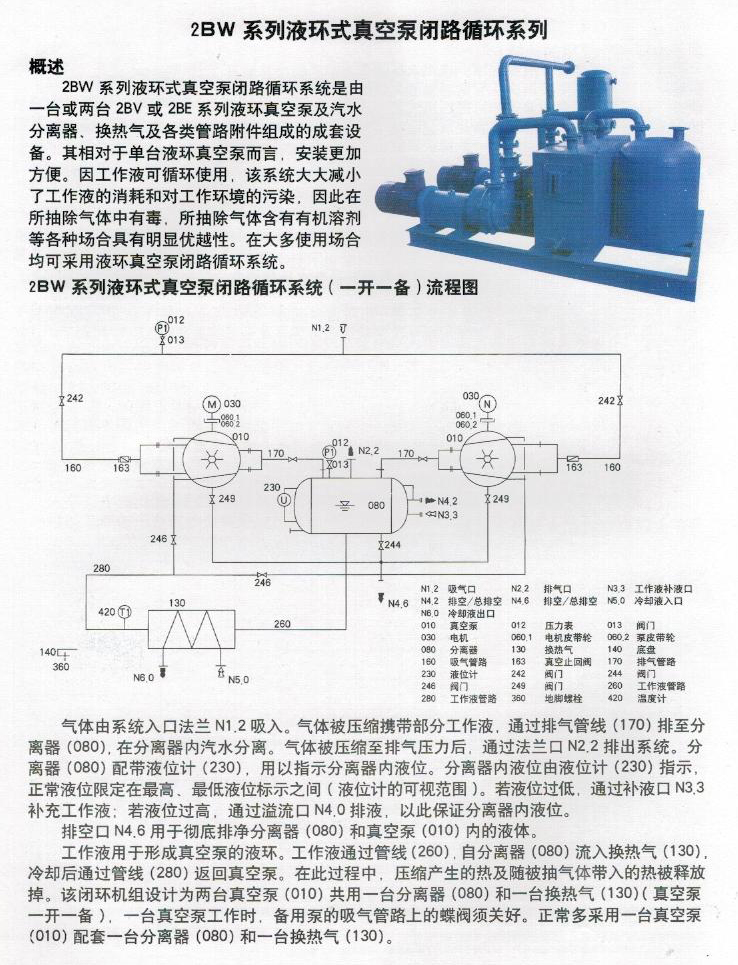
通知告警治理(降噪)的7种方法
情景&任务
工作日打开邮箱,几百几千封的邮件。虽然可以通过邮件过滤器将邮件分组,让自己快速找到自己最关心的内容。但是还是不可避免过个1年半载邮件过多,容量不足,其他人发邮件发不进来。或者真正出问题时,邮件过于频率,最需要的时候反而打不开邮件了。
周末正在旅行,手机告警短信一个接一个的。眼看手机快没电了,还等着下车刷手机上公交卡呢。一个告警短信来了嗒嗒嗒一声,手机没电了。
对于短信和邮件等通知和告警形式,当消息量大于一定程度后,平均可用价值在降低(内容熵增)。容易引起下面问题:
l 故障期间,告警风暴,手机/邮箱会被海量告警淹没;
l 运维人员很难从海量告警中筛选出重要告警,容易忽略重要告警;
l 固定阈值控制,频繁误报、漏报告警;
l 告警没有发给真正需要处理问题的人;
l 目前有些线上告警一直无人处理,告警一直存在,没有真正发挥告警的意义;
l 告警和巡检没有做明确的分类区分;
为了快速应对故障,提高对告警的敏感性,需要对告警进行治理。
行动
严格来说:告警也是一种通知。但是告警和其他通知的思路有所不同。对于告警:
其他通知思路:
(一)规范命名
告警和通知的共性问题是都需要熵减,就是让内容更有秩序,容易分辨。
主题可采用:【级别+分类】+内容 的形式,例如:
【P0系统告警】ping命令不可达
级别定义可根据需要处理的时效来规范,比如可设定P0级别为需要立即处理,P1级别为连续发生则需要立即处理,P2级别为保持关注。
分类可大体上分为告警类和通知类。
告警类又可分为系统告警和业务告警。通知类又可分为定时巡检通知和条件触发类通知。定时巡检通知和条件触发类通知都各有系统类和业务类。CPU、内存、磁盘剩余量等属性属于系统类。和具体业务相关的,比如做支付业务的,支付成功笔数、退款率都属于业务类。举个例子:
【P2定时业务巡检】近1小时业务成功率99.9968%,TP99耗时260ms
收到这条通知,可能大多数同事平时就是了解下目前的系统状况是一直很稳定的。比如一个季度会专门思考分析下成功率和耗时是否满足要求,是质量提高了还是下降了。是否需要处理还是保持现状。
再举个条件触发类通知的例子:
比如某业务在高速增长,大家很关心增长速度。所以就配置了一个通知:业务每上升一个百分点就发一个通知:
【P1条件触发通知】XXX业务近一周业务增长1%,目前日单量3000W
(二)阈值与等级和周期联动
对于同一类的通知和告警可根据程度设置不同的级别和发送周期。让紧急问题快速得到处理,不紧急的问题不频繁发送,达到降噪的目的。
举个例子:
【P0业务告警】5分钟XX业务失败1000笔,成功率0%
【P1业务告警】5分钟XX业务失败100笔,成功率97%
【P2业务告警】过去1小时XX业务失败10笔,成功率99.9%
(三)减少巡检类通知,建立系统以查代推,用异常报警代替部分巡检通知
信息的接收有推和拉两种方式。通知属于推动信息。自己主动查询属于拉取信息。在上面告警和通知的思路图中,我们主要希望推送的信息是变化的信息,像巡检类中,各个指标没有什么变化,更好的一种方式是自己主动去查询。查询的时候不仅要看数值,还希望看到一段时间的变化趋势或者成为态势。如果指标发生了变化,可以采用主动推动的方式,便于及时处理。
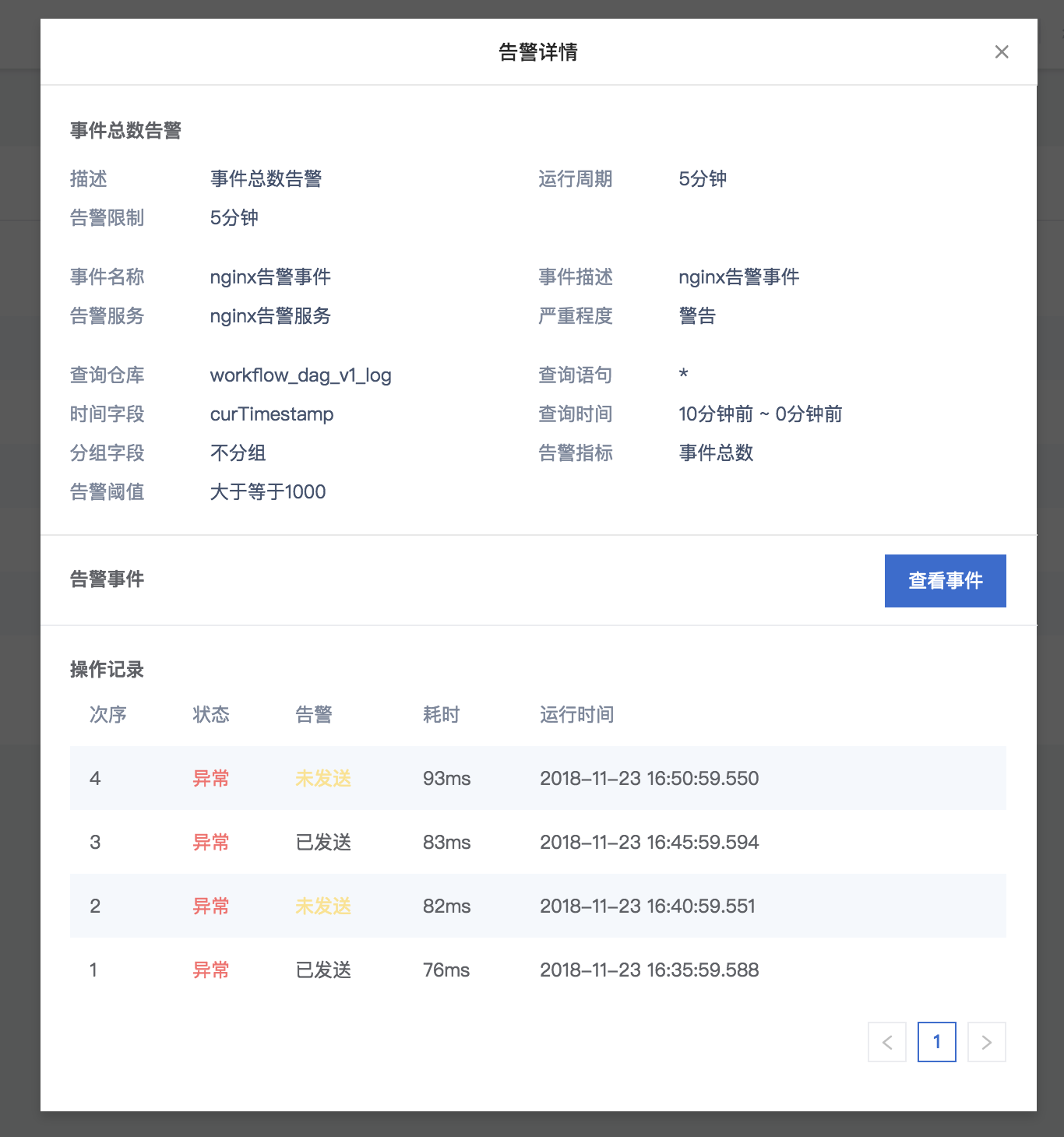
例如:系统巡检CPU、内存、磁盘都正常的话,可以以日报或者周报、月报的形式推动。而小时级的巡检数据正常情况下落库到系统中。需要了解的人员可以去系统中查询。异常情况,比如CPU超过阈值则以告警的形式推送。这样,系统运行正常的话,通知和报警都很少。
(四)聚合压缩
同类报警需要聚合压缩,这方面业界相关的资料就很多了。为了找到同类信息,算法、人工智能都可以用上。
(五)告警闭环
告警触发-->告警确认--->告警处理-->恢复信息
看到一些公司在初期设计的告警就是有问题的时候把报警发出来。其他事情都是手工来做。更好的一种做法举例是这样:
【P0业务告警】5分钟XX业务失败1000笔,成功率0%
对应的监控大盘链接为:链接名
对于监控链接为:链接名
点我确认接收到告警 点我确认你在处理告警
这样,有人点击了:确认接收到告警,其他人就知道可以快速联系到谁,节省系统恢复的时间。有人点击了:点我确认你在处理告警,则可以暂停此告警的发送,避免告警风暴。
告警恢复后要有恢复通知:
【P0业务告警恢复】5分钟XX业务失败1000笔,成功率0% -- 已恢复,目前5分钟XX业务失败1笔,成功率99.99%
(六)告警控制
告警控制的手段有自动或手动关闭报警、未处理告警频率递减等。例如:系统如果在发布时由于机器数量降低有1%的CPU使用率上升,则可以在发布时手动或者发布操作关联降级CPU使用率报警。
再比如:在确实出现故障的时候,故障一直没有恢复,本来5分钟报警一次,已经报警了三次了。再连续的报警已经意义不大,可降级成1个小时1次。
(七)明确责任人,以治降噪
告警降噪最好的办法是有问题就处理,问题解决了,告警就消失了。可实际上大家经常面临的问题是:报警大家都收到了,谁也不去解决。所以需要在告警中就明确处理人员:比如当日值班人员或者模块负责人。