链表——双向循环链表
双向循环链表 物理存储结构
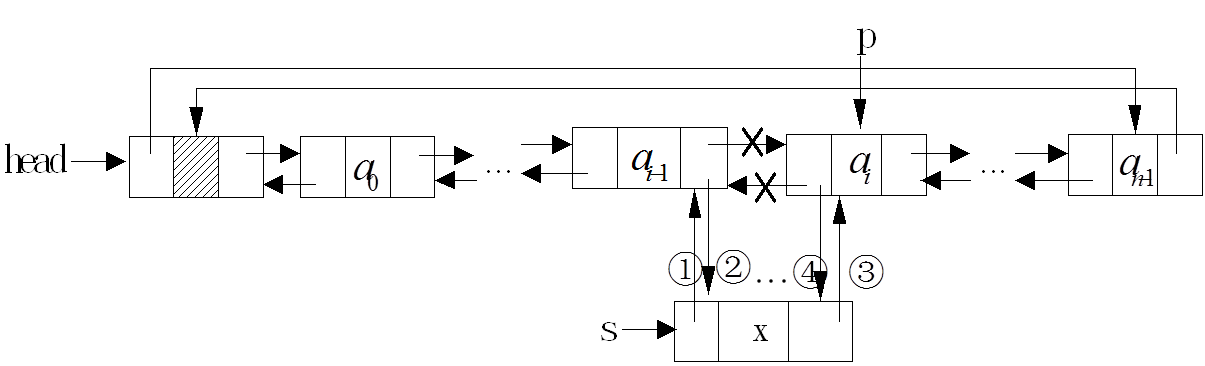
双向循环链表与单链表一样,都是逻辑连续、物理不连续的存储方式,但它的效果要远远优于单链表,其结构如下:
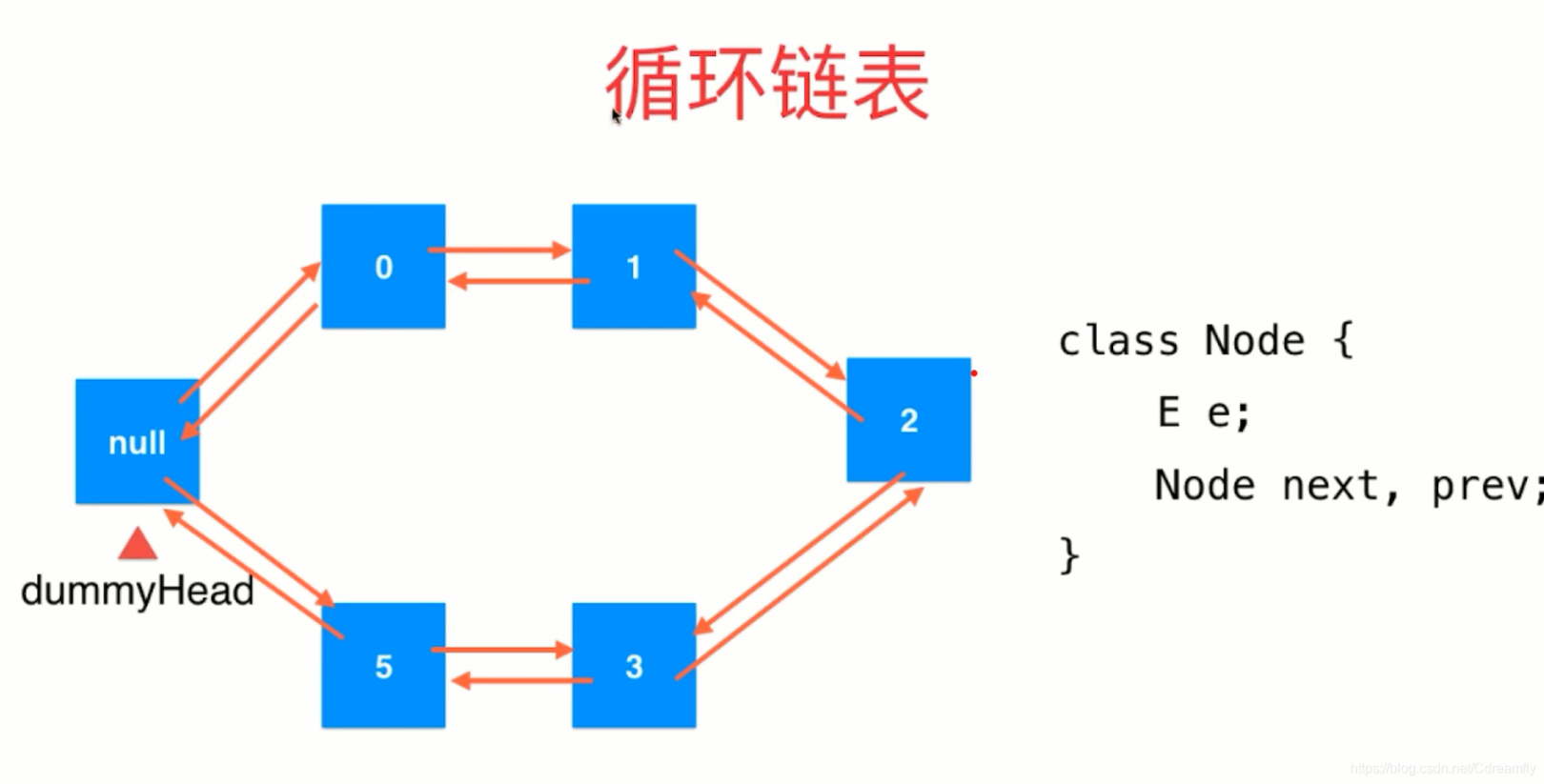
双向循环链表首先要有一个头节点,头节点中不存放数据,真正的数据从头节点的下一个节点开始存放;然后每一个节点都有两个指针,分别指向前一个节点和后一个节点;最后头尾相连,就成了双向循环链表。
代码实现
#include优缺点 优点
比起单链表和顺序表来说,执行插入删除操作更加方便,时间复杂度均为O(1)
缺点
不能像顺序表那样支持随机访问,结构较为复杂
没有增容的问题,直接用一个开一个
适用场景
需要频繁插入删除元素