Docker
镜像载入:load < 本地名字 容器导出: id > 导出文件
镜像存出: sare -o 本地名字 镜像 容器导入:cat 文件 | dake -名字
查看容器信息 ps -a
创建容器 -it -p 创建启动 run -d
启动 start 关闭 stop 删除容器rm 镜像 rmi 进入 exec -it 复制cp 文件 id:位置
-是管理容器的 基于的编排工具 批量操作
up 启动所有服务
up -d 在后台所有启动服务
ps 列出目前所有容器
stop 停止
logs查看服务器输出
build重新构建项目中的服务容器
pull 拉取镜像
隔离机制
通过Linux 创建隔离,决定进程能够看到和使用哪些东西。
通过 技术来约束进程对资源的使用
几种隔离
主机名和域名 UTS 系统调用参数:
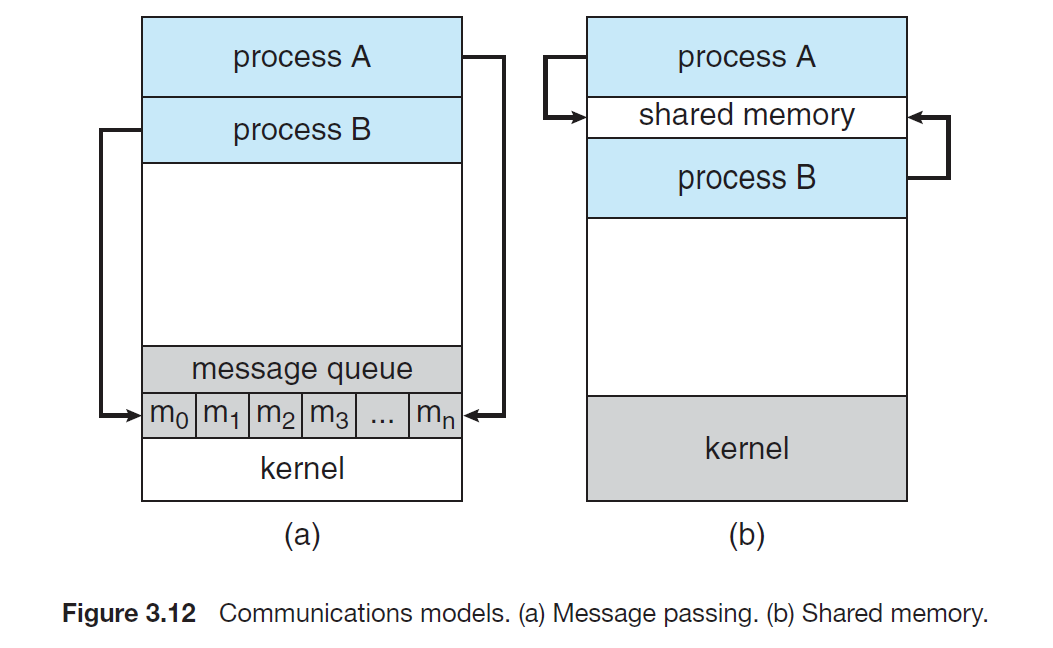
信号量,消息队列,共享内存 IPC
进程号 PID
文件系统(挂载点) Mount
网络设备,网络栈,端口
用户和用户组 User
是linux内核中的机制,对组设置权限,对进程进行控制。用户会继承它所在组的权限。这种机制可以根据特定的行为把一系列的任务,子任务整合或者分离,按照资源划分的等级的不同,从而实现资源统一控制的框架,可以控制、限制、隔离进程所需要的物理资源,包括cpu、内存、IO,为容器虚拟化提供了最基本的保证,是构建一系列虚拟化的管理工具
解决问题:资源控制,优先级分配:资源统计:进程控制:
组件
Api :,作为资源操作的唯一入口,客户端与k8s群集及K8s内部组件的通信,都要通过Api 这个组件;
-:运行控制器,负责维护群集的状态,比如故障检测、自动扩展、滚动更新等;
:负责资源的调度,按照预定的调度策略将pod调度到相应的node节点上;
Etcd:担任数据中心的角色,保存了整个群集的状态;
node的组件
:负责维护容器的生命周期,同时也负责 和网络的管理
kube-proxy:负责为 提供 内部的服务发现和负载均衡
其他组件
:负责镜像管理和pod真正运行
-:群集核心监控的聚合器
:群集的部署和升级工具
:管理工具 k8s客户端
优点
K8s是一个容器编排工具 1.24版本后使用的(的一个重要组件吧)
有自我修复,弹性伸缩,自动部署和回滚,服务发现和负载均衡,机密数据管理,允许指定内存,
存储用的PV/PVC 通过存储敏感数据
Pod创建流程
1,客户端提交Pod的配置信息到;
2,收到指令后,通知给-创建一个资源对象;
3,-通过api-将pod的配置信息存储到ETCD数据中心中;
4,检测到pod信息会开始调度预选,挑选出更适合运行pod的节点,然后将pod的资源配置单发送到node节点上的组件上。
5 根据发来的资源配置单运行pod,运行成功后,将pod的运行信息返回给,将返回的pod运行状况的信息存储到etcd数据中心。
K8S-类型
:默认类型,自动分配一个仅内部可以访问的虚拟IP
:在基础上为在每台机器上绑定一个端口,这样可以通过:来访问服务
:在基础上,借助cloud 创建一个外部负载均衡器,并将请求转发到:(得是公网ip)
: 把集群外部的服务引入到集群内部来,在集群内部直接使用,没有任何类型代理被创建,这只有.7 或更高版本的kube-dns才支持
五种控制器
( Nginx, 微服务,jar)无状态应用
(Mysql主从,etcd集群,kafka,zk) 有状态应用
下的pod一样,不考虑顺序和在哪个node 可随意扩缩容
实例之间有差别,每个实例都有自己的独特性,元数据不同,例如etcd,
实例之间不对等的关系,以及依靠外部存储的应用。
:一次部署,每个node都会运行一个pod(适用于婆罗米修斯节点,)
分为普通任务(Job)和定时任务() 一次性执行
暴露服务
创建一个pod和一个svc,写入域名并指向这个svc
生命周期
创建 初始化 运行
终止 挂起 运行 成功 失败 未知
网络插件
基于隧道
基于路由
包括:felix(路由配置和规则下发)etcd(存储保证网络数据的一致性)bird(把当前Felix写入信息下发到当前网络,确保通信有效性),bird大规模
优点
是个虚拟网络解决方案,它完全利用路由规则实现动态组网,通过BGP协议通告路由。
组成的网络是单纯的三层网络,报文的流向完全通过路由规则控制,没有等额外开销; 数据存储到Etcd
的可以漂移,并且实现了acl。
的缺点
路由的数目与容器数目相同,非常容易超过路由器、三层交换、甚至node的处理能力,从而限制了整个网络的扩张;
工作模式:
Ipip:用在跨网段通信的时候,BGP不行,
Bgp
性能的几个检测方式:
Ping: hosts和pod之间的延迟
带宽测试:用iperf测试hosts和pods间带宽