实战天池精准医疗大赛之二_再接再厉
1. 说明
之前参加的都是往期赛,新人赛,这是第一人参加正式比赛,先谈谈感受。 天池精准医疗已开赛一周,排行搒上大家整体的误差从0.9提升到0.8,也就是说一开始0.88分还名列前茅,一周之后,这个分数早已榜上无名了。比想象中激烈,我也是反复出榜(榜单仅列出前一百名),偶尔侥幸进入前十,时刻准备着再次被踢出排行榜, 也算是体验了一把逆水行舟的乐趣。 很多时候反复实验仍然提高不了成绩,感觉完全没有方向,大家都在摸索,和一边做一边对照正确答案,确实不一样。也有一些算法,我知道它,却不知道什么时候用它。在此也记录一下经验教训。
2. 特征工程
开始的时候做了一些特征工程,包括填充缺失值,为SVM计算排序特征,还找到化验单各项指标的正常的范围值,根据各项指标正常与否做离散特征,根据指标的合格数量计算统计特征等等。但相对于简单地判断中值,均值,效果都没有明显地提高。后来做了标准化,效果挺明显的,而且转换后缺失值就可以直接填0了。 也分析了一下,为什么正常范围没起到作用,化验之后不都是看这个吗?后来在肉眼观察血糖各个档位特征统计值的时候,发现血糖高者某些生化指标和整体均值有明显差异,但仍在正常范围之内,另外在不正常的情况下,差值的大小也很重要,所以这种一刀切的方法好像不行。
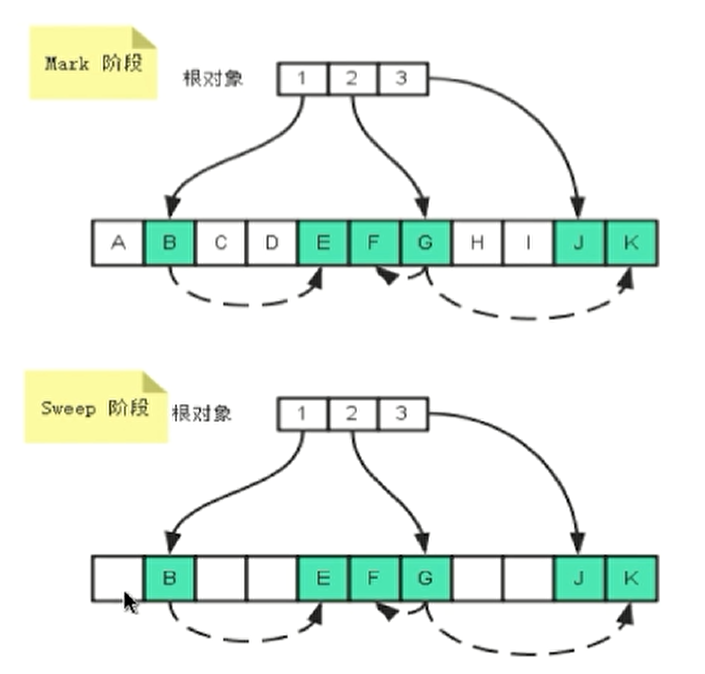
3. 分析结果分布
本题预测结果是血糖值,大致分布如下:
我们把它称为大地和星空问题,大地指的是5-6之间的区域,80%以上的血糖都分布在这个区域,此区域也是容易被预测的,而上面星星点点的是星空,虽然数量不多,却起着决定性的作用。这还要从评分公式说起:
由公式可知,评估指标是均方误差MSE的二分之一,其中m是实例个数,y’是预测值,y是实际值,关键是右上角的平方,它进一步放大了大的误差值。拿测试集来说,其中有1000个实例,即m=1000,如果把某个实例5.5预测成5,它对误差的贡献是(5-5.5)^2 /2000=0.,如果把20预测成5,误差为(5-20)^2 /2000=0.1125,它是前者的900倍,这个距离可以在排行榜拉开好几百名的差距了。这么看来,那些小的差异可以先不管。 再来看看训练集中血糖的分布:
一般把大于6.1的认为是高血糖,大于11.1的认为是糖尿病。在训练集提供的5642个实例中,大于6.1的911个,大于11.1的97个。如果测试集的分布与训练集一致,大约有17个实例血糖在11.1以上。
但是在讨论群里面很多人对测试集的预测都没有超过10的,按测试数据估计,只占总人数1.7%的糖尿病人的误差就占了总误差的将近一半。
再考虑这个题目要解决什么问题,如果根本测不出谁是糖尿病患者,只是纠结正常范围内的小误差,这算法就没意义了。
一开始我的计算结果也是这样的,这可能是源于大家都在使用Boost迭代改进算法,它的原理是不断迭代,并在每次计算时加大前一次算错实例的权重,可以想见,本题中80%多都是正常血糖值,于是它模型拉向了均值,大量分枝在5附近做细小切分,后来试了等深分箱,也没什么用。 基于这个原因,我尝试修改了算法的损失函数,评价函数,实例权重等等,但效果都太好,这也可能因为我个人水平有限。后来直接把回归问题改成了先分类后回归,效果还可以。
4. 问题规模
本题是一个小规模数据的问题,因为数据量小,经常引发线上与线下评分不一致,而且容易造成过拟合,以及和测试集相关的作弊问题。不过即使数据再少,也有20W+的数据,人的大脑也处理不了。下面来看看不同数据量与算法选择的关系,从另一角度分析一下星空问题的解法。假设下面三种情况:
第一种情况:从5000个实例中找到包含5个实例的类别。(血糖超20)
第二种情况:从5000个实例中找到包含100个实例的类别。(血糖超11.1,尿糖病)
第三种情况:从5000个实例中找到包含1000个实例的类别。(血糖超6.1,不正常)
第一种情况下,类中只有5个实例,实例太少,无法取均值,因为只要其中一值太大或太小,都会严重影响均值。此时,每个实例都很重要,可以考虑使用距离类的算法,比如K近邻。另外,可以查看这些实例中各个特征与均值的差异,从而构建规则。

第二种情况下,类中有100个实例,占整体的2%,这些实例之间可能有一些重合的特点,可以统计的一些共同特征,一般不止一种模式,可尝试聚类,找到一些规律。也可以用类的统计特征和整体的统计特征相比较,或者考虑贝叶斯类的算法。 第三种情况下,类中有1000个实例,占整体20%,这也是最常见的一种情况,它不再是从正常中找异常,而是从正常中找正常,基本属于大地问题了,有1000个实例,量也足够大,必然涵盖了很多种情况,可以考虑分类树比如GBDT类型的算法。
以上三种情况都是从整体中选出少数实例,里面有一个隐含的特征非常重要:整体的均值,它的作用就像是人的常识一样。
5. 算法
选择算法上有个误区:非此即彼。我们希望把每个实例都正确分类,但这往往是不可能的。比如在本题的情况下,可以先用GBDT的算法做一个。在改进的过程中,选择一些规则类的算法。
这里指的规则,比如说,我们只关心血糖高于11.1的(正例),就可以从树分类器上切出一些只含有正例的分枝,而并不关注树的其它部分,从而生成一套规则集。预测时,符合规则的按糖尿病处理,不合规则的再用预测。
6. 调参
本题中我试用过SVM, RF, , ,评分最高的还是和,除了速度有些差异以外,结果几乎是一样的,使用的是的cv调参。
需要注意的是,有的参数还是需要具体问题具体分析,不能只依赖自动调参,比如说,像最小叶节点这种参数,一般为避免过拟合,自动调参会建议5-6,但本问题中血糖超过20的只有4个实例,而且明显不能归为同一类,如果限定了最小叶节点为5,那这种大值就永远预测不到了。
7. 竞赛方法
一开始觉得技术圈里的交流实在是太少了,和没法比(虽然中的文章和示例也主要在新手学习区)。后来进了钉钉群,发现还挺热闹的,可能因为群里反馈更快,很多东西就在群里交流了,结果也没能记录下来。 尽管大家不会在钉钉群里详细讲算法,但有时只言片语也有很大的启发作用,尤其是在没有思路的情况下。另外,有的人会试一些算法,然后公开结论,这样也能少走很多冤枉路。
另外需要注意的是调整心态,反复被踢出排行榜的心态必然不好,于是很想打回来,不断寻找下一次提交的目标,每天提交两次,每个计划都是8小时以内的,不断寻找部局最优解,微调再微调。但如果不在整个结构上调整,提分会特别有限。