【Python】简单爬虫抓取知乎专栏文章标题和链接、存储进CSV
文章目录
今天突发奇想,想要爬取一下知乎专栏文章的标题和链接,看看某个作者到底在这大几百几千篇文章中写了什么。
1. 观察网页
以为例,我们所需要的每篇文章的所有信息,都被分别包括在一个类名为 的 div 标签对中:
更准确的说,是一个类名为 -title 的 标题元素中:
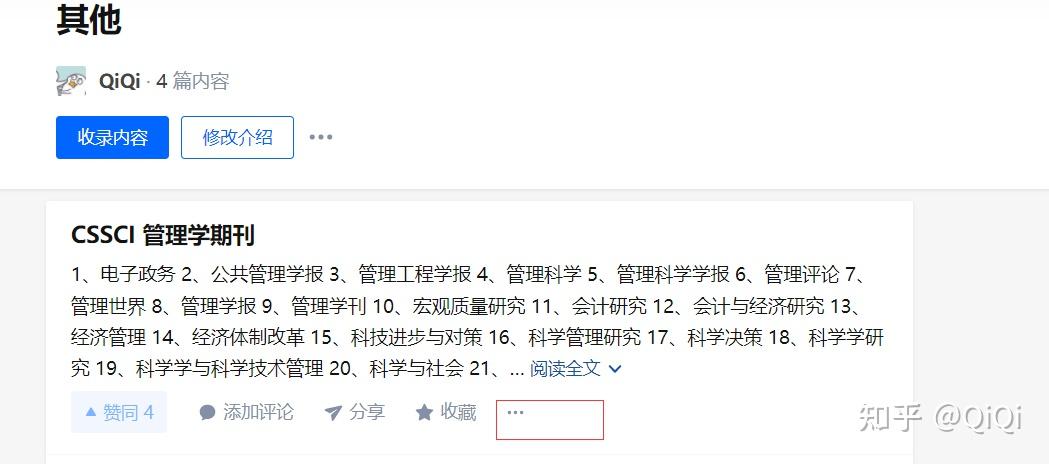
此外,还发现知乎专栏并不是一次性加载完该专栏的所有文章,而是随着侧滑栏向下滑动而逐渐加载,滑动到底部时以每10篇文章为单位进行加载,并在HTML文档中生成新的 元素:
这就有点麻烦了,不过也不算太难。进一步观察发现,每次加载新文章时会发送一个 GET 请求,返回的是JSON数据:
其中包含了我们想要的所有信息,包括文章标题、链接、摘要、作者等等:
因此我们只需要不断请求这些JSON数据,进行解析得到结果,最后写入文件即可。
2. 实际代码
代码如下,就不仔细讲解了,反正很简单:
# -*- coding: utf-8 -*-
import os
import time
import requests
import csvzhihuColumn = "c_1034016963944755200" # 自行替换专栏编号,此处是自娱自乐的游戏访谈录(在URL中的编号)
startURL = "https://www.zhihu.com/api/v4/columns/" + zhihuColumn + "/items?limit=10&offset={}"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:91.0) Gecko/20100101 Firefox/91.0"}# 输入URL,得到JSON数据
def getJSON(url):try:r = requests.get(url, headers = headers)r.raise_for_status() # 响应状态码,出错则抛出异常r.encoding = r.apparent_encodingreturn r.json()except Exception as ex:print(type(ex))time.sleep(10)return getJSON(url)# 输入文章总数,输出所有文章标题和链接的CSV文件
def process(total):num = 0 # 文章编号if (os.path.exists("zhihu.csv")): # 已经存在时则删除os.remove("zhihu.csv") with open("zhihu.csv", "a", encoding = "UTF-8", newline = '') as f:writer = csv.writer(f)writer.writerow(["编号", "标题", "链接"]) # csv表头部分for offset in range(0, total, 10):jsonData = getJSON(startURL.format(offset))items = jsonData["data"]for item in items:num = num + 1writer.writerow([num, item["title"], item["url"]])if __name__ == "__main__":jsonData = getJSON(startURL.format(0))process(jsonData["paging"]["totals"])
3. 运行效果