机器学习系列(3)_逻辑回归应用之Kaggle泰坦尼克之灾
入门,开始机器学习应用之旅。
参看一些入门的博客,感觉,需要熟练掌握,同时也学到了一些很有用的,包括数据分析和机器学习的知识点。下面记录一些有趣的数据分析方法和一个自己撸的小程序。
1.
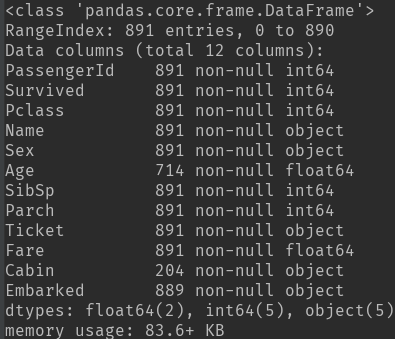
1) ():数据的特征属性,包括数据缺失情况和数据类型。
df.(): 数据中各个特征的数目,缺失值为NaN,以及数值型数据的一些分布情况,而类目型数据看不到。
缺失数据处理:缺失的样本占总数比例极高,则直接舍弃;缺失样本适中,若为非连续性特征则将NaN作为一个新类别加到类别特征中(0/1化),若为连续性特征可以将其离散化后把NaN作为新类别加入,或用平均值填充。
2)数据分析方法:将特征分为连续性数据:年龄、票价、亲人数目;类目数据:生存与否、性别、等级、港口;文本类数据:姓名、票名、客舱名
3)数据分析技巧(画图、求相关性)
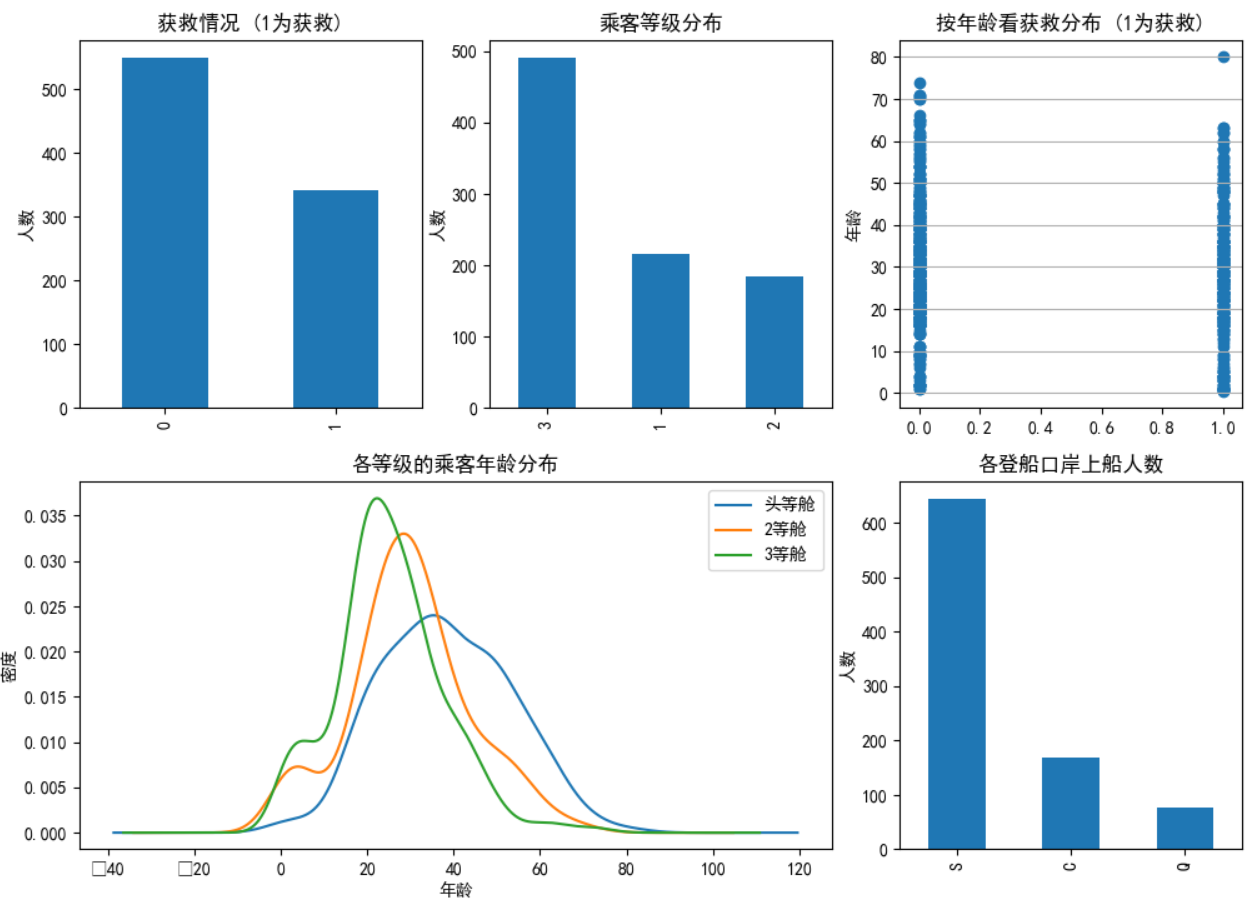
类目特征分布图&&特征与生存情况关联柱状图:
fig1 = plt.figure(figsize=(12,10)) # 设定大尺寸后使得图像标注不重叠
fig1.set(alpha=0.2) # 设定图表颜色alpha参数
plt.subplot2grid((2,3),(0,0)) # 在一张大图里分列几个小图
data_train.Survived.value_counts().plot(kind='bar')# 柱状图
plt.title(u"获救情况 (1为获救)") # 标题
plt.ylabel(u"人数")plt.subplot2grid((2,3),(0,1))
data_train.Pclass.value_counts().plot(kind="bar")
plt.ylabel(u"人数")
plt.title(u"乘客等级分布")plt.subplot2grid((2,3),(0,2))
plt.scatter(data_train.Survived, data_train.Age)
plt.ylabel(u"年龄") # 设定纵坐标名称
plt.grid(b=True, which='major', axis='y')
plt.title(u"按年龄看获救分布 (1为获救)")plt.subplot2grid((2,3),(1,0), colspan=2)
data_train.Age[data_train.Pclass == 1].plot(kind='kde')
data_train.Age[data_train.Pclass == 2].plot(kind='kde')
data_train.Age[data_train.Pclass == 3].plot(kind='kde')
plt.xlabel(u"年龄")# plots an axis lable
plt.ylabel(u"密度")
plt.title(u"各等级的乘客年龄分布")
plt.legend((u'头等舱', u'2等舱',u'3等舱'),loc='best') # sets our legend for our graph.
View Code
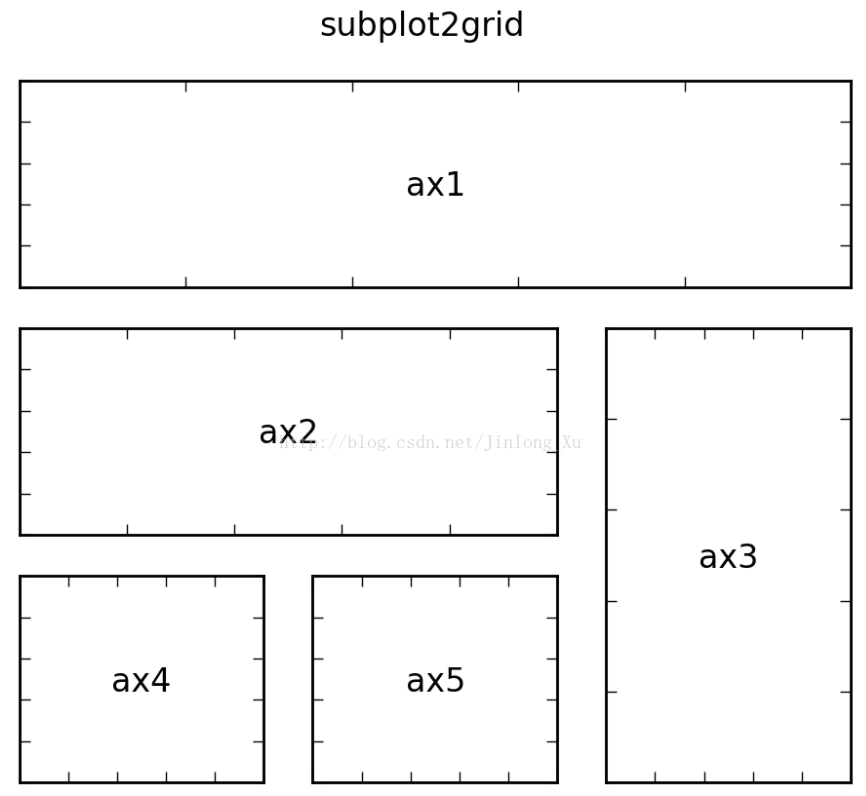
以上为3种在一张画布实现多张图的画法:
ax1 = plt.subplot2grid((3,3), (0,0), colspan=3) ax2 = plt.subplot2grid((3,3), (1,0), colspan=2) ax3 = plt.subplot2grid((3,3), (1, 2), rowspan=2) ax4 = plt.subplot2grid((3,3), (2, 0)) ax5 = plt.subplot2grid((3,3), (2, 1)) plt.suptitle("subplot2grid")
View Code
此外,还有两种方法等效:
f=plt.figure()
ax=fig.add_subplot(111)
ax.plot(x,y)plt.figure()
plt.subplot(111)
plt.plot(x,y)
View Code
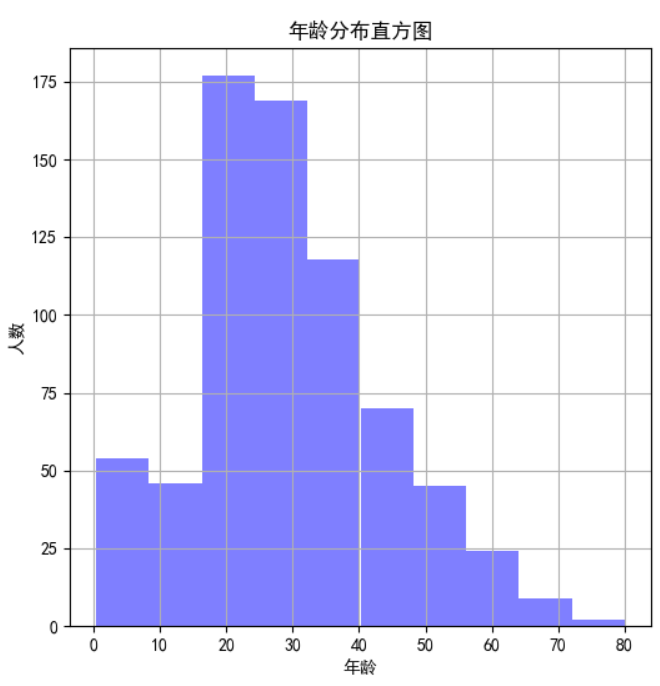
连续性特征分布可以用直方图hist来实现(见上图-年龄分布直方图):
figure1 = plt.figure(figsize=(6,6))
value_age = train_data['Age']
value_age.hist(color='b', alpha=0.5) # 年龄分布直方图
plt.xlabel(u'年龄')
plt.ylabel(u'人数')
plt.title(u'年龄分布直方图')
View Code
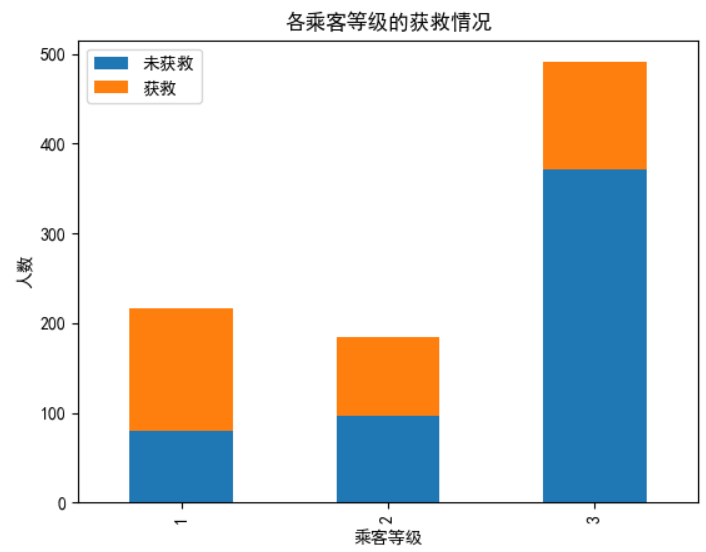
类目特征与生存关系柱状图(见上图-各乘客等级的获救情况):
fig2 = plt.figure(figsize=(6,5))
fig2.set(alpha=0.2)
Survived_0 = data_train.Pclass[data_train.Survived==0].value_counts()
Survived_1 = data_train.Pclass[data_train.Survived==1].value_counts()
df = pd.DataFrame({u'获救':Survived_1, u'未获救':Survived_0})
df.plot(kind='bar', stacked=True) # stacked=False时不重叠
plt.title(u"各乘客等级的获救情况")
plt.xlabel(u"乘客等级")
plt.ylabel(u"人数")
plt.show()
View Code
各属性与生存率进行关联:
eg:舱位和性别与存活率的关系:利用中的函数
Pclass_Gender_grouped=dt_train_p.groupby(['Sex','Pclass']) #按照性别和舱位分组聚合 PG_Survival_Rate=(Pclass_Gender_grouped.sum()/Pclass_Gender_grouped.count())['Survived'] #计算存活率 x=np.array([1,2,3]) width=0.3 plt.bar(x-width,PG_Survival_Rate.female,width,color='r') plt.bar(x,PG_Survival_Rate.male,width,color='b') plt.title('Survival Rate by Gender and Pclass') plt.xlabel('Pclass') plt.ylabel('Survival Rate') plt.xticks([1,2,3]) plt.yticks(np.arange(0.0, 1.1, 0.1)) plt.grid(True,linestyle='-',color='0.7') plt.legend(['Female','Male']) plt.show() #画图
View Code
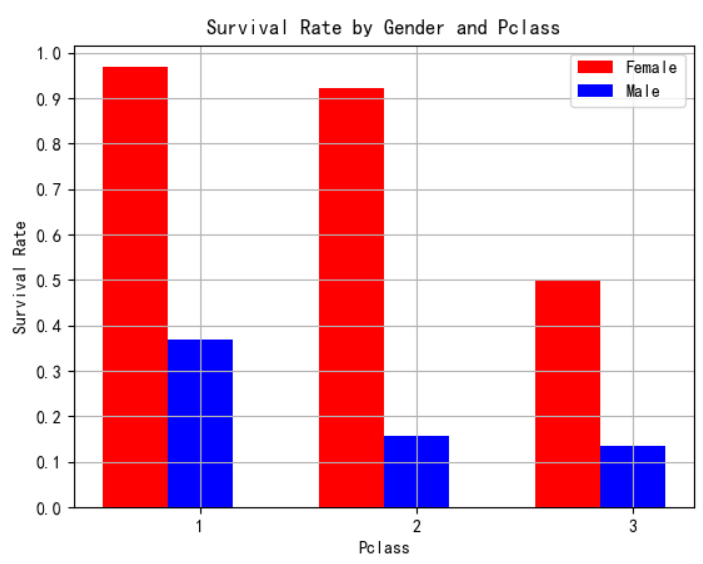
可以看到,不管是几等舱位,都是女士的存活率远高于男士。
将连续性数据年龄分段后,画不同年龄段的分布以及存活率:
age_train_p=dt_train_p[~np.isnan(dt_train_p['Age'])] #去除年龄数据中的NaN ages=np.arange(0,85,5) #0~85岁,每5岁一段(年龄最大80岁) age_cut=pd.cut(age_train_p.Age,ages) age_cut_grouped=age_train_p.groupby(age_cut) age_Survival_Rate=(age_cut_grouped.sum()/age_cut_grouped.count())['Survived'] #计算每年龄段的存活率 age_count=age_cut_grouped.count()['Survived'] #计算每年龄段的总人数 ax1=age_count.plot(kind='bar') ax2=ax1.twinx() #使两者共用X轴 ax2.plot(age_Survival_Rate.values,color='r') ax1.set_xlabel('Age') ax1.set_ylabel('Number') ax2.set_ylabel('Survival Rate') plt.title('Survival Rate by Age') plt.grid(True,linestyle='-',color='0.7') plt.show()
View Code
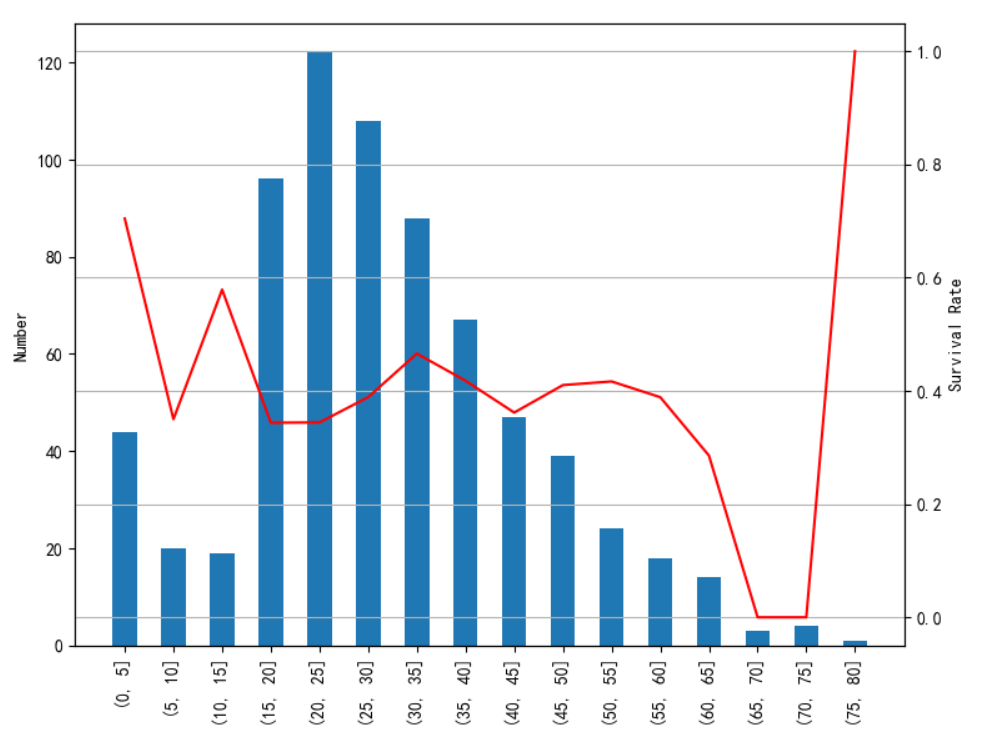
可以看到年龄主要在15~50岁左右,65~80岁死亡率较高,后面80岁存活率高是因为只有1人。
Parch、SibSp取值少,分布不均匀,不适合作为连续值来处理。可以将其分段化。这里分析一下Parch和SibSp与生存的关联性
from sklearn.feature_selection import chi2
print("Parch:", chi2(train_data.filter(["Parch"]), train_data['Survived']))
print("SibSp:", chi2(train_data.filter(["SibSp"]), train_data['Survived']))
# chi2(X,y) X.shape(n_samples, n_features_in) y.shape(n_samples,)
# 返回 chi2 和 pval, chi2值描述了自变量与因变量之间的相关程度:chi2值越大,相关程度也越大,
# http://guoze.me/2015/09/07/chi-square/
# 可以看到Parch比SibSp的卡方校验取值大,p-value小,相关性更强。
4)数据预处理:
舍掉
为类目属性,3类。本身有序的,暂时不进行dummy
Name 为文本属性,舍掉,暂时不考虑
Sex为类目属性,2类。本身无序,进行dummy
Age为连续属性,确实较多可以用均值填充。幅度变化大。可以将其以5岁为step进行离散化或利用将其归一化到[-1,1]之间
SibSp为连续属性,但比较离散,不适合按照连续值处理,暂时不用处理。或者可以按照其数量>3和