是时间格式,实付金额、邮费和购买数量是数值型,其他均为字符串类型。
02 数据清洗
剔除退款
在观察阶段,我们明确了第一个清洗的目标,就是剔除退款数据:
关键字段提取
剔除之后,觉得我们订单的字段还是有点多,而RFM模型只需要买家昵称,付款时间和实付金额这3个关键字段,所以提取之:
关键字段构造
上面的基础清洗告一段落,这一步关键在于构建模型所需的三个字段:R(最近一次购买距今多少天),F(购买了多少次)以及M(平均或者累计购买金额)。
首先是R值,即每个用户最后一次购买时间距今多少天。如果用户只下单过一次,用现在的日期减去付款日期即可;若是用户多次下单,需先筛选出这个用户最后一次付款的时间,再用今天减去它。
需要提醒的是,时间洪流越滚越凶,对应在时间格式中,就是距离今天越近,时间也就越“大”,举个例子,2019年9月9日是要大于2019年9月1日的:
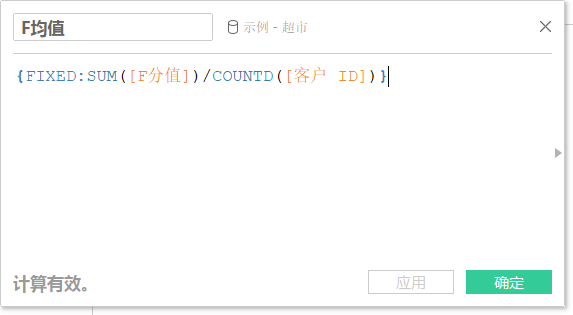
因此,要拿到所有用户最近一次付款时间,只需要按买家昵称分组,再选取付款日期的最大值即可:
为了得到最终的R值,用今天减去每位用户最近一次付款时间,就得到R值了,这份订单是7月1日生成的,所以这里我们把“2019-7-1”当作“今天”:
接着来搞定F值,即每个用户累计购买频次。
在前面数据概览阶段,我们明确了“把单个用户一天内多次下单行为看作整体一次”的思路,所以,引入一个精确到天的日期标签,依照“买家昵称”和“日期标签”进行分组,把每个用户一天内的多次下单行为合并,再统计购买次数:
上一步计算出了每个用户购买频次,这里我们只需要得到每个用户总金额,再用总金额除以购买频次,就能拿到用户平均支付金额:
最后,万剑归宗,三个指标合并:
至此,我们完成了模型核心指标的计算,算是打扫干净了屋子再请客。
03 维度打分
维度确认的核心是分值确定,按照设定的标准,我们给每个消费者的R/F/M值打分,分值的大小取决于我们的偏好,即我们越喜欢的行为,打的分数就越高:
RFM模型中打分一般采取5分制,有两种比较常见的方式,一种是按照数据的分位数来打分,另一种是依据数据和业务的理解,进行分值的划分。这里希望同学们加深对数据的理解,进行自己的分值设置,所以讲述过程中使用的是第二种,即提前制定好不同数值对应的分值。
R值根据行业经验,设置为30天一个跨度,区间左闭右开:
F值和购买频次挂钩,每多一次购买,分值就多加一分:
我们可以先对M值做个简单的区间统计,然后分组,这里我们按照50元的一个区间来进行划分:
这一步我们确定了一个打分框架,每一位用户的每个指标,都有了与之对应的分值。
04 分值计算
分值的划分逻辑已经确定,看着好像有点麻烦。下面我们有请潘大师()登场,且看他如何三拳两脚就搞定这麻烦的分组逻辑,先拿R值打个样:
沧海横流,方显潘大师本色,短短一行代码就搞定了5个层级的打分。的cut函数,我们复习一下:
接着,F和M值就十分容易了,按照我们设置的值切分就好:
第一轮打分已经完成,下面进入第二轮打分环节。
客官不要紧脏,面试都还不止两轮呢,伦家RFM模型哪有那么随便的。
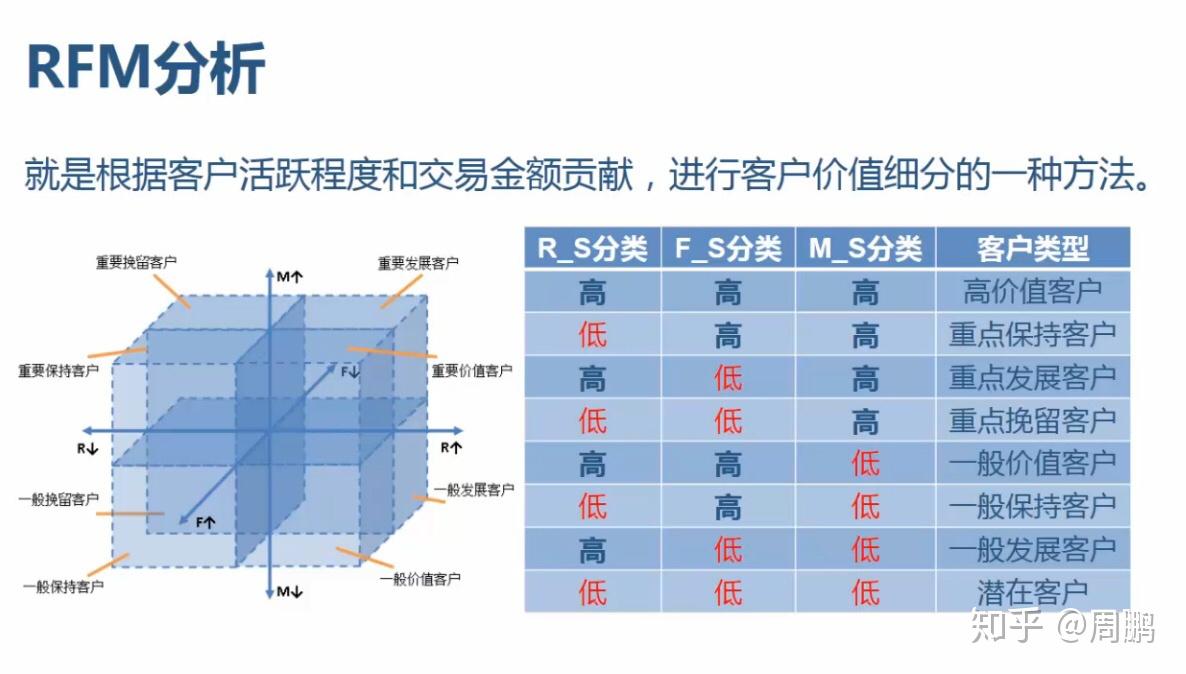
现在R-SCORE、F-SCORE、M-SCORE在1-5几个数之间,如果把3个值进行组合,像111,112,113...这样可以组合出125种结果,过多的分类和不分类本质是一样的。所以,我们通过判断每个客户的R、F、M值是否大于平均值,来简化分类结果。
因为每个客户和平均值对比后的R、F、M,只有0和1(0表示小于平均值,1表示大于平均值)两种结果,整体组合下来共有8个分组,是比较合理的一个情况。我们来判断用户的每个分值是否大于平均值:
中判断后返回的结果是True和False,对应着数值1和0,只要把这个布尔结果乘上1,True就变成了1,False变成了0,处理之后更加易读。
05 客户分层
回顾一下前几步操作,清洗完之后我们确定了打分逻辑,然后分别计算每个用户的R、F、M分值(SCORE),随后,用分值和对应的平均值进行对比,得到了是否大于均值的三列结果。至此,建模所需的所有数据已经准备就绪,剩下的就是客户分层了。
RFM经典的分层会按照R/F/M每一项指标是否高于平均值,把用户划分为8类,我们总结了一下,具体像下面表格这样:
由于传统的分类,部分名称有些拧巴,像大多数分类前都冠以“重要”,“潜力”和“深耕”到底有什么区别?“唤回”和“挽回”有什么不一样?
本着清晰至上原则,我们对原来的名称做了适当的改进。强调了潜力是针对消费(平均支付金额),深耕是为了提升消费频次,以及重要唤回客户其实和重要价值客户非常相似,只是最近没有回购了而已,应该做流失预警等等。这里只是抛砖引玉,提供一个思路,总之,一切都是为了更易理解。
对于每一类客户的特征,我们也做了简单的诠释,比如重要价值客户,就是最近购买我们的产品,且在整个消费生命周期中购买频次较高,平均每次支付金额也高。其他的分类也是一样逻辑,可以结合诠释来强化理解。下面,我们就用来实现这一分类。
先引入一个人群数值的辅助列,把之前判断的R\F\M是否大于均值的三个值给串联起来:
人群数值是数值类型,所以位于前面的0就自动略过,比如1代表着“001”的高消费唤回客户人群,10对应着“010”的一般客户。
为了得到最终人群标签,再定义一个判断函数,通过判断人群数值的值,来返回对应的分类标签:
最后把标签分类函数应用到人群数值列:
客户分类工作的完成,宣告着RFM模型建模的结束,每一位客户都有了属于自己的RFM标签。
RFM模型结果分析
其实到上一步,已经走完了整个建模流程,但是呢,一切模型结果最终都要服务于业务,所以,最后我们基于现有模型结果做一些拓展、探索性分析。
查看各类用户占比情况:
探究不同类型客户消费金额贡献占比:
结果可视化之(可视化代码留给大家自行尝试):
从上面结果,我们可以快速得到一些推断:
再结合金额进行分析:
至此,我们基于订单源数据,按照五步法用完成了RFM模型的建立,并对结果进行了简单的分析。最后,只要把上述代码封装成函数,对于新的数据源,只要一个回车就能够撸出模型,So Easy!
整个案例、数据和完整代码精心花了N周的时间准备,觉得有用的旁友动动小手来一波评论 or 在看吧~
下载地址:
:
或后台回复“用户分析",获取网盘形式存储的数据