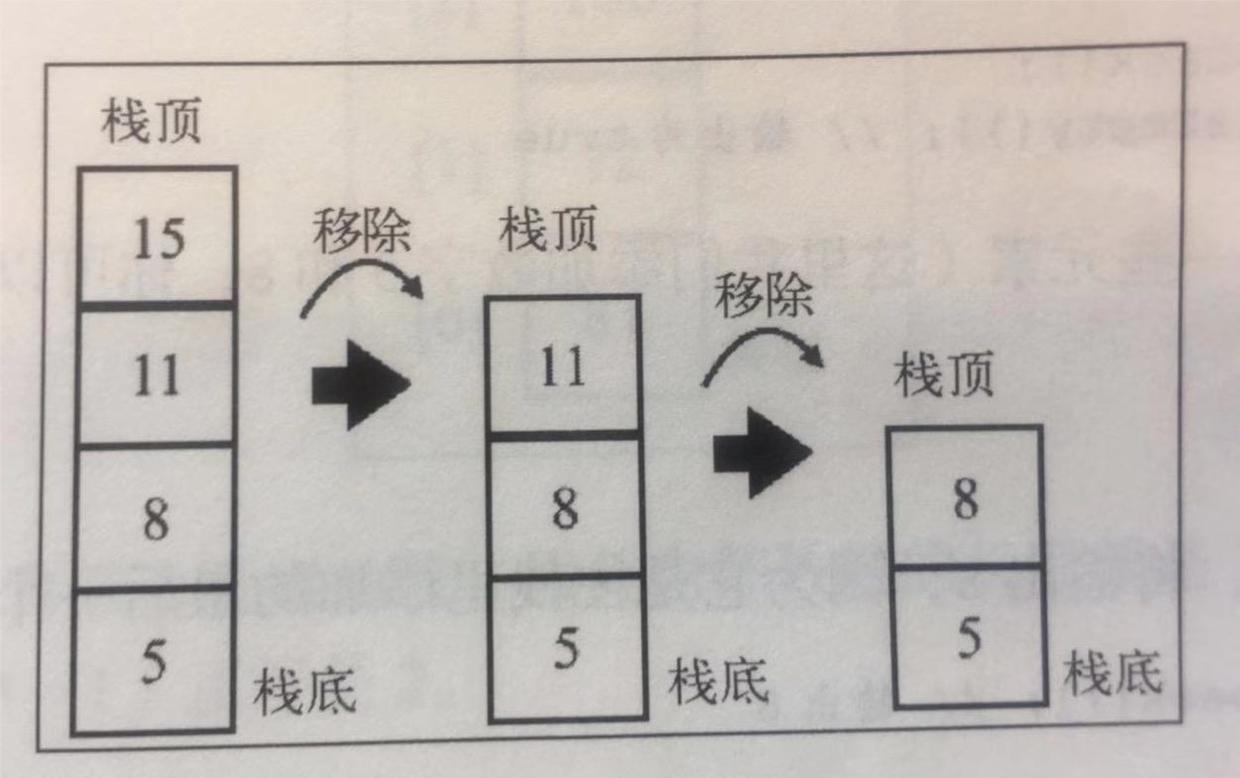
Collection的接口储存数据的特点
的接口储存数据的特点
单列集合,用来存储一个一个的对象
常用方法
add(), (),size(),(),clear(),(),(),(),(),()(交集),(),(),(),()
接口与数组的相互转换
();
.(new [ ]{ })
遍历的两中方式:
使用迭代器:设计模式的一中,用来遍历元素
coll.()返回一个迭代器实例
for each
的子接口( List 接口):
源码分析:
4.3
通过构造器创建对象时候,底层都创建了长度为10的数组.在扩容方面,默认扩容为原来长度的两倍
5.存储元素的要求:
添加的对象,所在的类要重写方法
,,三者的异同?
同:三个类都是实现了list接口,存储数的特点都是存储有序的可重复数据.
不同:见上
Set接口
1.存储数据的特点:无序的,不可重复的元素
1.无序性:存储元素在底层数组中并非按照数组索引的顺序进行添加,而是根据数据的哈希值决定
2.不可重复性:保证添加的元素按照判断时,不能返回true,即相同的元素只能添加一个
2.元素添加的过程
3.常见的方法
都是里的方法
4.常用的实现类:
接口:
set接口:
:作为set接口的主要实现类,线程是不安全的,可以存储null值
LinkedHashSet:可以按照添加的顺序遍历,可以按照添加的顺序遍历,底层多了链表LinkedhashSet作为hashset的子类,在添加数据的同时,每个数据还维护了两个引用,记录此数据的前一个引用和后一个应用 treeset:可以按照添加对象的指定属性进行排序
5.存储对象所在类要求:
和:添加数据,其所在的类一定要重写和equal方法:
判别标准:
自然排序中,比较两个对象是否相同:(),返回0,不在是
定制排序中,比较两个对象是否象同的标准为返回0,不再是方法
6.的使用:要去必须相同的对象
练习 的定制排序和定制排序
public class Practice {@Testpublic void test1(){TreeSet set = new TreeSet();Employee e1 = new Employee("l德华",55,new MyDate(1965,5,4));Employee e2 = new Employee("c井空",54,new MyDate(1912,8,4));Employee e3 = new Employee("d桥未久",53,new MyDate(1865,5,4));Employee e4 = new Employee("g富城",52,new MyDate(1765,6,4));Employee e5 = new Employee("l朝伟",51,new MyDate(1665,5,4));set.add(e1);set.add(e2);set.add(e3);set.add(e4);set.add(e5);System.out.println(set);}@Testpublic void test2(){TreeSet set = new TreeSet(new Comparator() {@Overridepublic int compare(Object o1, Object o2) {if(o1 instanceof Employee && o2 instanceof Employee){Employee e1 = (Employee) o1;Employee e2 = (Employee) o2;MyDate b1 = e1.getBirthday();MyDate b2 = e2.getBirthday();int minYear = b1.getYear() - b2.getYear();if(minYear != 0){return minYear;}int minMonth = b1.getMonth() - b2.getMonth();if(minMonth != 0){return minMonth;}return b1.getDay() - b2.getDay();}return 0;}});Employee e1 = new Employee("l德华",55,new MyDate(1965,5,4));Employee e2 = new Employee("c井空",54,new MyDate(1965,8,4));Employee e3 = new Employee("d桥未久",53,new MyDate(1865,5,4));Employee e4 = new Employee("g富城",52,new MyDate(1765,6,4));Employee e5 = new Employee("l朝伟",51,new MyDate(1665,5,4));set.add(e1);set.add(e2);set.add(e3);set.add(e4);set.add(e5);System.out.println(set);}
}
面试题:
在list当中去除重读数据值
set可做,效率高
set.addAll(list)
return new ArrayList(set);
set里,先找hash值,
Map接口
存储双列数据:双列数据,用来存储key-value的数据
实现类:
:线程不安全,效率高,可也以存储null的value
:作为古老的实现类:线程是安全的,效率低,不能存储null的key和value
对于平凡的遍历操作,此类执行效率高于
保证遍历map元素时,可以按照添加的顺序遍历.
在原有的map底层结构基础上,添加了一对指针
可以按照添加的进行排序,实现排序遍历,此时考虑key的定制排序,或自然排序
底层使用的红黑树
底层:
jdk7寄之前:数组+链表
jdk8:数组+链表+红黑树
map结构的理解
map放的是entry
entry里有key,value属性
Map中的key时无序的,不可重复的,使用set存储所有的key,key所在的类要重写方法,和方法(以为例)
Map中的value是无序的,但是是可重复的,使用存储所有的value ----->value所在的类要重写方法
一个键值对:key-value构成了一个entry对象.
1.底层实现:
jdk7:
以jdk7 为例:
map = new ()
底层:在实例化以后底层创建了一个长度为16的一维数组Entry[] table;
…可能已经执行了多次put
map.put(key1,):
首先:计算key1所在类的的哈希值(调用方法),此哈希值经过某种计算以后,得到在entry数组中的存放位置.
如果此位置上的数据为空,key1- 添加成功.
如果此位置上的数据不为空,(意味着此位之上存在一个或多个数据(以链表的形式存在的)),比较key1和已经存在的一个或多个数据的hash值:
都不相同:key1 - 添加成功-------情况2
和某一个数据相同的话:继续比较方法,调用key1所在类的方法比较:
如果返回false:此时key-value添加成功.-------情况3
如果返回true:使用替换相同key的value值.
补充:关于情况2和情况3:此时七上,为头插法
扩容:在不断地添加过程中,会涉及到扩容问题,默认的扩容方式:扩容为原来的二倍,并将原有的数据复制过来
jdk8相较于7的不同
1.new ()对象时,没有创建一个数组
2.jdk8的数组是node[ ]类型的数组,而非entry[ ]
3.put方法时,首次调用put方法时,底层创建长度为16的数组
4.jdk7底层结构只有数组+链表,jdk8中底层结构:数组+链表+红黑树
当数组的某一个索引位置上的元素存在的个数 > 8 且当前数组的长度超过64,此时索引位置上的数据改为红黑树存储来提高查找效率
为啥要提前扩容呢?
尽可能让出现链表的情况少一些
四.
能够记录添加元素的先后顺序
Map中常用方法:
@Testpublic void test1(){Map map = new HashMap();//添加map.put("AA",123);map.put("BB",123);//修改map.put("AA",23);map.put(45,123);Map map1 = new HashMap();map1.put("CC",123);map1.put("DD",123);Object value = map1.remove("CC");System.out.println(value);map.clear();System.out.println(map);map.containsKey("AA");map.containsValue(123);}
@Testpublic void test() {Map<String,Integer> map = new HashMap();//添加map.put("AA", 123);map.put("BB", 123);//修改map.put("AA", 23);//遍历所有的key集:Set set = map.keySet();//遍历所有的valuesCollection values = map.values();//遍历所有的keyvaluefor(Map.Entry<String,Integer> entry : map.entrySet()){System.out.println(entry.getValue());}}
常用方法:
添加:put
删除:
修改:put
查询:get
长度:size
遍历:,,
工具类,操作,Map
面试题: 和 的区别
是接口,是工具类
public class CollectionsTest {@Testpublic void test1(){List<Integer> list = new ArrayList<>();list.add(123);list.add(43);list.add(765);list.add(-97);list.add(9);Collections.reverse(list);System.out.println(list);int a = Collections.frequency(list,765);System.out.println(a);Integer max = Collections.max(list);System.out.println(max);}
}
负载因子值的大小面对有什么影响:
负载因子的大小决定了的数据密度
负载因子越大,发生hash碰撞的几率越高,数组中的链表越容易长,造成查询的或者插入时的效率降低
负载因子越容易触发扩容,数据密度也越小,意味着发生碰撞的几率越小,数组中的链表也越短,查询和插入时比较的次数也越小,性能会更高,但是会浪费一定的空间,经常扩容也会影响性能,建议初始的时候,数组空间给大一点,