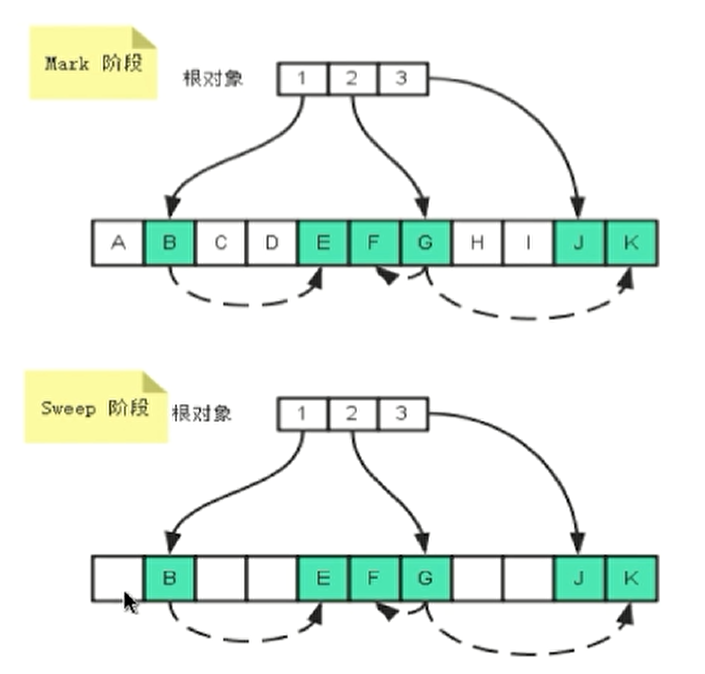
异常检测(1)—初识异常检测
1.概念
异常一般是指与标准值(预期值)有偏离的样本点,也就是跟绝大部分数据“长的不一样” 。异常往往是“有价值”的事情,我们对异常的成因感兴趣 。
2.类别 3.应用 4.方法 (1)传统方法 (2)集成方法
集成算法是将多个基检测器的输出结合起来(与类似),一些算法在数据集的某些子集上表现很好,一些算法在其他子集上表现很好,然后集合起来,使得输出更具鲁棒性。
孤立森林:孤立森林是用一个随机超平面切割数据空间(数据集),切一次可以生成两个子空间。然后继续用随机超平面来切割每个子空间并循环,直到每个子空间只有一个数据点为止。直观上来讲,那些具有高密度的簇需要被切很多次才会将其分离,而那些低密度的点很快就被单独分配到一个子空间了。孤立森林认为这些很快被孤立的点就是异常点。

如上图,d点最早被分割开,所以d点较大概率为异常点。
(3)机器学习方法
在有标签的情况下,可以使用树模型(gbdt,等)进行分类,缺点是异常检测场景下数据标签是不均衡的,但是利用机器学习算法的好处是可以构造不同特征
5.常用库:PyOD、、TODS 6.应用
#导库
from pyod.models.knn import KNN
#generate_data样本生成函数
from pyod.utils.data import generate_data,evaluate_print
from pyod.utils.example import visualize
#准备数据
#contamination异常数据的百分比,n_train训练集的数量,n_test测试集的数量,n_features产生数据的特征数
X_train,y_train,X_test, y_test = generate_data(n_train=500,n_test=100,n_features=2,contamination=0.1)
#KNN检测器
clf_name='KNN'
clf=KNN()#初始化检测器
clf.fit(X_train)#训练检测器模型
#得到训练集的预测标签和异常值得分
y_train_pred=clf.labels_#返回训练集上的分类标签(0为正常值,1为异常值)
y_train_scores=clf.decision_scores_#返回训练数据上的异常值(值越大越异常)
#在测试集上进行训练
y_test_pred = clf.predict(X_test) #返回测试集上的分类标签
y_test_scores = clf.decision_function(X_test)#异常值(值越大越异常)
#使用ROC和Precision @ Rank n评估预测
print("\nOn Training Data:")
evaluate_print(clf_name, y_train, y_train_scores)
print("\nOn Test Data:")
evaluate_print(clf_name, y_test, y_test_scores)
运行结果:
On Training Data:
KNN ROC:0.9974, precision @ rank n:0.98On Test Data:
KNN ROC:1.0, precision @ rank n:1.0
#可视化所有示例
visualize(clf_name, X_train, y_train, X_test, y_test, y_train_pred,y_test_pred, show_figure=True, save_figure=False)
运行结果: