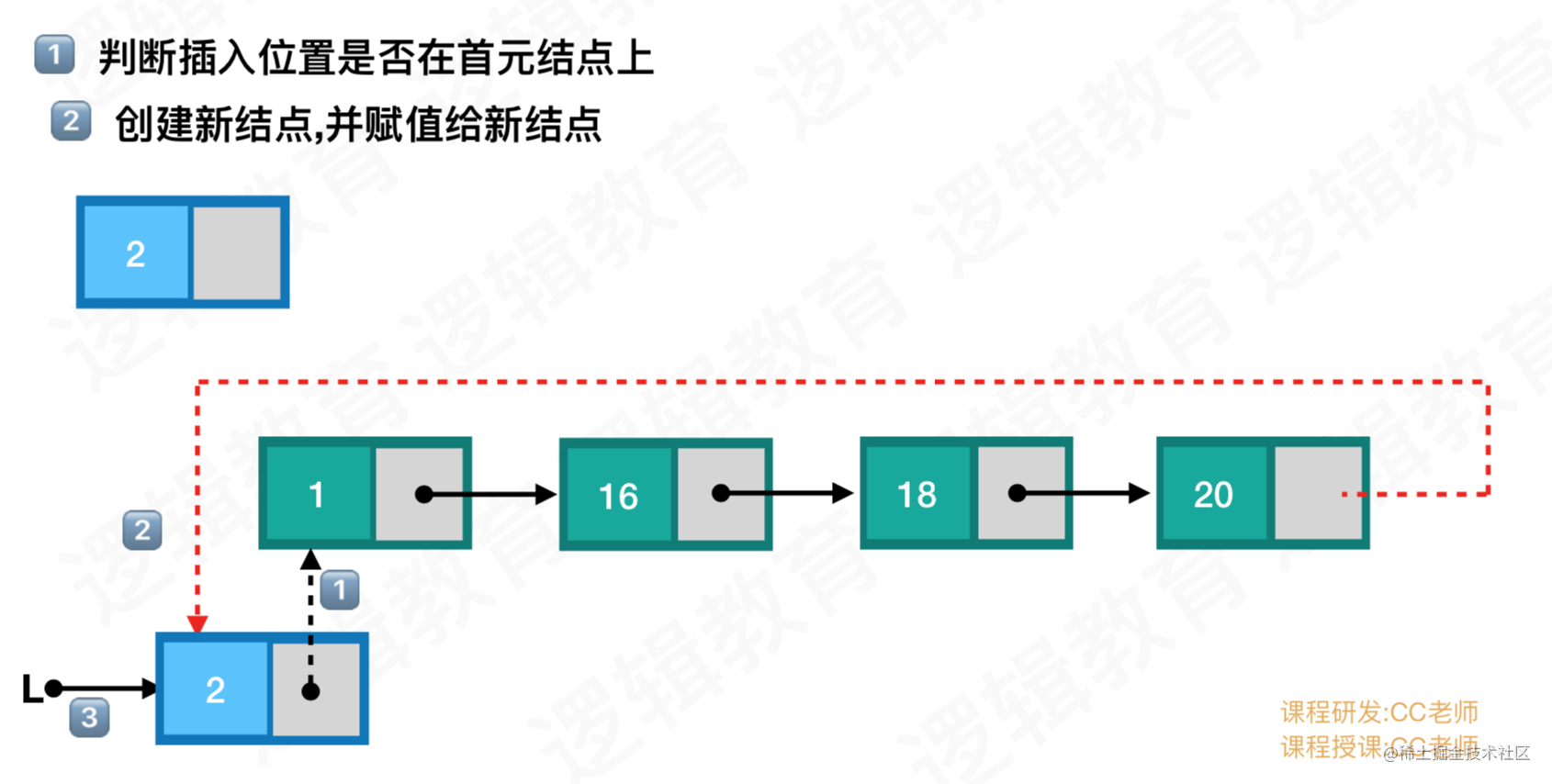
C++面试知识点
文中涉及语法等都是C++11相关语法。
参考了,文中3.1,3.2,4.1完全来源于该文。
后续有时间继续更新。
文章目录 1 基础相关 1.4 const关键字 1.5 指针和引用的区别1.6 C++动态内存分配1.7 内存 1.8 C++内置类型的长度1.9 类型推断 1.10 ,,和.11 C++宏定义 1.12 表达式 2 类相关 2.6 this指针2.7 友元`` 2.8 `move`和``语义 3 4 STL相关 4 其他琐碎问题5 常见实现 参考
1 基础相关 1.1 C++内存模型
emsp;C++程序的内存模型包含:
可以使用下面两个分别查看简略的内存模型和比较详细的内存模型:
size filename
size --format=sysv filename
$ size cpptext data bss dec hex filename3075 640 280 3995 f9b cpp
$ size --format=sysv cpp
cpp :
section size addr
.interp 28 4194872
.note.ABI-tag 32 4194900
.note.gnu.build-id 36 4194932
.gnu.hash 48 4194968
.dynsym 360 4195016
.dynstr 376 4195376
.gnu.version 30 4195752
.gnu.version_r 64 4195784
.rela.dyn 48 4195848
.rela.plt 216 4195896
.init 26 4196112
.plt 160 4196144
.plt.got 8 4196304
.text 994 4196320
.fini 9 4197316
.rodata 64 4197328
.eh_frame_hdr 108 4197392
.eh_frame 468 4197504
.init_array 24 6299120
.fini_array 8 6299144
.jcr 8 6299152
.dynamic 480 6299160
.got 8 6299640
.got.plt 96 6299648
.data 16 6299744
.bss 280 6299776
.comment 36 0
.debug_aranges 128 0
.debug_info 37413 0
.debug_abbrev 3498 0
.debug_line 2003 0
.debug_str 12648 0
.debug_ranges 64 0
Total 59785
1.2 ++,–前缀和后缀的区别
二者速度对比:从原理上来说由于后缀型操作需要维护一个备份相对前缀多一部分指令,因此要慢一些。但在实际使用用C++的内置类型前缀和后缀的速度差异不大,唯一需要注意的是自定义类型重载的前后缀操作在性能开销性能上可能有明显的差异。
下面是内置int类型执行1000万次前缀和后缀操作的耗时:
j=i++ cost time is 6.91351e-07
j=++i cost time is 6.88428e-07
1.3 关键字
修饰的变量作为静态变量,如果未经过初始化会存储在bss段,自动初始化为0,,如果经过初始化会存储在data段。
1.3.1 静态局部变量
静态局部变量一般指的是函数中的静态变量,对于局部静态变量需要注意的是:
函数中声明静态变量只有在其声明处会执行初始化的代码,之后的调用不再执行初始化的代码;该静态变量等同于函数的一个属性;局部静态变量的生命周期从声名处代码执行开始到程序结束。
void func()
{static int cnt = 5;++cnt;cout<<"cnt = "<<cnt<<endl;
}void local_static_test()
{for(int i = 0;i < 3;i ++){func();}
}
输出为:
cnt = 6
cnt = 7
cnt = 8
1.3.2 静态全局变量
静态全局变量对应的是全局变量,全局变量可以使用关键字表明外部可见,静态全局变量在本文件中的行为和普通的全局变量相同唯一的区别是在其他文件中不可见。
static int global_cnt = 4;
void global_func()
{global_cnt ++;cout<<"cnt = "<<global_cnt<<endl;
}void global_static_test()
{for(int i = 0;i < 3;i ++){global_func();}
}
输出为
cnt = 5
cnt = 6
cnt = 7
1.3.3 类的静态成员变量
类的静态成员变量就是在普通的成员变量之前添加关键字。需要注意的是:
静态成员初始化。带有const关键字的内置类型(int, bool等)静态成员变量可以在声明处初始化,自定义类型不可以。所有的类型都可以在类外使用 ::=value初始化,比如int ::len=0;静态成员初始化是要在对应的实现文件即cpp文件中进行初始化,不能在当前.h文件中初始化,会报重复定义的错误;静态成员是属于类的属性而不是某个实例的属性,即对于任何实例化的对象共享的是一个静态成员;静态成员可以声明为当前类的类型,普通成员只能声明为当前类型的指针或者引用。
class static_class
{
public:static static_class member; //正确//const static string msg=string("wrong"); //错误static string msg;const static int len = 4;const static string info;
};
const string info = string("i am a static const member");
string static_class::msg = string("i am static class");
void static_member_test()
{cout<<"before instanced:"<<static_class::msg<<endl;static_class obj1;static_class obj2;obj1.msg = string("i am obj1");obj2.msg = string("i am obj2");cout<<"msg from static_class"<<static_class::msg<<endl;cout<<"msg from obj1:"<<obj1.msg<<endl;cout<<"msg from obj2:"<<obj2.msg<<endl;
}
输出:
before instanced:i am static class
msg from static_classi am obj2
msg from obj1:i am obj2
msg from obj2:i am obj2
1.3.4 类的静态成员函数
静态成员函数和静态成员变量类似,声明使用关键字修饰即可,其属于整个类而不是某个实例。
静态成员变量可以成为静态成员函数的可选参数,而普通成员变量则不可以;静态成员函数可以调用静态成员函数和访问静态成员变量,不能访问普通成员函数和普通成员变量;普通成员函数可以访问所有成员函数和成员变量;静态成员函数不能被定义为。
class static_class
{
public:int size; static static_class member; //正确//const static string msg=string("wrong"); //错误static string msg;const static int len = 4;static void static_func(string info=msg);//static void static_func_II(int sz=size); //错误void non_static_func();
};
void static_class::non_static_func()
{static_func();msg = string("nonstatic");
}void static_class::static_func(string info)
{//size = 10; //错误msg = info; //正确//non_static_func(); //错误
}
1.3.5 模板中的静态成员
模板中的静态成员的所属关系是模板的实例化类。比如下面的例子,所有s共享一个len,所有的s共享一个len。
template<typename T>
class template_static_class
{
public:static T len;
};
template<typename T>
T template_static_class<T>::len = 3;void template_static_test()
{cout<<"int before instanced:"<<template_static_class<int>::len<<endl;template_static_class<int> int1;template_static_class<int> int2;int1.len = 4;int2.len = 5;cout<<"int after instanced:"<<template_static_class<int>::len<<endl;cout<<"int len from int 1:"<<int1.len<<endl;cout<<"int len from int 2:"<<int2.len<<endl;cout<<endl;cout<<"long before instanced:"<<template_static_class<long>::len<<endl;template_static_class<long> long1;template_static_class<long> long2;long1.len = 1100;long2.len = 1200;cout<<"long after instanced:"<<template_static_class<long>::len<<endl;cout<<"long len from long 1:"<<long1.len<<endl;cout<<"long len from long 2:"<<long2.len<<endl;
}
int before instanced:3
int after instanced:5
int len from int 1:5
int len from int 2:5long before instanced:3
long after instanced:1200
long len from long 1:1200
long len from long 2:1200
1.4 const关键字 1.4.1 const类型声明
const类型声明直接在类型前加const即可,指针类型可以同时添加两个const,如const int * const val;
const可以修饰变量不可修改;const声明的变量大部分情况下需要初始化,对于类的成员变量使用参数列表初始化即可。但是对于类中的静态常量只能使用静态成员的初始化方式初始化;const可以用来修饰函数的返回值,除了返回值是右值的情况大部分无意义。
const int val = 10;//const int no; //错误,未初始化const int no(val);const int *p = 0;int * const ptr = 0;const int * const pp = 0;
1.4.2 const的可见性
对于一般全局变量,我们如果需要在其他文件中使用需要在当前文件中使用声明过便可以使用,const类型的全局变量需要在定义处和声明处都加上关键字。
//1.cpp
extern const int rst = 0;
int snd = 2;
//2.cpp
extern const int rst;
extern int snd;
void func(){
snd = rst;
}
1.4.3 const 引用
const和引用的组合需要注意:
const的值不能绑定非const的引用;const引用可以绑定立即数;const引用可以绑定表达式;const引用可以绑定不同类型的可以隐式转换的变量。
其实理由也很容易理解:被const修饰的值只能访问,不能修改。
const int value = 10;const int& val_ref = val;//int & ref = val; //错误//int &ref = 42; //错误const int &const_ref = 43;//int &add_ref = val + value; //错误const int &add_ref = val + value;//long & long_ref = val; //错误const long &long_ref = val;
1.4.3 const和指针的组合
在这之前先提醒下,c++11中const整形变量可以作为数组声明的长度,之前版本的c++不支持。
const int size = 10;int array[size];
const和指针的组合其实不是很难理解记住,const右边是什么什么就不能改变的原则就可以了,比如对于int *const p;,const右边是p,而p是指针就表示为常指针。const int * p;,const右边是int则表示值不可变。
const * p;指向常量的指针。指针可变,值不可变。 * const p;指向变量的常指针。指针不可变,值可变。const * const p;指向常量的常指针。指针和值都不可变。
int len = 0;const int * p1;int * const p2 = &len;const int * const p3 = &len;
1.4.4 类和函数中的const
类中的const主要分为常量成员变量,const成员函数。
const成员变量定义和普通的成员变量相同,除了静态成员变量初始化时只能使用参数列表初始化。
非const成员函数和const成员函数可以构成重载(const成员函数表示成员函数中的变脸不可修改)。
class const_class{
public:const int len;const_class():len(2){}void print(){cout<<"void print()"<<endl;}void print() const{cout<<"void print() const"<<endl;}
};void const_class_test()
{const_class cls;const const_class cls1;cls.print();cls1.print();
}
输出:
void print()
void print() const
当const修饰函数返回值的时候只有指针时相对有具体意义。
const int * func(){return 0;
}const int & func2(){return 0;
}
//int * p = func(); //错误const int * p = func();//int& a = func2(); //错误const int& b = func2();
另外const修饰函数参数和普通的const含义等同。
1.4.5 const的不可变性
c语言中的const并不是严格不可变的那么c++中的const是不是严格不可变的?下面针对普通的const类型和类中的const成员变量进行测试。
对const取地址,尝试修改const的值:
const int val = 10;//val = 12; //错误,直接修改int *const_ptr = const_cast<int *>(&val);int *ptr = (int*)&val;*ptr = 12;*const_ptr = 333;cout<<"const value:"<< val<<endl;cout<< "const_cast:"<<*const_ptr<<endl;cout<<"address convert:"<<*ptr<<endl;
从输出可以看到使用和普通的类型转换取到的地址是同一块地址,原来的常量val值并未改变,猜测大概的原因是:常量本身存储与常量区,在用户对常量取地址时会在栈上新建一个该常量一个非常量的副本供用户操作,而实际的常量值依然安全:
const value:10
const_cast:333
address convert:333
emsp; 对类中的const成员变量进行修改尝试。
class const_class{public:const int len;};const_class obj;//obj.len = 0; //错误int * const_ptr = const_cast<int*>(&obj.len);int * ptr = (int*)(&obj.len);*ptr = 12;*const_ptr = 333;cout<<"const value:"<< obj.len<<endl;cout<< "const_cast:"<<*const_ptr<<endl;cout<<"address convert:"<<*ptr<<endl;
输出,修改成功:
const value:333
const_cast:333
address convert:333
因此可以认为类成员中的const关键字不同与普通的const,类中的可以修改,普通的无法修改,即便修改修改的也不是整整的const。要解释这个可以从内存模型上来说(下面是个人的猜测):普通的const存储与,存储区不可能修改,但是常量作为变量又不能有不能取地址的特权,因此当对普通常量取地址时编译器就在栈上新建一个该常量的副本,因此修改后无效。而对于类内的成员变量,由于常量不同与静态成员可以特殊存储,因为常量对于每一个实例都存在副本,将每一个示例对应的常量存储与特殊区域不太现实,因此类的常量成员变量和类本身存储在一起组成类,因此可以读取内存地址修改(对于c,c++能够读到地址没有什么不能修改)。
1.5 指针和引用的区别
指针本身是变量,存储的是指向的变量的地址。引用本身是别名,本身不能独立存在。
指针和引用最大的区别是指针可以修改而引用不能修改。需要注意的是下面的语句中p=value是将value的值赋值给val。
根本原理是程序进行编译时将指针和引用添加到符号表中,符号表上指针所对应的是指针变量自身的地址,引用符号表上对应的地址是引用所指向的对象的地址,且符号表固定后便不可修改,因此一般使用引用是安全的,可以认为引用是不可修改的指针。
int val = 0;int value = 10;int &p = val;p = value;
区别:
引用不可修改,指针可修改;引用不能为空,指针可为空;引用不能多级使用,指针可以多级使用。
int val = 0;
int ** ptr
int &&p = val; //非法
1.6 C++动态内存分配
C++中动态内存分配可以使用和new,二者都是在堆上分配内存。二者不同有:
new分配的内存要使用释放,分配的内存要使用free使用,不能交叉使用;只负责分配内存,需要用户自己初始化,new除了分配内存可以指定初始化方式,未指定则调用默认构造函数;开辟内存时传入的是字节数一般为size*(),而new直接传入需要的size即可;分配的内存返回的是void*,需要强制类型转换为目标类型,new返回的内存自带类型;分配失败返回NULL,new分配失败抛出异常;只有一个版本,而new``有普通的new,的new,const new和定位new```。
int *norm = new int(3); //普通new,出错抛出异常bad_allocint *no_throw = new(std::nothrow)int(3); //nothrow版本,失败不抛出异常const int *const_p = new int(3);int * const p_const = new int(3);int *buf = new int[1000];virtual_class* p_cls = new (buf)virtual_class(); //并不额外分配内存只在已经分配好的内存上创建相关的类p_cls->~virtual_class(); //需要显示的调用析构函数销毁delete [] buf;
需要注意的是定位new即 new实际上并不分配内存,只是在已经分配好的内存上创建相关的数据,销毁时只能用销毁缓冲区的内存,具体的对象数据需要显示的调用析构函数。
可以参考一个关于 new的问题?中关于 new的回答。
另外在c++中也可用但是不建议因为会出现浅拷贝的问题,同样的问题发生于等c相关的拷贝函数。
也可以分配内存,区别是分配完自动填0。
&emsp;&emsps;:在栈上申请内存。程序在出栈的时候,会自动释放内存。但是需要注意的是, 不具可移植性, 而且在没有传统堆栈的机器上很难实现。 不宜使用在必须广泛移植的程序中。C99 中支持变长数组 (VLA),可以用来替代 。
1.7 内存 1.7.1 内存泄露问题
内存泄漏一般是指堆内存的泄漏,即程序在运行过程中动态申请的内存空间不再使用后没有及时释放,导致那块内存不能被再次使用。更广义的内存泄漏还包括未对系统资源的及时释放,比如句柄、等没有使用相应的函数释放掉,导致系统资源的浪费。解决方法:
养成良好的编码习惯和规范,记得及时释放掉内存或系统资源;使用智能指针,、、;使用内存池。 1.7.2 内存泄露检测
参考C/C++内存泄漏及检测
1.7.3 智能指针
智能指针的作用是管理一个指针,因为存在以下这种情况:申请的空间在函数结束时忘记释放,造成内存泄漏。使用智能指针可以很大程度上的避免这个问题,因为智能指针就是一个类,当超出了类的作用域是,类会自动调用析构函数,析构函数会自动释放资源。所以智能指针的作用原理就是在函数结束时自动释放内存空间,不需要手动释放内存空间。
使用引用计数实现多个共享一个对象,当最后一个资源的引用被销毁时会被释放。可以使用new,,,构造,使用()销毁。
实现对象的独占,同一时间一个只能指向一个对象。可以通过move转移所有权。当两个对象相互使用一个成员变量指向对方会造成循环应用问题,导致引用计数失效。
是一种不控制对象生命周期的智能指针。被设计为与 共同工作,可以从一个 或者另一个 对象构造而来。是为了配合 而引入的一种智能指针,它更像是 的一个助手而不是智能指针,因为它不具有普通指针的行为,没有重载 * 和 ->,因此取名为 weak,表明其是功能较弱的智能指针。它的最大作用在于协助 工作,可获得资源的观测权,像旁观者那样观测资源的使用情况。观察者意味着 只对 进行引用,而不改变其引用计数,当被观察的 失效后,相应的 也相应失效。
智能指针陷阱:
不适用相同的内置指针初始化或者reset多个智能指针;不,get到的指针;不适用get初始化或者reset另一个智能指针;如果你使用智能指针管理的资源不是new分配的内存,记住传递给它一个删除器;如果你使用get( )返回的指针,记住当最后一个对应的智能指针销毁后,你的指针就变为无效了。 1.7.4 内存对齐 1.7.4.1 如何对齐
内存对齐的原则:
数据成员对齐规则:结构()或联合(union)的数据成员,第一个数据成员放在为0的位置,以后每个数据成员存储的起始位置都是放在该数据成员大小的整数倍位置。如在32bit的机器上,int的大小为4,因此int的存储位置都是从4的整数倍的位置开始存储的;结构体作为成员:如果一个结构里有某些结构体成员,则结构体成员要从其内部“最宽基本类型成员”的整数倍地址开始存储( a里面有 b,b里面有char、int、等元素,那b应该从8的整数倍位置开始存储);收尾工作:结果体的总大小,也就是的结果,必须是其内部最大成员的“最宽基本类型成员”的整数倍,不足时要补齐。(基本类型不包括、class、union);(union),以结构里面size最大元素为union的size,因为在某一个时刻,union只有一个成员真正存储于该地址;可以使用# pack(n)指定对齐的字节数。
class align1
{char a; //1short b; //2int c; //4long d; //8
};class align2
{char a;char b;
};class align4
{char a;char b;long c;
};
比如上面3个类的大小分别为16,2,16,拿举例,成员a和b的地址分别为&+1和&+2,而c的地址为&align+8,即b和c之间有6个字节的补齐。
另外可以使用冒号指定数据所占位数,下面类大小为8,总共是10位1个字节,但是要按照8来对齐:
class align3
{char a:1;short b:2;int c:3;long d:4;
};
1.7.4.2 为什么要对齐 1.8 C++内置类型的长度 类型长度(字节)
char
short int
int
int
long
8(机器相关,32位机为4)
long long
long
8(机器相关,32位机为4)
float
指针
8(机器相关,32位机为4)
测试输出
char 1
short int 2
int 4
unsigned int 4
long 8
long long 8
unsigned long 8
float 4
double 8
void * 8
1.9 类型推断 1.9.1 类型推断关键字
C++中的类型推断主要使用auto,,,三者在不同情况下的作用不同行为不同。对于auto:
auto必须在定义时进行初始化;auto定义序列变量必须能够推导为同一类型,如auto a=10,b=30.0, c='a';在b处出错;如果初始化的表达式是引用,则会去除引用语义;如果初始化表达式是const/,则去除相关语义;如果auto带上&,则不去除const语义;初始化表达式为数组时,auto关键字推导类型为指针,带上&则推导为数组;函数模板参数不能被声明为auto;auto并不是一个类型只是一个占位符,不能使用对类型进行操作的操作符处理。
类型推断相比于auto能够保留const等信息。
主要用于RTTI(Run-Time Type ,运行时类型识别),这部分我自己测试的结果和网上的博客有出入,以后再更新[TODO]
int val;int &val1 = val;const int val2 = val;const int &val3 = val;int *val4 = &val;father * f = new father();child *c = new child();father *ff = c;cout<<typeid(val).name()<<endl; //int icout<<typeid(val1).name()<<endl; //int icout<<typeid(val2).name()<<endl; //int icout<<typeid(val3).name()<<endl; //int icout<<typeid(val4).name()<<endl; //int* i cout<<typeid(tolower).name()<<endl;; //int (*)(int) Fiiecout<<typeid(f).name()<<endl; //father*cout<<typeid(c).name()<<endl; //child*cout<<typeid(ff).name()<<endl; //father*decltype(val) new_val = val; //intdecltype(val1) new_val1 = val; //int&decltype(val2) new_val2= val; //const intdecltype(val3) new_val3 = val; //const int &decltype(val4) new_val4 = &val; //int *decltype(f) f1 = f; //father*decltype(c) c1 = c; //child*decltype(ff) ff1 = c; //father*auto aut_val = val; //intauto aut_val1 = val; //intauto aut_val2 = val; //intauto aut_val3 = val; //intauto aut_val4 = &val; //int*auto f2 = f; //father*auto c2 = c; //child*auto ff2 = c; //child*
1.9.2 RTTI
RTTI(Run-Time Type ,运行时类型识别),C++是一种静态类型语言。其数据类型是在编译期就确定的,不能在运行时更改。然而由于面向对象程序设计中多态性的要求,C++中的指针或引用()本身的类型,可能与它实际代表(指向或引用)的类型并不一致。有时我们需要将一个多态指针转换为其实际指向对象的类型,就需要知道运行时的类型信息,这就产生了运行时类型识别的要求。
C++中的RTTI一般使用和进行多态时的类型推断:
详细参考C++中的RTTI(转)
1.10 ,,和
注意对能成功进行的含方法的类,通过引用转换和指针转换后对方法的调用不同:假设转换前为转换后为,则通过引用转化调方法实际是调用中对应方法的;通过指针转换调中指针相对存放位置对应相对位置的指针对应的方法(若该位置指向不是方法,运行失败),形参不一致会自动补全(一般是乱码)或删减。
,的可抛出异常版本。
1.11 C++宏定义 1.11.1 宏定义
C++宏定义实质上是一种类似于函数的功能,但是其本身并不是函数只是简单的替换,更不存在类型检查的措施:
###1.11.2 常用的宏定义
宏定义中单个#。将传入的参数字符串化。如# str(x) #x,令x=123则str(x)等同于123;宏定义中的两个#。连接前后两个参数# conv(x,y) x##y,传入conv(a,1)等同于变量a1;宏定义中的#@。给传入的变量加上单引号,# (x),传入a等同于````a` ```;头文件中添加以下宏定义防止重复包含:
#ifndef FILE_H
#define FILE_H
//TODO:coding
#endif //FILE_H
得到指定地址上一个字节或者字:
#define mem_byte(addr) ( *( (byte *) (x) ) )
#define mem_word(addr) ( *( (word *) (x) ) )
得到结构体中的偏移量:
#define offset( type, field ) sizeof( ((type *) 0)->field )
字母转换成大写或者小写:
#define to_upper( c ) ( ((c) >= 'a' && (c) <= 'z') ? ((c) - 0x20) : (c) )
#define to_lowwer( c ) ( ((c) >= 'A' && (c) <= 'Z') ? ((c) + 0x20) : (c) )
得到变量的地址:
#define byte_ptr( var ) ( (byte *) (void *) &(var) )
#define word_ptr( var ) ( (word *) (void *) &(var) )
判断字符是不是10进制数字:
#define dec_check( c ) ((c) >= ''0'' && (c) <= ''9'')
判断字符是不是16进制数字:
#define hex_check( c ) ( ((c) >= ''0'' && (c) <= ''9'') ||((c) >= ''A'' && (c) <= ''F'') ||((c) >= ''a'' && (c) <= ''f'') )
防止溢出:
#define inc_sat(val) (val = ((val) + 1 > (val))?(val) + 1 : (val))
返回数组元素的个数:
#deifne array_size(arr) (sizeof( (arr) ) / sizeof( (a[0]) ))
宏跟踪调试:
__LINE___ //代码出的行号%d
__FILE__ //执行代码的文件名%s
__DATE__ //日期%s
__TIME__ //时间%s
1.12 表达式
C++ 11 中的 表达式用于定义并创建匿名的函数对象,以简化编程工作。 的语法形式如下:
[函数对象参数] (操作符重载函数参数) mutable 或 exception 声明 -> 返回值类型 {函数体}
函数对象:
操作符重载函数参数:标识重载的 () 操作符的参数,没有参数时,这部分可以省略。参数可以通过按值(如: (a, b))和按引用 (如: (&a, &b)) 两种
方式进行传递。
或 声明:这部分可以省略。按值传递函数对象参数时,加上 修饰符后,可以修改传递进来的拷贝(注意是能修改拷贝,而不是值本身)。 声明用于指定函数抛出的异常,如抛出整数类型的异常,可以使用 throw(int)。
-> 返回值类型:标识函数返回值的类型,当返回值为 void,或者函数体中只有一处 的地方(此时编译器可以自动推断出返回值类型)
时,这部分可以省略。
函数体:标识函数的实现,这部分不能省略,但函数体可以为空。
[] (int x, int y) { return x + y; } // 隐式返回类型
[] (int& x) { ++x; } // 没有 return 语句 -> Lambda 函数的返回类型是 'void'
[] () { ++global_x; } // 没有参数,仅访问某个全局变量
[] { ++global_x; } // 与上一个相同,省略了 (操作符重载函数参数)
2 类相关 2.1 虚函数
虚函数:
纯虚函数:
class class1{
virtual func(); //虚函数
virtual func1() = 0; //纯虚函数
};
2.2 多态
多态分为两种:静态多态和动态多态。
静态多态即函数重载,编译期决定了执行内容。
动态多态使用虚函数实现,即执行期才决定执行内容。多态的目的是为了接口重用,封装可以使得代码模块化,继承可以扩展已存在的代码。
多态的使用方法是:声明两个类分别为父子类,父类中存在虚函数,子类对该虚函数进行了重写,在通过基类指针或者引用调用该方法是对于不同的实例会自动调用自身的该方法。所以多态的关键是:
父子类相同的虚函数;调用时只能使用指针或者引用。
class virtual_class
{
public:virtual void run(){cout<<"i am the fater"<<endl;}
};class virtual_class_child : public virtual_class
{
public:virtual void run() override{cout<<"i am the kid"<<endl;}
};void vitual_test_func(virtual_class & cls)
{cls.run();
}void virtual_test()
{virtual_class father;virtual_class_child child;vitual_test_func(father);vitual_test_func(child);
}
输出:
i am the fater
i am the kid
另外关键字可以显式的在派生类中声明,哪些成员函数需要被重写,如果没被重写,则编译器会报错,是一种辅助手段。一般用于子类中。
2.3 虚函数表
linux下可以使用如下指令获得class文件得到类的结构:
g++ -fdump-class-hierarchy filename
class virtual_class
{
public:virtual void run(){cout<<"i am the fater"<<endl;}virtual void func1(){}virtual void func2(){}virtual void func3(){}};class virtual_class_child : public virtual_class
{
public:virtual void run() override{cout<<"i am the kid"<<endl;}virtual void func1(){}virtual void func2(){}
};
上述两个类的虚函数表为:
Vtable for virtual_class
virtual_class::_ZTV13virtual_class: 6u entries
0 (int (*)(...))0
8 (int (*)(...))(& _ZTI13virtual_class)
16 (int (*)(...))virtual_class::run
24 (int (*)(...))virtual_class::func1
32 (int (*)(...))virtual_class::func2
40 (int (*)(...))virtual_class::func3
Vtable for virtual_class_child
virtual_class_child::_ZTV19virtual_class_child: 6u entries
0 (int (*)(...))0
8 (int (*)(...))(& _ZTI19virtual_class_child)
16 (int (*)(...))virtual_class_child::run
24 (int (*)(...))virtual_class_child::func1
32 (int (*)(...))virtual_class_child::func2
40 (int (*)(...))virtual_class::func3
C++中每个对象都会维护一个虚函数表指针,而虚函数表属于类本身。继承关系中的虚函数表的结构:子类先继承父类的虚函数表,如果子类重写了相关方法则子类的虚函数表上会替换为子类的方法,如果子类定义了新的虚函数该函数会被添加到虚函数表上面。
在多继承的情况下,单个类会维护多个虚函数表。
class mother
{virtual void func1();
};class father
{virtual void func1();virtual void func2();
};class child: public father, public mother
{virtual void func2();virtual void func3();
};
Vtable for father
father::_ZTV6father: 4u entries
0 (int (*)(...))0
8 (int (*)(...))(& _ZTI6father)
16 (int (*)(...))father::func1
24 (int (*)(...))father::func2
Vtable for mother
mother::_ZTV6mother: 3u entries
0 (int (*)(...))0
8 (int (*)(...))(& _ZTI6mother)
16 (int (*)(...))mother::func1
Vtable for child
child::_ZTV5child: 8u entries
0 (int (*)(...))0
8 (int (*)(...))(& _ZTI5child)
16 (int (*)(...))father::func1
24 (int (*)(...))child::func2
32 (int (*)(...))child::func3
40 (int (*)(...))-8
48 (int (*)(...))(& _ZTI5child)
56 (int (*)(...))mother::func1
2.4 深拷贝和浅拷贝
拷贝函数被调用的三种情形:
对象以传值作为函数的参数;对象以传值的方式作为返回值;用一个对象初始化另一个对象。
浅拷贝:类中并未显示声明拷贝构造函数,导致拷贝时只是简单的赋值拷贝,对于指针等指向的资源出现多个对象拥有同一份资源的情况;
深拷贝:自定义拷贝函数,明确不同资源的拷贝方式,避免一份资源多个类共享。
一般如果普通的赋值操作能够保证两个类的资源不共享就不需要深拷贝,否则一定要深拷贝。
2.5 类的构造顺序 2.5.1 默认情况下的空类的行为及其大小
空类编译器回味其默认添加构造函数,拷贝构造函数,赋值函数,析构函数,这些函数只有在第一次被调用时,才会被编译器创建。空类其大小为1,类中函数本身不占空间。
class empty{};
class empty1{
public:empty1(){}empty1(const empty1 &){}empty1 & operator=(const empty1 &){}~empty1(){}
};
需要注意的是下面类的大小为8因为要维护一个虚函数表指针。
class empty2{
public:empty2(){}empty2(const empty2 &){}empty2 & operator=(const empty2 &){}~empty2(){}void func2(){}virtual void func3(){}
};
2.5.2 继承中类的生成和销毁顺序
构造时,先构造基类再销毁派生类;销毁时,先销毁派生类再销毁基类。而对于多继承构造时按照继承的顺序构造,析构时按照继承的反顺序析构。
class base1
{
public:base1(){cout<<"base1 constructor"<<endl;}~base1(){cout<<"base1 deconstructor"<<endl;}
};class base2
{
public:base2(){cout<<"base2 constructor"<<endl;}~base2(){cout<<"base2 deconstructor"<<endl;}
};class base3
{
public:base3(){cout<<"base3 constructor"<<endl;}~base3(){cout<<"base3 deconstructor"<<endl;}
};class derived1:public base1, public base2, public base3
{
public:derived1(){cout<<"derived1 constructor"<<endl;}~derived1(){cout<<"derived1 deconstructor"<<endl;}
};
base1 constructor
base2 constructor
base3 constructor
derived1 constructor
derived1 deconstructor
base3 deconstructor
base2 deconstructor
base1 deconstructor
2.5.3 类中的数据成员初始化顺序 成员变量在使用初始化列表初始化时,与构造函数中初始化成员列表的顺序无关,只与定义成员变量的顺序有关;如果不使用初始化列表初始化,在构造函数内初始化时,此时与成员变量在构造函数中的位置有关;
3.类中const成员常量必须在构造函数初始化列表中初始化;类中成员变量,只能在类内外初始化(同一类的所有实例共享静态成员变量)。
派生类数据成员初始化顺序:
基类的静态变量或全局变量;派生类的静态变量或全局变量;基类的成员变量;派生类的成员变量。 2.6 this指针 this 指针是一个隐含于每一个非静态成员函数中的特殊指针。它指向调用该成员函数的那个对象。当对一个对象调用成员函数时,编译程序先将对象的地址赋给 this 指针,然后调用成员函数,每次成员函数存取数据成员时,都隐式使用 this 指针。当一个成员函数被调用时,自动向它传递一个隐含的参数,该参数是一个指向这个成员函数所在的对象的指针。this 指针被隐含地声明为: *const this,这意味着不能给 this 指针赋值;在 类的 const 成员函数中,this 指针的类型为:const * const,这说明不能对 this 指针所指向的这种对象是不可修改的(即不能对这种对象的数据成员进行赋值操作);this 并不是一个常规变量,而是个右值,所以不能取得 this 的地址(不能 &this);对this指针解引用得到是该类型变量的一个引用;在以下场景中,经常需要显式引用 this 指针: 为实现对象的链式引用;为避免对同一对象进行赋值操作;在实现一些数据结构时,如 list。
成员函数最终被编译成与对象无关的普通函数,除了成员变量,会丢失所有信息,所以在编译时要在成员函数中添加一个额外的参数,把当前对象的首地址传入,以此来关联成员函数和成员变量。
2.7 友元
友元可以使得指定的函数或者类可以访问目标类的私有数据或者成员函数。在使用友元时在目标类中声明相关函数或者类之前添加关键字即可,而声明的位置是还是并无无别。
2.7.1 分类 友元函数:定义为友元函数的普通函数;友元类:定义为友元类的类,即目标类对友元类完全透明可见,需要注意的是: 友元关系不可继承;友元关系是单向性;友元关系不具有传递性; 友元成员函数:和友元函数基本相同,唯一区别是该函数是另一个类的成员函数。 2.7.2 如何使用友元
即便实现类之间的数据共享,减少系统开销,提高效率,但是要注意的是友元破坏了封装性,等同于特权。封装本身是为了隐藏数据,友元向部分函数或类提供了特权,使得其可以访问私有数据和成员。一般情况下不到万不得已不要使用友元,大部分场景都可以使用其他方式解决。友元使用比较频繁的场景是操作符重载和数据共享。
class friend_class
{int val;
public:friend_class():val(10){}int operator+(int value){cout<<"friend class operator "<<value + val<<endl;return value + val;}
};void friend_test()
{friend_class cls;int val = cls + 2;//int val2 = 2 + cls; //错误
}
从上面的例子可以看出直接使用成员函数重载无法保证语义,使用下面的友元便可以保证完整的语义。
class friend_class
{int val;
public:friend_class():val(10){}friend int operator+(friend_class& cls, int val);
};int operator+(friend_class & cls, int val)
{return cls.val + val;
}int operator+(int val, friend_class &cls)
{return cls + val;
}
2.8 move和语义
详细见移动语义(move )和完美转发( )
2.8.1 左值()、右值()、左值引用( )和右值引用( )
凡是真正的存在内存当中,而不是寄存器当中的值就是左值,其余的都是右值。其实更通俗一点的说法就是:凡是取地址(&)操作可以成功的都是左值,其余都是右值。
对于左值的引用就是左值引用,而对于右值的引用就是右值引用。const引用可以绑定左值和右值。
左值引用就是一般使用的引用T&,右值引用为T&&。
2.8.2 move语义
move语义能够将左值转换成右值。一般情况下构建类为了保证安全性会为类定义深拷贝构造函数,但是如果我们仅仅是根据现有数据构造类的话,依旧保持使用深拷贝构造函数的话性能就会大大折扣,因此move语义提供了一种声明浅拷贝构造函数的方式,即移动拷贝构造函数,来提升性能。
class move_class
{int *data;int size;
public:move_class(int sz){size = sz;data = new int[size];memset(data, 0, sizeof(int) * size);}move_class(move_class& cls){size = cls.size;data = new int[size];memcpy(data, cls.data, size * sizeof(int));}move_class(move_class&& cls){size = cls.size;data = cls.data;cls.data = nullptr;}
}void move_test()
{move_class cls1;move_class cls2(std::move(cls1)); //cls1在之后不在被使用move_class cls3(move_class(400)); //一般不会这么做,演示而已
}
需要注意的是使用std::move处理过的对象不能再使用了。另外一些编译器默认提供NROV优化的无法使用move语义,因此需要添加编译器参数。RVO和NROV优化
2.8.3 语义
()则会保留参数的左右值类型,保证在跨函数传参时能够保证参数本身的左右值类型。
void func1(int val){}
void func2(int && val){func1(std::forward<int>(val));
}
2.8.4 通用引用( )
构成通用引用有两个条件:
必须满足T&&这种形式;类型T必须是通过推断得到的。
一般构成通用引用的情况有:函数模板;auto声明;;。
通用引用会导致引用类型合成,基本能够保证传入左值引用便是左值引用,传入右值引用便是右值引用(这个合成规则用户是不允许使用的,只有编译器才能够使用这种合成规则。这就是为什么上面的通用引用当中有一条要求是类型必须可以自动推导):T& & -> T&;T&& & -> T&;T& && -> T&;T&& && -> T&&。 3 3.1 C++ 视 C++ 为一个语言联邦(C、- C++、 C++、STL)宁可以编译器替换预处理器(尽量以 const、enum、 替换 #)尽可能使用 const确定对象被使用前已先被初始化(构造时赋值(copy 构造函数)比 构造后赋值(copy )效率高)了解 C++ 默默编写并调用哪些函数(编译器暗自为 class 创建 构造函数、copy 构造函数、copy 操作符、析构函数)若不想使用编译器自动生成的函数,就应该明确拒绝(将不想使用的成员函数声明为 ,并且不予实现)为多态基类声明 析构函数(如果 class 带有任何 函数,它就应该拥有一个 析构函数)别让异常逃离析构函数(析构函数应该吞下不传播异常,或者结束程序,而不是吐出异常;如果要处理异常应该在非析构的普通函数处理)绝不在构造和析构过程中调用 函数(因为这类调用从不下降至 class)令 = 返回一个 to *this (用于连锁赋值)在 = 中处理 “自我赋值”赋值对象时应确保复制 “对象内的所有成员变量” 及 “所有 base class 成分”(调用基类复制构造函数)以对象管理资源(资源在构造函数获得,在析构函数释放,建议使用智能指针,资源取得时机便是初始化时机( Is ,RAII))在资源管理类中小心 行为(普遍的 RAII class 行为是:抑制 、引用计数、深度拷贝、转移底部资源拥有权(类似 ))在资源管理类中提供对原始资源(raw )的访问(对原始资源的访问可能经过显式转换或隐式转换,一般而言显示转换比较安全,隐式转换对客户比较方便)成对使用 new 和 时要采取相同形式(new 中使用 [] 则 [],new 中不使用 [] 则 )以独立语句将 newed 对象存储于(置入)智能指针(如果不这样做,可能会因为编译器优化,导致难以察觉的资源泄漏)让接口容易被正确使用,不易被误用(促进正常使用的办法:接口的一致性、内置类型的行为兼容;阻止误用的办法:建立新类型,限制类型上的操作,约束对象值、消除客户的资源管理责任)设计 class 犹如设计 type,需要考虑对象创建、销毁、初始化、赋值、值传递、合法值、继承关系、转换、一般化等等。
宁以 pass-by--to-const 替换 pass-by-value (前者通常更高效、避免切割问题( ),但不适用于内置类型、STL迭代器、函数对象)必须返回对象时,别妄想返回其 (绝不返回 或 指向一个 local stack 对象,或返回 指向一个 heap- 对象,或返回 或 指向一个 local 对象而有可能同时需要多个这样的对象。)将成员变量声明为 (为了封装、一致性、对其读写精确控制等)宁以 non-、non- 替换 函数(可增加封装性、包裹弹性( )、机能扩充性)若所有参数(包括被this指针所指的那个隐喻参数)皆须要类型转换,请为此采用 non- 函数考虑写一个不抛异常的 swap 函数尽可能延后变量定义式的出现时间(可增加程序清晰度并改善程序效率)尽量少做转型动作(旧式:(T)、T();新式:()、()、()、()、;尽量避免转型、注重效率避免 、尽量设计成无需转型、可把转型封装成函数、宁可用新式转型)避免使用 (包括 引用、指针、迭代器)指向对象内部(以增加封装性、使 const 成员函数的行为更像 const、降低 “虚吊号码牌”( ,如悬空指针等)的可能性)为 “异常安全” 而努力是值得的(异常安全函数(-safe )即使发生异常也不会泄露资源或允许任何数据结构败坏,分为三种可能的保证:基本型、强列型、不抛异常型)透彻了解 的里里外外( 在大多数 C++ 程序中是编译期的行为; 函数是否真正 ,取决于编译器;大部分编译器拒绝太过复杂(如带有循环或递归)的函数 ,而所有对 函数的调用(除非是最平淡无奇的)也都会使 落空; 造成的代码膨胀可能带来效率损失; 函数无法随着程序库的升级而升级)将文件间的编译依存关系降至最低(如果使用 或 可以完成任务,就不要使用 ;如果能够,尽量以 class 声明式替换 class 定义式;为声明式和定义式提供不同的头文件)确定你的 继承塑模出 is-a(是一种)关系(适用于 base 身上的每一件事情一定适用于 身上,因为每一个 class 对象也都是一个 base class 对象)避免遮掩继承而来的名字(可使用 using 声明式或转交函数( )来让被遮掩的名字再见天日)区分接口继承和实现继承(在 继承之下, 总是继承 base class 的接口;pure 函数只具体指定接口继承;非纯 函数具体指定接口继承及缺省实现继承;non- 函数具体指定接口继承以及强制性实现继承)考虑 函数以外的其他选择(如 设计模式的 non- (NVI)手法,将 函数替换为 “函数指针成员变量”,以 tr1:: 成员变量替换 函数,将继承体系内的 函数替换为另一个继承体系内的 函数)绝不重新定义继承而来的 non- 函数绝不重新定义继承而来的缺省参数值,因为缺省参数值是静态绑定( bound),而 函数却是动态绑定( bound)通过复合塑模 has-a(有一个)或 “根据某物实现出”(在应用域( ),复合意味 has-a(有一个);在实现域( ),复合意味着 is--in-terms-of(根据某物实现出))明智而审慎地使用 继承( 继承意味着 is--in-terms-of(根据某物实现出),尽可能使用复合,当 class 需要访问 base class 的成员,或需要重新定义继承而来的时候 函数,或需要 empty base 最优化时,才使用 继承)明智而审慎地使用多重继承(多继承比单一继承复杂,可能导致新的歧义性,以及对 继承的需要,但确有正当用途,如 “ 继承某个 class” 和 “ 继承某个协助实现的 class”; 继承可解决多继承下菱形继承的二义性问题,但会增加大小、速度、初始化及赋值的复杂度等等成本)了解隐式接口和编译期多态(class 和 都支持接口()和多态();class 的接口是以签名为中心的显式的(),多态则是通过 函数发生于运行期; 的接口是奠基于有效表达式的隐式的(),多态则是通过 具现化和函数重载解析( )发生于编译期)了解 的双重意义(声明 类型参数是,前缀关键字 class 和 的意义完全相同;请使用关键字 标识嵌套从属类型名称,但不得在基类列(base class lists)或成员初值列( list)内以它作为 base class 修饰符)学习处理模板化基类内的名称(可在 class 内通过 this-> 指涉 base class 内的成员名称,或藉由一个明白写出的 “base class 资格修饰符” 完成)将与参数无关的代码抽离 (因类型模板参数(non-type )而造成代码膨胀往往可以通过函数参数或 class 成员变量替换 参数来消除;因类型参数(type )而造成的代码膨胀往往可以通过让带有完全相同二进制表述( )的实现类型( types)共享实现码)运用成员函数模板接受所有兼容类型(请使用成员函数模板( )生成 “可接受所有兼容类型” 的函数;声明 用于 “泛化 copy 构造” 或 “泛化 操作” 时还需要声明正常的 copy 构造函数和 copy 操作符)需要类型转换时请为模板定义非成员函数(当我们编写一个 class ,而它所提供之 “与此 相关的” 函数支持 “所有参数之隐式类型转换” 时,请将那些函数定义为 “class 内部的 函数”)请使用 表现类型信息( 通过 和 “ 特化” 使得 “类型相关信息” 在编译期可用,通过重载技术()实现在编译期对类型执行 if…else 测试)认识 元编程(模板元编程(TMP, )可将工作由运行期移往编译期,因此得以实现早期错误侦测和更高的执行效率;TMP 可被用来生成 “给予政策选择组合”(based on of )的客户定制代码,也可用来避免生成对某些特殊类型并不适合的代码)了解 new- 的行为( 允许客户指定一个在内存分配无法获得满足时被调用的函数; new 是一个颇具局限的工具,因为它只适用于内存分配( new),后继的构造函数调用还是可能抛出异常)了解 new 和 的合理替换时机(为了检测运用错误、收集动态分配内存之使用统计信息、增加分配和归还速度、降低缺省内存管理器带来的空间额外开销、弥补缺省分配器中的非最佳齐位、将相关对象成簇集中、获得非传统的行为)编写 new 和 时需固守常规( new 应该内涵一个无穷循环,并在其中尝试分配内存,如果它无法满足内存需求,就应该调用 new-,它也应该有能力处理 0 bytes 申请,class 专属版本则还应该处理 “比正确大小更大的(错误)申请”; 应该在收到 null 指针时不做任何事,class 专属版本则还应该处理 “比正确大小更大的(错误)申请”)写了 new 也要写 (当你写一个 new,请确定也写出了对应的 ,否则可能会发生隐微而时断时续的内存泄漏;当你声明 new 和 ,请确定不要无意识(非故意)地遮掩了它们地正常版本)不要轻忽编译器的警告让自己熟悉包括 TR1 在内的标准程序库(TR1,C++ 1,C++11 标准的草稿文件)让自己熟悉 Boost(准标准库) 3.2 More c++ 仔细区别 和 (当你知道你需要指向某个东西,而且绝不会改变指向其他东西,或是当你实现一个操作符而其语法需求无法由 达成,你就应该选择 ;任何其他时候,请采用 )最好使用 C++ 转型操作符(、、、)绝不要以多态()方式处理数组(多态()和指针算术不能混用;数组对象几乎总是会涉及指针的算术运算,所以数组和多态不要混用)非必要不提供 (避免对象中的字段被无意义地初始化)对定制的 “类型转换函数” 保持警觉(单自变量 可通过简易法( 关键字)或代理类(proxy )来避免编译器误用;隐式类型转换操作符可改为显式的 来避免非预期行为)区别 / 操作符的前置()和后置()形式(前置式累加后取出,返回一个 ;后置式取出后累加,返回一个 const 对象;处理用户定制类型时,应该尽可能使用前置式 ;后置式的实现应以其前置式兄弟为基础)千万不要重载 &&,|| 和 , 操作符(&& 与 || 的重载会用 “函数调用语义” 取代 “骤死式语义”;, 的重载导致不能保证左侧表达式一定比右侧表达式更早被评估)了解各种不同意义的 new 和 (new 、 new、 new、 new[]; 、 、、 [])利用 避免泄漏资源(在 释放资源可以避免异常时的资源泄漏)在 内阻止资源泄漏(由于 C++ 只会析构已构造完成的对象,因此在构造函数可以使用 try…catch 或者 (以及与之相似的 ) 处理异常时资源泄露问题)禁止异常流出 之外(原因:一、避免 函数在 传播过程的栈展开(stack-)机制种被调用;二、协助确保 完成其应该完成的所有事情)了解 “抛出一个 ” 与 “传递一个参数” 或 “调用一个虚函数” 之间的差异(第一, 总是会被复制(by 除外),如果以 by value 方式捕捉甚至被复制两次,而传递给函数参数的对象则不一定得复制;第二,“被抛出成为 ” 的对象,其被允许的类型转换动作比 “被传递到函数去” 的对象少;第三,catch 子句以其 “出现于源代码的顺序” 被编译器检验对比,其中第一个匹配成功者便执行,而调用一个虚函数,被选中执行的是那个 “与对象类型最佳吻合” 的函数)以 by 方式捕获 (可避免对象删除问题、 的切割问题,可保留捕捉标准 的能力,可约束 需要复制的次数)明智运用 ( 对 “函数希望抛出什么样的 ” 提供了卓越的说明;也有一些缺点,包括编译器只对它们做局部性检验而很容易不经意地违反,与可能会妨碍更上层的 处理函数处理未预期的 )了解异常处理的成本(粗略估计,如果使用 try 语句块,代码大约整体膨胀 5%-10%,执行速度亦大约下降这个数;因此请将你对 try 语句块和 的使用限制于非用不可的地点,并且在真正异常的情况下才抛出 )谨记 80-20 法则(软件的整体性能几乎总是由其构成要素(代码)的一小部分决定的,可使用程序分析器( )识别出消耗资源的代码)考虑使用 lazy (缓式评估)(可应用于: (引用计数)来避免非必要的对象复制、区分 [] 的读和写动作来做不同的事情、Lazy (缓式取出)来避免非必要的数据库读取动作、Lazy (表达式缓评估)来避免非必要的数值计算动作)分期摊还预期的计算成本(当你必须支持某些运算而其结构几乎总是被需要,或其结果常常被多次需要的时候,over-eager (超急评估)可以改善程序效率) 4 STL相关 4.1 STL容器 容器底层数据结构时间复杂度有无序可不可重复其他
array
数组
随机读改 O(1)
无序
可重复
支持随机访问
数组
随机读改、尾部插入、尾部删除 O(1)
头部插入、头部删除 O(n)
无序
可重复
支持随机访问
deque
双端队列
头尾插入、头尾删除 O(1)
无序
可重复
一个中央控制器 + 多个缓冲区,支持首尾快速增删,支持随机访问
单向链表
插入、删除 O(1)
无序
可重复
不支持随机访问
list
双向链表
插入、删除 O(1)
无序
可重复
不支持随机访问
stack
deque / list
顶部插入、顶部删除 O(1)
无序
可重复
deque 或 list 封闭头端开口,不用 的原因应该是容量大小有限制,扩容耗时
queue
deque / list
尾部插入、头部删除 O(1)
无序
可重复
deque 或 list 封闭头端开口,不用 的原因应该是容量大小有限制,扩容耗时
+ max-heap
插入、删除 O(log2n)
有序
可重复
容器+heap处理规则
set
红黑树
插入、删除、查找 O(log2n)
有序
不可重复
红黑树
插入、删除、查找 O(log2n)
有序
可重复
map
红黑树
插入、删除、查找 O(log2n)
有序
不可重复
红黑树
插入、删除、查找 O(log2n)
有序
可重复
哈希表
插入、删除、查找 O(1) 最差 O(n)
无序
不可重复
哈希表
插入、删除、查找 O(1) 最差 O(n)
无序
可重复
哈希表
插入、删除、查找 O(1) 最差 O(n)
无序
不可重复
哈希表
插入、删除、查找 O(1) 最差 O(n)
无序
可重复
4.2
本身是动态数组,如果未指定本身会分配大于当前需求的内存防止频繁分配内存造成的额外开销,这也体现为什么有成员函数size()和()。另外在不同编译器下增长方式不同,gcc下每次增长为原来的2倍,vs的编译器cl下每次增长为原来的1.5倍。
4.3 array
array允许随机访问,其迭代器属于随机迭代器,其size()的结果总等于N,不支持分配器,是唯一一个无任何东西被指定为初值时,会被预初始化的容器,这意味着对于基础类型初值可能不明确。class array是一个聚合体(不带用户提供的构造函数,没有和的数据成员,没有base类,有没有 函数),这意味着保存所有元素的那个成员是,然而C++并没有指定其名称,因此对该成员的任何直接访问都会导致不可预期的行为,也绝对不可移植。
4.4 deque
deque容器类与类似,支持随机访问和快速插入删除,它在容器中某一位置上的操作所花费的是线性时间。与不同的是,deque还支持从开始端插入数据:()。
4.5
是一种能在常数时间内在任何位置插入和删除的顺序容器。是单向链表。
4.6 list
list是由双向链表实现的,因此内存空间是不连续的。只能通过指针访问数据,所以list的随机存取非常没有效率,时间复杂度为o(n);但由于链表的特点,能高效地进行插入和删除。
4.7 stack
4.8 queue
4.9
4.10 set
4.11
4.12 map
4.13
4.14
4.15
4.16
4.17
4.18 STL算法
4 其他琐碎问题 说几个C++11的新特性?auto,for,,, final, ,智能指针等;c和c++区别?c是结构化语言面向过程编程,C程序的设计首要考虑的是如何通过一个过程,对输入(或环境条件)进行运算处理得到输出(或实现过程(事务)控制);c++面向对象编程,首要考虑的是如何构造一个对象模型,让这个模型能够契合与之对应的问题域,这样就可以通过获取对象的状态信息得到输出或实现过程(事务)控制;和const区别?是纯粹的替换,const本身依然是一个变量;野指针和悬空指针的区别?野指针是为初始化的指针;悬空指针是指向指向的内存收回后未进行置空处理;和class区别?基本相同,唯一不同的是默认的访问控制:默认,class是;和的区别?计算字节大小,计算目标元素的个数(以’\0’为结尾),同时能够计算处数组所占字节大小;关键字用处? 关键字是一种类型修饰符,用它声明的类型变量表示可以被某些编译器未知的因素更改,编译器对访问该变量的代码就不再进行优化,从而可以提供对特殊地址的稳定访问;和区别?本身也是替换,相比宏定义多了类型检查;虚函数可以内联吗?虚函数可以是内联函数,但是当虚函数表现出多态性时,则不能是内联函数;大小端的概念和各自的优势?大端:低地址存储高位字节;小端:低地址存储低位字节。
大端优势容易判断正负;小端优势容易数据类型转换;什么情况下,类的析构函数应该声明为虚函数?为什么?基类指针可以指向派生类的对象(多态性),如果删除该指针 []p;就会调用该指针指向的派生类析构函数,而派生类的析构函数又自动调用基类的析构函数,这样整个派生类的对象完全被释放。如果析构函数不被声明成虚函数,则编译器实施静态绑定,在删除基类指针时,只会调用基类的析构函数而不调用派生类析构函数,这样就会造成派生类对象析构不完全。不能声明为虚函数的函数?普通函数,友元函数,构造函数,内联成员函数和静态成员函数;解释下?是宏定义,是调试断言,的作用是现计算表达式 ,如果其值为假(即为0),那么它先向打印一条出错信息,然后通过调用 abort 来终止程序运行。调试结束后可以使用# 失效该语句;内存对齐?可以使用# pack(n)指定内存以n字节对齐,具体见内存对齐;C++中如何编译C代码?使用 "C"包裹C代码即可;C和C++中有何不同?C语言中的作为一种结构化数据存在,一般使用进行重命名,而C++中的只是和class默认访问控制不同而已;另外;C和C++中union的区别?在C中作为一种特殊的数据存在,而C++中基本的行为很像class但是: 不能拥有引用类型的成员;不能继承自其他类,不能作为基类;不能含有虚函数;匿名union不能包含和成员;全局匿名union必须是的。
面向对象的三大特征?继承,多态,封装;如何理解面向对象?面向对象相对的是面向过程,面向过程是操纵数据如何做,面向对象是对象能够干什么,让对象去干活。面向对象是把数据及对数据的操作方法放在一起(封装),作为一个相互依存的整体——对象。对同类对象抽象出其共性,形成类(继承)。类中的大多数数据,只能用本类的方法进行处理(多态)。类通过一个简单的外部接口与外界发生关系,对象与对象之间通过消息进行通信。程序流程由用户在使用中决定;如何使用C模仿C++?继承使用结构体嵌套模仿;封装使用函数指针将函数封装到结构体中;多态父子类使用不同的函数指针;只能尽可能的相似不可能相同;的作用?防止隐式类型转换,避免初始化时复制;如何使用using?尽可能的使用using声明,而不是using指示,后者容易导致名字污染;另外在子类中使用using base::base;派生类会直接替子类构造调用基类的构造函数,即(args):base(args){};C++中的范围解析?::全局;::类中,::命名空间中;解释下C++中的枚举类型?枚举值表也叫枚举元素列表,列出定义的枚举类型的所有可用值,各个值之间用“,”分开,需要注意的是枚举类型是右值,并且可以隐式转换成int类型,但是int类型无法隐式转换成枚举类型;描述下?一般使用于构造函数中可以使用列表初始化类,中只能是无法改变的常量,某种程度上等同于常数数组;虚析构函数的作用?虚析构函数是为了解决派生类的安全析构问题,使用虚析构函数便利用多态特性保证类的安全销毁;纯虚函数的作用?抽象,接口;虚继承的作用?解决菱形继承问题,即当前类所继承的多个类拥有公共祖先,防止类中出现多个基类的拷贝; this是否合法?对象是通过new获得,且在 this之后该对象完全不再使用的情况下合法;如何定义只能在堆上生成的对象?将析构函数私有化或者将构造函数和析构函数都私有化,提供创建和销毁接口;如何定义只能在栈上生成的对象?重载new和;构造函数和的含义?表示禁用该版本构造函数,表示自动生成该版本默认构造函数;final语义?final修饰类表示不希望被继承,修饰虚函数表示不希望被;const和的区别?const某种程度上只是保证运行时不变性,而保证了编译期的不可变;C++程序的编译过程?C++代码经过预处理器转换成.i文件(g++ -E),.i文件经过编译器转换成汇编代码s(g++ -S),’.s’汇编代码经过汇编器编译成.o文件(g++ -c),链接器将’.o’文件链接成可执行文件(g++ -o),不同平台可执行文件不同,为PE格式文件,linux下位ELF格式文件;如何重载前置++和后置++?前置++(),后置++(0); 对于new[]出来的数组指针,使用而不是[]会有什么后果?所有内存能够完整的释放掉,但是只会调用第一个对象的析构函数不会调用所有的对象的析构函数,另外对于下的g++,cl编译器行为相同不会报错也不会警告,linux下的g++相同,但是对于clang会指出问题的建议,但是依然会编译成功.。 5 常见实现 5.1 实现自己的
main.hpp
#include main.cpp
#include "my_string.hpp"
#include "ios_lib.h"my_string::my_string()
{data = new char[1];*data = '\0';len = 0;
}my_string::~my_string()
{if(nullptr != data){delete data;data = nullptr;len = 0;}
}bool my_string::copy_and_new(const char *src, char **dst, const int len)
{if(nullptr == src || len == 0)return false;if(nullptr != *dst){delete *dst;*dst = nullptr;}*dst = new char[len + 1];strncpy(*dst, src, len);(*dst)[len] = '\0';return true;
}my_string::my_string(const char *ptr)
{data = nullptr;assert(nullptr != ptr);int length = strnlen(ptr, 65535);bool ret = copy_and_new(ptr, &(this->data), length);len = length;
}my_string::my_string(const my_string &str)
{data = nullptr;bool ret = copy_and_new(str.data, &(this->data), str.len);this->len = str.len;
}my_string::my_string(const my_string &&str)
{this->data = str.data;len = str.len;
}my_string& my_string::operator=(const my_string &str)
{if(*this == str)return *this;else{//异常安全,如果内存申请失败,类的构造也会随之失败my_string tmp(str);char *tmp_data = this->data;this->data = tmp.data;tmp.data = tmp_data;this->len = str.len;}return *this;
}my_string& my_string::operator+=(const my_string &str)
{int total = str.len + this->len;char *new_ptr = new char[total + 1];int j = 0;for(int i = 0;i < this->len;)new_ptr[j++] = data[i++];for(int i = 0;i < str.len;)new_ptr[j++] = str.data[i++];delete this->data;data = new_ptr;data[total] = '\0';this->len = total;return *this;
}bool my_string::operator==(const my_string &str)
{if(str.len != len)return false;for(int i = 0;i < len;i++){if(str[i] != (*this)[i])return false;}return true;
}char my_string::operator[](unsigned int id)
{assert(len >= 0 && len < len);return *(data + id);
}const char my_string::operator[](unsigned int id) const
{return *(data + id);
}my_string operator+(const my_string&rst, const my_string &snd)
{my_string tmp(rst);tmp += snd;return tmp;
}ostream& operator<<(ostream&os, const my_string &str)
{for(int i = 0;i < str.size();i ++){os<<str[i];}return os;
}istream& operator>>(istream& is, const my_string&)
{char buffer[4096] = {'0'};char ch;int i = 0;my_string ret;while(is>>ch){buffer[i++] = ch;if(i == 4096 - 1){ret += my_string(buffer);memset(buffer, 0, 4096);}}return is;
}void string_test()
{char *ptr = nullptr;//基本构造函数测试my_string str;my_string str1("123");// my_string str2(ptr);my_string str4(str1);my_string str5 = my_string("456");cout<<STR_VARIABLE(str)<<str<<endl;cout<<STR_VARIABLE(str1)<<str1<<endl;//cout<// cout<cout<<STR_VARIABLE(str4)<<str4<<endl;cout<<STR_VARIABLE(str5)<<str5<<endl;cout<<STR_VARIABLE(str1 + str5)<< (str1 + str5)<<endl;
}
参考