ES分片副本设置及集群部署
一、概念 1、分片
一个 索引 我们在 称作 分片 。 一个 索引 是分片的集合。 当 在索引中搜索的时候, 他发送查询到每一个属于索引的分片( 索引),然后合并每个分片的结果到一个全局的结果集。
分片很重要,主要有两方面的原因:
1、允许水平分割 / 扩展我们的内容容量。
2、允许在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量。
分片的配置必须在创建索引的时候就指定分片数量,因为这直接决定了数据的路由规则,索引不支持在运行中的索引进行动态修改,副本则可以。
2、副本
允许你创建分片的一份或多份拷贝,这些拷贝叫做副本分片,目的就是解决在在某个分片或节点因出现问题时候,能提供故障转移的机制。
副本分片很重要,有两个主要原因:
1、在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到副本分片从不与主分片置于同一节点上是非常重要的。
2、扩展你的搜索量/吞吐量,因为搜索可以在所有的副本上并行运行。
在运行中的集群上是可以动态调整副本分片数目的,我们可以按需伸缩集群。让我们把
副本数从默认的 1 增加到 2。
PUT your_index/_settings
{"number_of_replicas" : 2
}
二、分片副本设置 1、分配 3个主分片和一份副本分配
PUT your_index
{"mappings" : {"properties" : {#索引字段(略)}}"settings" : {"number_of_shards" : 3,"number_of_replicas" : 1}
}配置之后总共有3个主分片f1,f2,f3,并且每个分片有自己的一个副本分片,f1-back,f2-back,f3-back,总共6个分片。
2、集群部署
1、分片肯定以为着es的集群部署,那么怎样设置分配和副本才能使得集群部署合理呢?
如果我们按照1那样配置,并且只有一台机器
集群健康值:( 3 of 6 ):表示当前集群的全部主分片都正常运行,但是副本分片没有全部处在正常状态。
在同一个节点上既保存原始数据又保存副本是没有意义的,因为一旦失去了那个节点,我们也将丢失该节点 上的所有副本数据。
虽然当前集群是正常运行的,但存在丢失数据的风险。
2、当我们有3台服务器,并且在每个启动的es都配置文件中都完成了集群监听配置
#在节点1配置节点2和3的地址
discovery.seed_hosts: ["localhost:9302", "localhost:9303"]集群健康值:green( 3 of 6 ):表示所有 6 个分片(包括 3 个主分片和 3 个副本分片)都在正常运行。
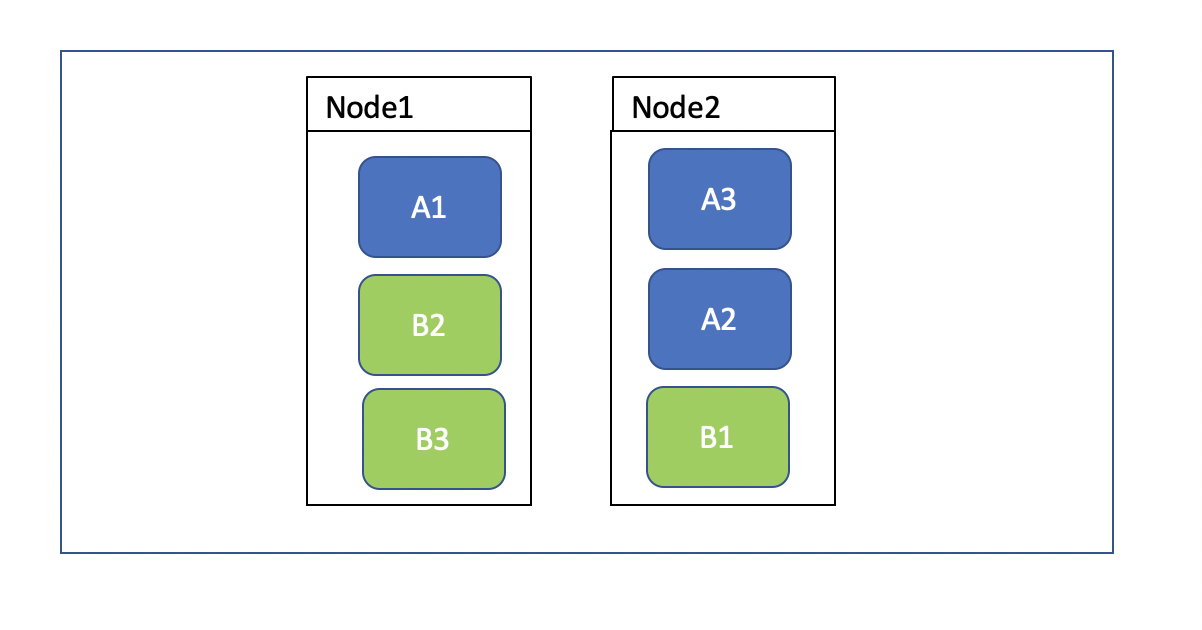
边框加粗的是主分片,没加粗的是副本分片,从中我们也可以看出es自动分片并没有强迫症,但是却严格遵守水平扩容,以及故障转移的配置规格,但节点一挂了(服务器node-1),此时,副本0(node-2)副本1(node-3)会通过选举成为主分片,保证了索引的正常运行。
三、路由计算
当索引一个文档的时候,文档会被存储到一个主分片中。 如何知道一个文档应该存放到哪个分片中呢?当我们创建文档时,它如何决定这个文档应当被存储在分片 1 还是分片 2 中呢?首先这肯定不会是随机的,否则将来要获取文档的时候我们就不知道从何处寻找了。实际上,这个过程是根据下面这个公式决定的:
shard = hash(routing) % number_of_primary_shards四、集群中es的数据增删改查操作流程 1、数据写流程(增、删)
新建、删除请求都是写操作, 必须在主分片上面完成之后才能被复制到相关的副本分片。
当删除某个数据时,es并不会直接物理删除,而是将原文档的数据标记为删除,然后重新写入新的文档数据,被标记删除的文档数据,会有一定的策略进行统一收集再真正进行物理删除操作
2、更新流程 & 批量操作(改)
更新一个文档的部分数据
客户端向Node 1发送更新请求。它将请求转发到主分片所在的Node 3 。Node3从主分片检索文档,修改字段中的JSON,并且尝试重新索引主分片的文档。如果文档已经被另一个进程修改,它会重试步骤3,超过次后放弃。如果 Node 3成功地更新文档,它将新版本的文档并行转发到Node 1和 Node2上的副本分片,重新建立索引。一旦所有副本分片都返回成功,Node 3向协调节点也返回成功,协调节点向客户端返回成功。
当主分片把更改转发到副本分片时, 它不会转发更新请求。 相反,它转发完整文档的新版本。请记住,这些更改将会异步转发到副本分片,并且不能保证它们以发送它们相同的顺序到达。 如果 仅转发更改请求,则可能以错误的顺序应用更改,导致得到损坏的文档。
3、数据读流程(查)
五、优化 1、减少 的次数
在新增数据时,采用了延迟写入的策略,默认情况下索引的 为1 秒。
将待写入的数据先写到内存中,超过 1 秒(默认)时就会触发一次 ,然后 会把内存中的的数据刷新到操作系统的文件缓存系统中。
如果我们对搜索的实效性要求不高,可以将 周期延长,例如 30 秒。
这样还可以有效地减少段刷新次数,但这同时意味着需要消耗更多的 Heap 内存。
2、加大 Flush 设置
Flush 的主要目的是把文件缓存系统中的段持久化到硬盘,当 的数据量达到 512MB 或者 30 分钟时,会触发一次 Flush。
index.. 参数的默认值是 512MB,我们进行修改。
增加参数值意味着文件缓存系统中可能需要存储更多的数据,所以我们需要为操作系统的文件缓存系统留下足够的空间。
3、减少副本的数量
ES 为了保证集群的可用性,提供了 (副本)支持,然而每个副本也会执行分析、索引及可能的合并过程,所以 的数量会严重影响写索引的效率。
当写索引时,需要把写入的数据都同步到副本节点,副本节点越多,写索引的效率就越慢。
如果我们需要大批量进行写入操作,可以先禁止复制,设置
index.: 0 关闭副本。在写入完成后, 修改回正常的状态。