Scrapy 下载器中间件、spider中间件
官方文档 (下载器中间件 )
扩展中间件: 针对特定响应状态码,使用代理重新请求:
中间件状态码不等于200重新请求
1、下载器 中间件 ( )
下载器中间件是介于 的 / 处理的钩子框架。 是用于全局修改 和 的一个轻量、底层的系统。
即 下载中间件。它是处于的 和 之间的处理模块。在 把从 获取的 发送给 的过程中,以及 把 发送回 的过程中, 和 都会经过 的处理。
也就是 在整个架构中起作用的位置是以下两个
在整个爬虫执行过程中能起到非常重要的作用,功能十分强大。可以修改User-Agent、处理重定向、设置代理、失败重试、设置 等。
的用法非常简单,只要实现 、、 中的任意一个方法即可,同时不同方法的返回值不同,其产生的效果也不同。
关于 调用 顺序
如果想将自定义的 添加到项目中,不要直接修改 变量。 提供了另外一个设置变量 ES,直接修改这个变量就可以添加自己定义的 ,以及禁用 里面定义的 了。
1. 如果完全没有中间件,爬虫的流程如下图所示。
2. 使用了中间件以后,爬虫的流程如下图所示。
激活下载器中间件
要激活下载器中间件组件,将其加入到 ES 设置中。 该设置是一个字典(dict),键为中间件类的路径,值为其中间件的顺序(order)。
这里是一个例子:
DOWNLOADER_MIDDLEWARES = {'myproject.middlewares.CustomDownloaderMiddleware': 543,
}
ES 设置会与 定义的 设置合并(但不是覆盖), 而后根据顺序(order)进行排序,最后得到启用中间件的有序列表: 第一个中间件是最靠近引擎的,最后一个中间件是最靠近下载器的。
关于如何分配中间件的顺序请查看 设置,而后根据您想要放置中间件的位置选择一个值。 由于每个中间件执行不同的动作,您的中间件可能会依赖于之前(或者之后)执行的中间件,因此顺序是很重要的。
如果您想禁止内置的(在 中设置并默认启用的)中间件, 您必须在项目的 ES 设置中定义该中间件,并将其值赋为 None 。 例如,如果您想要关闭user-agent中间件:
DOWNLOADER_MIDDLEWARES = {'myproject.middlewares.CustomDownloaderMiddleware': 543,'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
}
最后,请注意,有些中间件需要通过特定的设置来启用。更多内容请查看相关中间件文档。
编写您自己的下载器中间件
编写下载器中间件十分简单。每个中间件组件是一个定义了以下一个或多个方法的类:
class .s.
(, ):
当每个 通过下载中间件时,该方法被调用。
参数:
返回值:() 必须返回其中之一:
解释:
(, , ):
参数:
返回值:() 必须返回以下之一:
解释:
(, , ):
当下载处理器 ( ) 或 () ( 下载中间件 ) 抛出异常 ( 包括 异常) 时, 调用 () 。
参数:
返回值:() 应该返回以下之一:
解释:
(cls, ):
If , this is to a from a . It must a new of the . to all core like and ; it is a way for to them and hook its into .
:
( ) – that uses this
中的 :(1)中的 - 简书
解释:
示例:代理中间件
在爬虫开发中,更换代理IP是非常常见的情况,有时候每一次访问都需要随机选择一个代理IP来进行。
中间件本身是一个的类,只要爬虫每次访问网站之前都先“经过”这个类,它就能给请求换新的代理IP,这样就能实现动态改变代理。
在创建一个工程以后,工程文件夹下会有一个 .py 文件,打开以后其内容如下图所示。
自动生成的这个文件名称为 .py,名字后面的 s 表示复数,说明这个文件里面可以放很多个中间件。可以看到有一个 (爬虫中间件)中间件 和 (下载中间件)中间件
在.py中添加下面一段代码(可以在 下载中间件这个类 里面写,也可以把 爬虫中间件 和 下载中间件 这两个类删了,自己写个 下载中间件的类。推荐 自己单写一个类 作为 下载中间件):
# -*- coding: utf-8 -*-# Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/spider-middleware.htmlimport random
from scrapy.conf import settings
from scrapy.utils.project import get_project_settingsclass ProxyMiddleware(object):def process_request(self, request, spider):proxy_1 = random.choice(settings['PROXIES']) # 方法 1proxy_2 = random.choice(get_project_settings()['PROXIES']) # 方法 2request.meta['proxy'] = proxy_1打开 .py 添加 代理 ,并激活 这个代理中间件:
需要注意的是,代理IP是有类型的,需要先看清楚是 HTTP型 的代理IP还是 HTTPS型 的代理IP。
DOWNLOADER_MIDDLEWARES = {'test_spider.middlewares.ProxyMiddleware': 543,# 'test_spider.middlewares.Custom_B_DownloaderMiddleware': 643,# 'test_spider.middlewares.Custom_B_DownloaderMiddleware': None,
}PROXIES = ['https://114.217.243.25:8118','https://125.37.175.233:8118','http://1.85.116.218:8118'
]ES 其实就是一个字典,字典的Key就是用点分隔的中间件路径,后面的数字表示这种中间件的顺序。由于中间件是按顺序运行的,因此如果遇到后一个中间件依赖前一个中间件的情况,中间件的顺序就至关重要。
如何确定后面的数字应该怎么写呢?最简单的办法就是从543开始,逐渐加一,这样一般不会出现什么大问题。如果想把中间件做得更专业一点,那就需要知道自带中间件的顺序,如图下图所示 (ES )。
数字越小的中间件越先执行(数字越小,越靠近引擎,数字越大越靠近下载器,所以数字越小的,()优先处理;数字越大的,()优先处理;若需要关闭某个中间件直接设为None即可),例如自带的第1个中间件,它的作用是首先查看.py中 这一项的配置是True还是False。如果是True,表示要遵守.txt协议,它就会检查将要访问的网址能不能被运行访问,如果不被允许访问,那么直接就取消这一次请求,接下来的和这次请求有关的各种操作全部都不需要继续了。
开发者自定义的中间件,会被按顺序插入到自带的中间件中。爬虫会按照从100~900的顺序依次运行所有的中间件。直到所有中间件全部运行完成,或者遇到某一个中间件而取消了这次请求。
其实自带了 UA 中间件()、代理中间件()和重试中间件()。所以,从“原则上”说,要自己开发这3个中间件,需要先禁用里面自带的这3个中间件。要禁用的中间件,需要在.py里面将这个中间件的顺序设为None:
DOWNLOADER_MIDDLEWARES = {'test_spider.middlewares.ProxyMiddleware': 543,'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None,'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware': None
}PROXIES = ['https://114.217.243.25:8118','https://125.37.175.233:8118','http://1.85.116.218:8118'
]为什么说“原则上”应该禁用呢?先查看自带的代理中间件的源代码,如下图所示:
从上图可以看出,如果发现这个请求已经被设置了代理,那么这个中间件就会什么也不做,直接返回。因此虽然自带的这个代理中间件顺序为750,比开发者自定义的代理中间件的顺序543大,但是它并不会覆盖开发者自己定义的代理信息,所以即使不禁用系统自带的这个代理中间件也没有关系。
代理中间件的可用代理列表不一定非要写在.py里面,也可以将它们写到数据库或者Redis中。一个可行的自动更换代理的爬虫系统,应该有如下的3个功能。
中对接
from scrapy.http import HtmlResponse
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from gp.configs import *class ChromeDownloaderMiddleware(object):def __init__(self):options = webdriver.ChromeOptions()options.add_argument('--headless') # 设置无界面if CHROME_PATH:options.binary_location = CHROME_PATHif CHROME_DRIVER_PATH:self.driver = webdriver.Chrome(chrome_options=options, executable_path=CHROME_DRIVER_PATH) # 初始化Chrome驱动else:self.driver = webdriver.Chrome(chrome_options=options) # 初始化Chrome驱动def __del__(self):self.driver.close()def process_request(self, request, spider):try:print('Chrome driver begin...')self.driver.get(request.url) # 获取网页链接内容return HtmlResponse(url=request.url, body=self.driver.page_source, request=request, encoding='utf-8',status=200) # 返回HTML数据except TimeoutException:return HtmlResponse(url=request.url, request=request, encoding='utf-8', status=500)finally:print('Chrome driver end...')示例:UA (user-agent) 中间件
学习篇(十一)之设置随机User-Agent:
开发UA中间件和开发代理中间件几乎一样,它也是从 .py 配置好的 UA 列表中随机选择一项,加入到请求头中。代码如下:
class UAMiddleware(object):def process_request(self, request, spider):ua = random.choice(settings['USER_AGENT_LIST'])request.headers['User-Agent'] = ua比IP更好的是,UA不会存在失效的问题,所以只要收集几十个UA,就可以一直使用。常见的UA如下:
USER_AGENT_LIST = ["Mozilla/5.0 (Linux; U; Android 2.3.6; en-us; Nexus S Build/GRK39F) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1","Avant Browser/1.2.789rel1 (http://www.avantbrowser.com)","Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/532.5 (KHTML, like Gecko) Chrome/4.0.249.0 Safari/532.5","Mozilla/5.0 (Windows; U; Windows NT 5.2; en-US) AppleWebKit/532.9 (KHTML, like Gecko) Chrome/5.0.310.0 Safari/532.9","Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US) AppleWebKit/534.7 (KHTML, like Gecko) Chrome/7.0.514.0 Safari/534.7","Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US) AppleWebKit/534.14 (KHTML, like Gecko) Chrome/9.0.601.0 Safari/534.14","Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.14 (KHTML, like Gecko) Chrome/10.0.601.0 Safari/534.14","Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.20 (KHTML, like Gecko) Chrome/11.0.672.2 Safari/534.20","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.27 (KHTML, like Gecko) Chrome/12.0.712.0 Safari/534.27","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.24 Safari/535.1","Mozilla/5.0 (Windows NT 6.0) AppleWebKit/535.2 (KHTML, like Gecko) Chrome/15.0.874.120 Safari/535.2","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.7 (KHTML, like Gecko) Chrome/16.0.912.36 Safari/535.7","Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre","Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.10) Gecko/2009042316 Firefox/3.0.10","Mozilla/5.0 (Windows; U; Windows NT 6.0; en-GB; rv:1.9.0.11) Gecko/2009060215 Firefox/3.0.11 (.NET CLR 3.5.30729)","Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6 GTB5","Mozilla/5.0 (Windows; U; Windows NT 5.1; tr; rv:1.9.2.8) Gecko/20100722 Firefox/3.6.8 ( .NET CLR 3.5.30729; .NET4.0E)","Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1","Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0.1) Gecko/20100101 Firefox/4.0.1","Mozilla/5.0 (Windows NT 5.1; rv:5.0) Gecko/20100101 Firefox/5.0","Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0a2) Gecko/20110622 Firefox/6.0a2","Mozilla/5.0 (Windows NT 6.1; WOW64; rv:7.0.1) Gecko/20100101 Firefox/7.0.1","Mozilla/5.0 (Windows NT 6.1; WOW64; rv:2.0b4pre) Gecko/20100815 Minefield/4.0b4pre","Mozilla/4.0 (compatible; MSIE 5.5; Windows NT 5.0 )","Mozilla/4.0 (compatible; MSIE 5.5; Windows 98; Win 9x 4.90)","Mozilla/5.0 (Windows; U; Windows XP) Gecko MultiZilla/1.6.1.0a","Mozilla/2.02E (Win95; U)","Mozilla/3.01Gold (Win95; I)","Mozilla/4.8 [en] (Windows NT 5.1; U)","Mozilla/5.0 (Windows; U; Win98; en-US; rv:1.4) Gecko Netscape/7.1 (ax)","HTC_Dream Mozilla/5.0 (Linux; U; Android 1.5; en-ca; Build/CUPCAKE) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1","Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.2; U; de-DE) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/234.40.1 Safari/534.6 TouchPad/1.0","Mozilla/5.0 (Linux; U; Android 1.5; en-us; sdk Build/CUPCAKE) AppleWebkit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1","Mozilla/5.0 (Linux; U; Android 2.1; en-us; Nexus One Build/ERD62) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17","Mozilla/5.0 (Linux; U; Android 2.2; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1","Mozilla/5.0 (Linux; U; Android 1.5; en-us; htc_bahamas Build/CRB17) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1","Mozilla/5.0 (Linux; U; Android 2.1-update1; de-de; HTC Desire 1.19.161.5 Build/ERE27) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17","Mozilla/5.0 (Linux; U; Android 2.2; en-us; Sprint APA9292KT Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1","Mozilla/5.0 (Linux; U; Android 1.5; de-ch; HTC Hero Build/CUPCAKE) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1","Mozilla/5.0 (Linux; U; Android 2.2; en-us; ADR6300 Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1","Mozilla/5.0 (Linux; U; Android 2.1; en-us; HTC Legend Build/cupcake) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17","Mozilla/5.0 (Linux; U; Android 1.5; de-de; HTC Magic Build/PLAT-RC33) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1 FirePHP/0.3","Mozilla/5.0 (Linux; U; Android 1.6; en-us; HTC_TATTOO_A3288 Build/DRC79) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1","Mozilla/5.0 (Linux; U; Android 1.0; en-us; dream) AppleWebKit/525.10 (KHTML, like Gecko) Version/3.0.4 Mobile Safari/523.12.2","Mozilla/5.0 (Linux; U; Android 1.5; en-us; T-Mobile G1 Build/CRB43) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari 525.20.1","Mozilla/5.0 (Linux; U; Android 1.5; en-gb; T-Mobile_G2_Touch Build/CUPCAKE) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1","Mozilla/5.0 (Linux; U; Android 2.0; en-us; Droid Build/ESD20) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17","Mozilla/5.0 (Linux; U; Android 2.2; en-us; Droid Build/FRG22D) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1","Mozilla/5.0 (Linux; U; Android 2.0; en-us; Milestone Build/ SHOLS_U2_01.03.1) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17","Mozilla/5.0 (Linux; U; Android 2.0.1; de-de; Milestone Build/SHOLS_U2_01.14.0) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17","Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/525.10 (KHTML, like Gecko) Version/3.0.4 Mobile Safari/523.12.2","Mozilla/5.0 (Linux; U; Android 0.5; en-us) AppleWebKit/522 (KHTML, like Gecko) Safari/419.3","Mozilla/5.0 (Linux; U; Android 1.1; en-gb; dream) AppleWebKit/525.10 (KHTML, like Gecko) Version/3.0.4 Mobile Safari/523.12.2","Mozilla/5.0 (Linux; U; Android 2.0; en-us; Droid Build/ESD20) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17","Mozilla/5.0 (Linux; U; Android 2.1; en-us; Nexus One Build/ERD62) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17","Mozilla/5.0 (Linux; U; Android 2.2; en-us; Sprint APA9292KT Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1","Mozilla/5.0 (Linux; U; Android 2.2; en-us; ADR6300 Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1","Mozilla/5.0 (Linux; U; Android 2.2; en-ca; GT-P1000M Build/FROYO) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1","Mozilla/5.0 (Linux; U; Android 3.0.1; fr-fr; A500 Build/HRI66) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13","Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/525.10 (KHTML, like Gecko) Version/3.0.4 Mobile Safari/523.12.2","Mozilla/5.0 (Linux; U; Android 1.6; es-es; SonyEricssonX10i Build/R1FA016) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1","Mozilla/5.0 (Linux; U; Android 1.6; en-us; SonyEricssonX10i Build/R1AA056) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1",
].py (使用 的是 -redis 的 ,需要从 redis 读取 url):
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Author :
# @File : mao_yan_spider.py
# @Software : PyCharm
# @description : XXXfrom scrapy import Spider
from scrapy_redis.spiders import RedisSpiderclass TestSpider(RedisSpider):name = 'test'redis_key = 'start_urls:{0}'.format(name)# start_urls = ['http://exercise.kingname.info/exercise_middleware_ua']def parse(self, response):print('response text : {0}'.format(response.text))pass
.py 配置 ():
test.py:
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Author :
# @File : test_s.py
# @Software : PyCharm
# @description : XXXimport redis
from scrapy import cmdlinedef add_test_task():r = redis.Redis(host='127.0.0.1', port=6379)for i in range(10):url = 'http://exercise.kingname.info/exercise_middleware_ua'r.lpush('start_urls:test', url)if __name__ == "__main__":add_test_task()cmdline.execute("scrapy crawl test".split())pass
运行 test.py 截图:
可以看到 请求的 user-agent 是变化的。
from faker import Fakerclass UserAgent_Middleware():def process_request(self, request, spider):f = Faker()agent = f.firefox()request.headers['User-Agent'] = agent示例:对接
from scrapy.http import HtmlResponse
from selenium import webdriver
import timeclass SeleniumMiddleware(object):def process_request(self, request, spider):url = request.urlbrowser = webdriver.Chrome()browser.get(url)time,sleep(5)html = browser.page sourcebrowser,close()return HtmlResponse(url=request.url,body=html,request=request,encoding='utf-8,status=200)上面实现的 太简单,有一下缺点:
催佬写了一个 包,对以上的 做了一些优化
包名叫 ,安装:pip3 -
安装后只需要启用对应的 并改写 为 即可;
ES = {
'.s.':543
= 6
将并发量修改为了6,这样在爬取过程中就会同时使用 渲染6个页面了,如果电脑性能还可以的话,可以将数字调得更大些。
在中,还需要修改 为 ,同时还可以增加一些其他的配置,比如通过 来等待某一特定节点加载出来,比如原来的:
yield (start url,=self.)
就可以修改为:
yield (, =self.,='.item .name')
示例:
示例: 对接
:
示例: 对接
:
中间件
对于需要登录的网站,可以使用来保持登录状态。那么如果单独写一个小程序,用持续不断地用不同的账号登录网站,就可以得到很多不同的。由于本质上就是一段文本,所以可以把这段文本放在Redis里面。这样一来,当爬虫请求网页时,可以从Redis中读取并给爬虫换上。这样爬虫就可以一直保持登录状态。
以下面这个练习页面为例: login
如果直接用访问,得到的是登录界面的源代码,如下图所示。
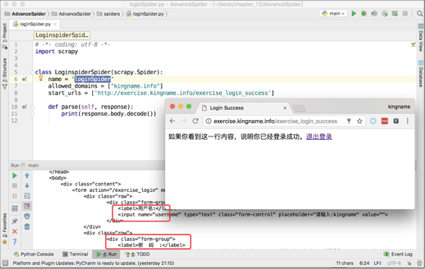
现在,使用中间件,可以实现完全不改动这个.py里面的代码,就打印出登录以后才显示的内容。
首先开发一个小程序,通过登录这个页面,并将网站返回的保存到Redis中。这个小程序的代码如下图所示。
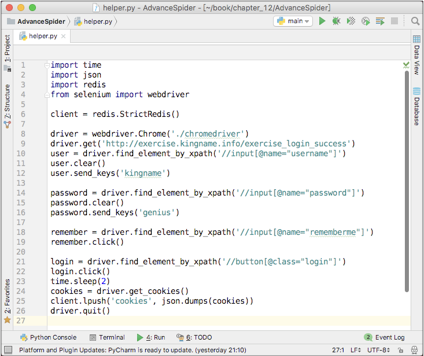
这段代码的作用是使用和填写用户名和密码,实现登录练习页面,然后将登录以后的转换为JSON格式的字符串并保存到Redis中。
接下来,再写一个中间件,用来从Redis中读取,并把这个给使用:
class LoginMiddleware(object):def __init__(self):self.client = redis.StrictRedis()def process_request(self, request, spider):if spider.name == 'loginSpider':cookies = json.loads(self.client.lpop('cookies').decode())request.cookies = cookies设置了这个中间件以后,爬虫里面的代码不需要做任何修改就可以成功得到登录以后才能看到的HTML,如图12-12所示。
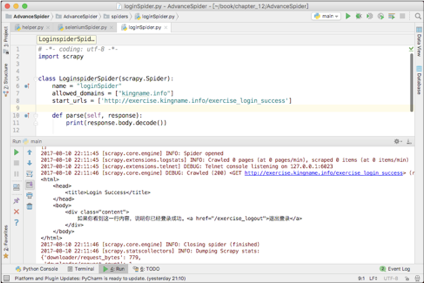
如果有某网站的100个账号,那么单独写一个程序,持续不断地用和或者 和登录,获取,并将存放到Redis中。爬虫每次访问都从Redis中读取一个新的来进行爬取,就大大降低了被网站发现或者封锁的可能性。
这种方式不仅适用于登录,也适用于验证码的处理。
内置 下载中间件 参考手册
本页面介绍了自带的所有下载中间件。关于如何使用及编写您自己的中间件,请参考 usage guide.
关于默认启用的中间件列表(及其顺序)请参考 设置。
class .s..
该中间件使得爬取需要(例如使用)的网站成为了可能。 其追踪了web 发送的,并在之后的中发送回去, 就如浏览器所做的那样。
以下设置可以用来配置中间件:
每个 多
0.15 新版功能.
通过使用 作为 meta 的 key 来支持单 追踪多 。 默认情况下其使用一个 jar(),不过您可以传递一个标示符来使用多个。
例如 ( yield 的 每个 都 有一个 meta={'': i} , 这个字段的 值只是一个标识,只要不为 None 就行,通常 设置为一个整数 。例如 1,或者 True):
for i, url in enumerate(urls): yield scrapy.Request(url="http://www.example.com", meta={'cookiejar': i}, callback=self.parse_page)需要注意的是 meta key不是”黏性的()”。 您需要在之后的 每个 请求中接着传递。例如:
def parse_page(self, response):# do some processingreturn scrapy.Request("http://www.example.com/otherpage",meta={'cookiejar': response.meta['cookiejar']},callback=self.parse_other_page)默认: True
是否启用 。如果关闭, 将不会发送给 web 。
默认: False
如果启用,将记录所有在( 请求头)发送的及接收到的(Set- 接收头)。
下边是启用 的记录的样例:
2011-04-06 14:35:10-0300 [scrapy] INFO: Spider opened
2011-04-06 14:35:10-0300 [scrapy] DEBUG: Sending cookies to: Cookie: clientlanguage_nl=en_EN
2011-04-06 14:35:14-0300 [scrapy] DEBUG: Received cookies from: <200 http://www.diningcity.com/netherlands/index.html>Set-Cookie: JSESSIONID=B~FA4DC0C496C8762AE4F1A620EAB34F38; Path=/Set-Cookie: ip_isocode=USSet-Cookie: clientlanguage_nl=en_EN; Expires=Thu, 07-Apr-2011 21:21:34 GMT; Path=/
2011-04-06 14:49:50-0300 [scrapy] DEBUG: Crawled (200) (referer: None)
[...]
ware
class .s..ware
该中间件设置 ERS 指定的默认 。
eware
class .s..eware
该中间件设置 指定的下载超时时间.
Note
You can also set per- using .meta key; this is even when eware is .













