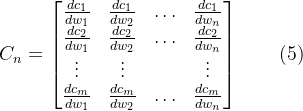【论文简述】Generalized Binary Search Network
2. 发表年份:2022
3. 发表期刊:CVPR
4. 关键词:MVS、3D重建、二值搜索、从粗到细
5. 探索动机:3D代价体非常消耗内存。现有的工作可以在一定程度上减缓这个问题,但普遍导致精度下降。深度假设数,在导致较大的内存占用中起着主导作用。
, a is that 3D cost are -. works made to this issue via the of maps , using a -to-fine that of maps while the depth , and 3D CNN or RNN. the can be to some , lower is . The size of 3D cost , the depth , plays a role in a large .
6. 工作目标:由于3D代价体在模型效率和有效性方面的重要性,一个关键的问题自然出现了:在保持尽可能小的内存开销的同时,确保精度的最小体大小是多少?
The can be seen as a dense that all depth to a in a . The -to-fine a multi- , which from a level and the . , these two types of both dense in each stage. We argue that the dense does not due to a much space and model , to in model .由于预测空间大得多,密集搜索不一定能保证更高的精度,并且显著增加了模型的复杂性,导致模型训练中的优化难度更高。
7. 核心思想:本文通过从离散搜索策略的角度探索这个问题,以确定最小深度假设数。
8. 实验结果:又小又好
Our state-of-the-art on DTU and Tanks & . , on DTU, we an score of 0.289 (lower is ), the best , and also a of 48.0% to 54.1% to .
9.论文&代码下载:
二、实现过程 1. 概述
总体框架如图所示。它主要由两部分组成,即用于学习视觉图像表达的2D CNN网络和用于迭代深度估计的广义二进制搜索网络。GBi-Net包含K个搜索阶段,在每个搜索阶段,首先通过参考特征图和源特征图在特定对应比例下的单应性变化和4个深度假设,来计算3D代价体并进行融合。然后利用3D CNN对代价体进行正则化,以进行深度标签预测。广义二进制搜索能够根据预测的标签迭代初始化和更新深度假设。在每两个阶段中,网络处理相同尺度的特征图,并共享网络参数。最后,根据深度图GT计算出一个训练整个网络的One-hot标签。
2.图像编码
使用特征金字塔网络(FPN)作为图像编码器,学习具有共享网络参数的图像的通用表示,共4层输出:(1/8,1/8,32),(1/4,1/4,32),(1/2,1/2,16),(1,1,8),最后的输出层使用可变形卷积。
3.代价体正则化

给定第k个搜索阶段的D个深度假设,即dk,通过对学习到的图像特征进行单应性变化和插值构建各视图特征体,对每个源视角特征体与参考视角特征体计算分组内积得到各视角的2视图代价体。具体来说,将特征图的通道沿通道维度划分为Ng组,因此每个特征组都有Nc/Ng通道。Fgi是Fi的第g个特征组。那么可以从Fi计算出第i个代价体Vi,如下所示:
其中〈·,·〉表示通过内积操作进行相关计算。在构建每个2视图代价体后,应用了几个3D CNN层来预测一组像素权重矩阵Wi。然后我们用Wi,通过加权融合将这些代价体融合为一个代价体V,如下所示:
融合的3D代价体V然后由3D正则化UNet,逐渐将V的通道减小到1,输出大小为D, H, W。最后,沿着D维执行(·)函数,生成用于计算训练损失和标签的概率体P。
4. MVS的二分查找
在这项工作中,从离散搜索的角度探索了一种合理的最优采样策略,以获得高效的MVS,并提出了一种二叉搜索方法(Bi-Net)。具体来说:
1. 不是直接在给定深度范围R中采样深度值,对于第k个搜索阶段,将深度范围划分为两个相等的箱子Bk,j(j=1,2),B1,j的箱子宽度为第一阶段为R/2,从左到右的三个边(分隔位置)ek,m(m=1,2,3)。由于不能直接使用离散箱来warp特征图,对这两个箱的中心点(即相邻两条边的中点)进行采样,以表示箱的深度假设,然后构建代价体并对这两个箱进行标签预测:
2. 深度假设的预测标签表示真实深度值是否在相应的箱子中。在第k个搜索阶段,在网络输出概率体P后,沿P的D维应用(·)操作,返回标签j,表明真实深度值在箱子Bk,j中。通过将Bk,j划分为两个等宽的箱子Bk+1,1和Bk+1,2,可以进一步生成第(k+1)搜索阶段的新2个箱子,该阶段对应的三条边可以定义为(上一阶段搜索到箱子的两边及中点为新的三个边)
3. 然后,从第(k+1)阶段的箱子Bk+1,1和Bk+1,2的中心点取样新的深度假设。在所提出的二进制搜索中,初始深度区间宽度为R/2,在第k阶段,深度区间宽度为R/(2**k)。
二分查找策略,将当前深度范围划分为多个箱子,而不是直接在给定深度范围R进行采样,3D代价体的深度维数可以减少到2,内存占用显著减少。整个MVS网络的内存开销由2D图像编码器主导,而不再由3D代价体控制。在实验中,MVS的二分查找策略取得了令人满意的结果。然而,网络分类错误的问题会导致优化不稳定和精度下降。
5. MVS的泛化的二分查找
为解决MVS二分查找中的错误积累和训练问题,将其扩展为MVS的泛化二分查找。具体而言,进一步设计了三种有效的机制,即容错箱、梯度掩码优化和高效梯度更新机制,对二进制搜索方法进行了实质性改进。
为了使网络具有一定的容忍预测误差的能力,在Bk+1,1的左侧和Bk+1,2的右侧分别添加一个小箱子,此过程称为容错箱(ETB)(下图虚线部分,相当于多了两个深度假设,算法类似,找中心点)。
容错箱。为了使网络具有一定的容忍预测误差的能力,在Bk+1,1的左侧和Bk+1,2的右侧分别添加一个小箱子,此过程称为容错箱(ETB)。下图虚线部分,相当于多了两个深度假设,算法类似,找中心点。容错箱将深度假设的采样扩展到二分搜索中两个原始箱的范围之外,从而使网络能够纠正预测,并在一定程度上减少误差积累。由于深度假设的数量现在是D,所以也改变了第一阶段的深度假设的初始化。当初始深度范围R被分成D个箱子时,初始箱子宽度为R/D,第k阶段料仓宽度为R/(D × 2k−1)。
在实现中,只在两边垫了1个ETB,因此深度假设数为4,即D = 4。在实验中,观察到深度预测精度显著提高,同时值得注意的是,内存消耗可以与原始二值搜索相同,因为内存仍然由2D图像编码器主导。使用容错箱,当真实深度在第3个搜索阶段的B3,4时,网络可以预测到正确的标签为4,而原始二分搜索失败。

梯度掩码优化。有监督训练中,在第k个搜索阶段获得箱子后,将真实深度图GT转换为具有一个One-hot编码的体G,计算哪个箱子被深度值GT占据。迭代搜索中的一个问题是,某些像素的深度值GT可能超出了预测箱子。在这种情况下,不存在有效标签,无法计算损失。这是网络优化中的一个关键问题。从粗到细方法通常利用连续回归损失,而具有离散分类损失的R-MVS广泛使用密集空间离散化。
在中,根据预测箱和深度图GT计算每个阶段的掩码图。如果某个像素的深度GT在当前箱子中,则认为该像素有效。设像素的GT深度为dgt,当前bin边为em。那么像素只有在以下情况下才有效:
仅使用有效像素的损失来梯度更新网络中的参数,所有无效像素的梯度不会累积。通过此过程,可以成功地训练Bi-Net和GBi-Net。梯度掩膜优化类似于流行的自步学习(self-paced ),在自步学习中,一开始,网络训练只涉及简单样本(即简单像素),随着优化的进行,网络可以预测更精确的困难像素标签,大多数像素最终将参与学习过程。
6. 网络优化
损失函数。适用于概率体和真实占用体G的标准交叉损失。有效掩码图首先获得一组有效像素Ω q,然后计算所有有效像素的平均损失如下:
节约内存的训练。多阶段的MVS方法通常对所有阶段的损失进行平均然后反向传播梯度。然而,由于梯度在不同阶段的积累,这种训练策略消耗了大量的内存。在我们的GBi-Net,用一种更高效的内存方式训练网络。具体来说,在每个阶段之后立即计算损失和反向传播梯度。梯度不会跨阶段累积,因此最大内存开销不会超过规模最大的阶段。为了使多阶段训练更加稳定,首先将最大搜索阶段数设置为2,并随着epoch数的增加逐渐增加。
7. 实验
7.1. 数据集
DTU、、Tanks and
7.2. 实现细节
训练细节:在DTU数据集训练及评估;在数据集上进行训练,在数据集评估。提出了一种在线随机裁剪数据增强。首先将图像从裁剪到,再从1024×1280的图像中随机裁剪512×640的图像。理由是,从较大的图像中裁剪较小的图像有助于学习较大图像比例的其他特征,而不会增加训练开销。在数据集上进行训练时,使用原始分辨率576×768。.对于所有序列:N=5,即1个参考图像和4个源图像。采用中提出的鲁棒训练策略,以更好地学习像素权重。最大阶段编号设置为8。对于每两个阶段,共享相同的特征图比例和3D-CNN网络参数。用Adam 优化器对整个网络进行了16个阶段的优化,初始学习率为0.0001,在10、12和14个阶段后,将其缩小了2倍。在两块 RTX 3090 GPU上训练,batch size=4。
测试细节:在DTU训练集上训练的模型用于在DTU测试集上进行测试。N=5,分辨率为1152×1600。每个样本测试需要0.61秒。在数据集上训练的模型用于在 数据集上进行测试。分辨率为1024×1920或1024×2048,以使图像可被64整除,N=7。所有测试均在 RTX 3090 GPU上进行。
7.3. 与先进技术的比较