Python3 +Scrapy 爬取腾讯控股股票信息存入数据库中
目标网站:
每支股票都有四个数据表
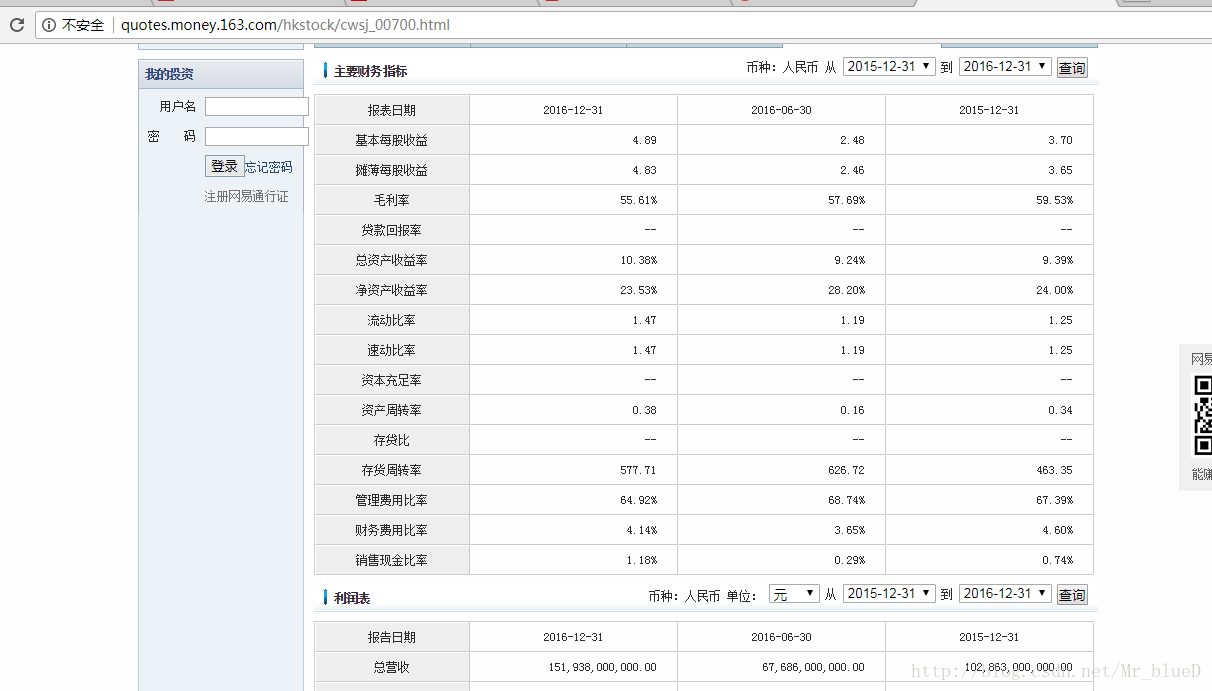
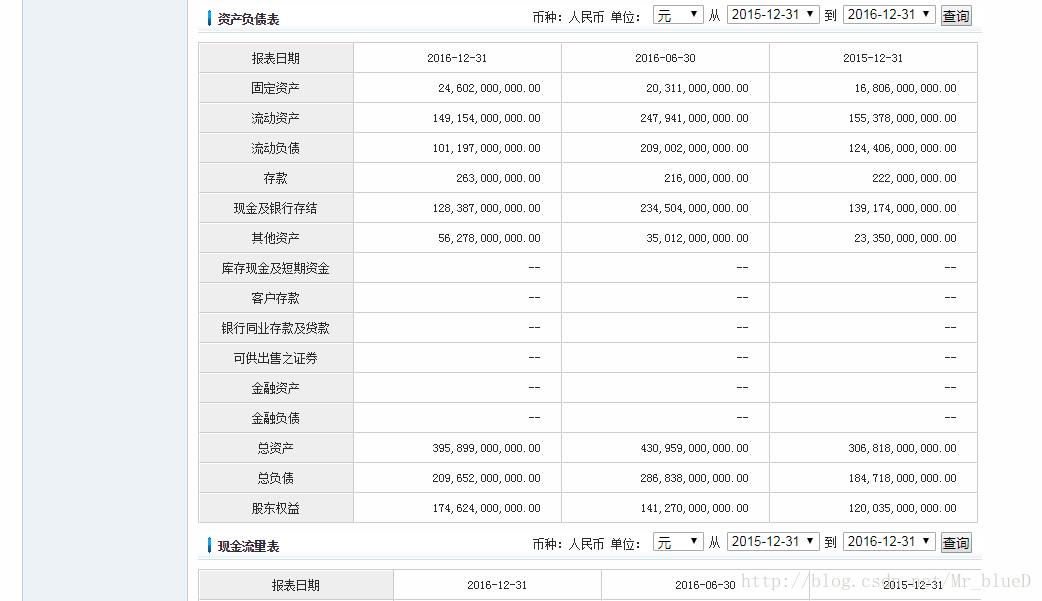
找到这四个数据表的信息所在
数据名
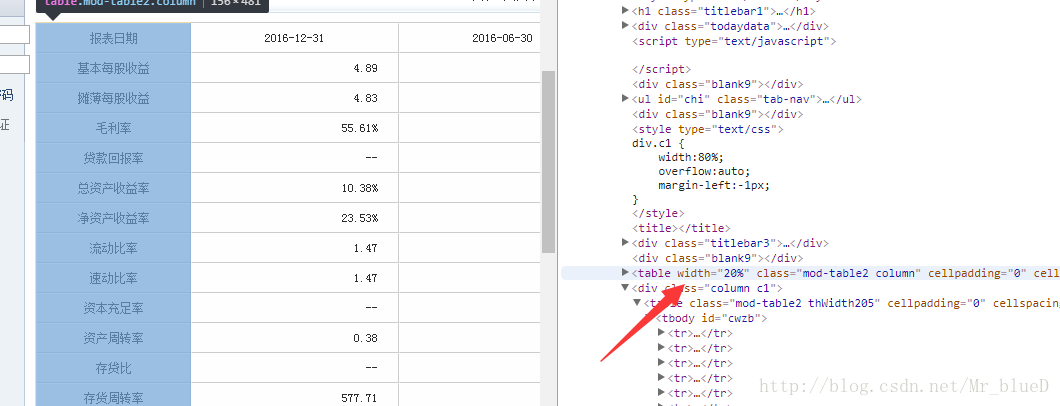
第一条到第三条数据所在
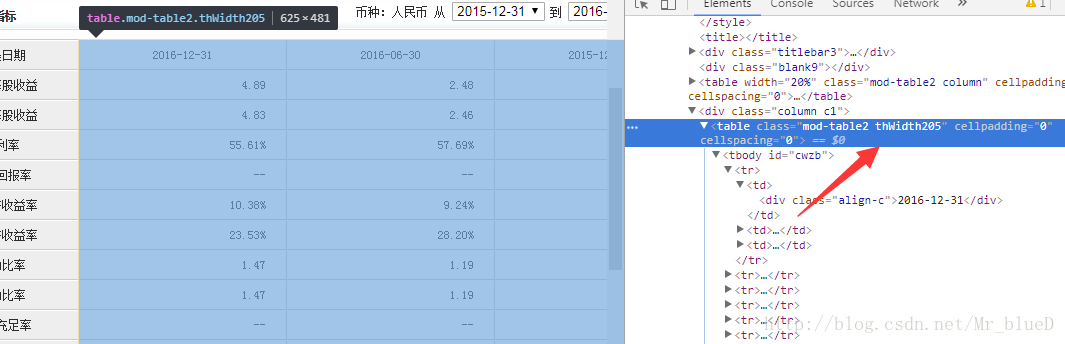
其他三个表也是这样子寻找,找到数据后,就可以动手爬取了。
于2018\3\17 重写。 一.Item
# 腾讯控股股票信息
class GupiaoItem(scrapy.Item):# 数据标题title = scrapy.Field()# 数据名dataname = scrapy.Field()# 第一条数据fristdata = scrapy.Field()# 第二条数据secondata = scrapy.Field()# 第三条数据thridata = scrapy.Field()二.
数据库创建
import pymysqldb = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='你的密码', db='数据库名', charset='utf8')cursor = db.cursor()cursor.execute('DROP TABLE IF EXISTS gupiao')sql = """CREATE TABLE gupiao( title VARCHAR(1024) NOT NULL COMMENT '数据标题', dataname VARCHAR(1024) NOT NULL COMMENT '数据名', fristdata VARCHAR(1024) DEFAULT NULL COMMENT '第一条数据',secondata VARCHAR(1024) DEFAULT NULL COMMENT '第二条数据', thridata VARCHAR(1024) DEFAULT NULL COMMENT '第三条数据', createtime DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间' )"""cursor.execute(sql)db.close()编写

import pymysqlclass MycrawlPipeline(object):def __init__(self):# 连接数据库self.conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='你的密码',db='数据库名', charset='utf8')# 建立游标对象self.cursor = self.conn.cursor()self.conn.commit()def process_item(self, item, spider):# 将item中的数据插入到数据库中try:self.cursor.execute("insert into GUPIAO (title, dataname,fristdata,secondata,thridata) \VALUES (%s,%s,%s,%s,%s)",(item['title'], item['dataname'], item['fristdata'], item['secondata'], item['thridata']))self.conn.commit()except pymysql.Error:print("Error%s,%s,%s,%s,%s" % (item['title'], item['dataname'], item['fristdata'], item['secondata'], item['thridata']))return item三.
# -*-coding:utf-8-*-from scrapy.spiders import Spider
from scrapy.http import Request
from scrapy.selector import Selector
from Mycrawl.items import GupiaoItemclass MovieSpider(Spider):# 爬虫名字,重要name = 'gupiao'allow_domains = ['quotes.money.163.com']start_urls = ['http://quotes.money.163.com/hkstock/cwsj_00700.html']def parse(self, response):item = GupiaoItem()selector = Selector(response)datas = selector.xpath('//table[@class="998b-e230-2a65-e610 mod-table2 column"]')contents = selector.xpath('//table[@class="e230-2a65-e610-fd87 mod-table2 thWidth205"]')titles = selector.xpath('//div[@class="2a65-e610-fd87-2143 titlebar3"]/span/text()').extract()# 共四张表,i 从 0 开始for i, each1 in enumerate(contents):# 第 i+1 张表的第二列所有数据content1 = each1.xpath('tbody/tr/td[1]/div')# 第 i+1 张表的第三列所有数据content2 = each1.xpath('tbody/tr/td[2]/div')# 第 i+1 张表的第四列所有数据content3 = each1.xpath('tbody/tr/td[3]/div')# 第 i+1 张表的第一列所有数据data = datas[i].xpath('tr/td')for j, each2 in enumerate(data):name = each2.xpath('text()').extract()frist = content1[j].xpath('text()').extract()second = content2[j].xpath('text()').extract()thrid = content3[j].xpath('text()').extract()item['title'] = titles[i]item['dataname'] = name[0]item['fristdata'] = frist[0]item['secondata'] = second[0]item['thridata'] = thrid[0]yield item四.结果显示
到此我们的爬虫就搭建成功了。
五.重写前的代码。 一.Item
class GupiaoItem(scrapy.Item):# 数据名dataname = scrapy.Field()# 第一条数据fristdata = scrapy.Field()# 第二条数据secondata = scrapy.Field()# 第三条数据thridata = scrapy.Field()二.
这里对应了四个爬虫,,,,与,所以对应的也需要四个,
分别爬取股票信息的四个表。
import pymysqlclass MycrawlPipeline(object):def __init__(self):# 连接数据库self.conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='1likePython',db='TESTDB', charset='utf8')# 建立游标对象self.cursor = self.conn.cursor()self.conn.commit()def process_item(self, item, spider):if spider.name == 'Gupiao0':try:self.cursor.execute("insert into Gupiao (dataname,fristdata,secondata,thridata) \VALUES (%s,%s,%s,%s)", (item['dataname'], item['fristdata'], item['secondata'], item['thridata']))self.conn.commit()except pymysql.Error:print("Error%s,%s,%s,%s" % (item['dataname'], item['fristdata'], item['secondata'], item['thridata']))return itemif spider.name == 'Gupiao1':try:self.cursor.execute("insert into Gupiao (dataname,fristdata,secondata,thridata) \VALUES (%s,%s,%s,%s)", (item['dataname'], item['fristdata'], item['secondata'], item['thridata']))self.conn.commit()except pymysql.Error:print("Error%s,%s,%s,%s" % (item['dataname'], item['fristdata'], item['secondata'], item['thridata']))return itemif spider.name == 'Gupiao2':try:self.cursor.execute("insert into Gupiao (dataname,fristdata,secondata,thridata) \VALUES (%s,%s,%s,%s)", (item['dataname'], item['fristdata'], item['secondata'], item['thridata']))self.conn.commit()except pymysql.Error:print("Error%s,%s,%s,%s" % (item['dataname'], item['fristdata'], item['secondata'], item['thridata']))return itemif spider.name == 'Gupiao3':try:self.cursor.execute("insert into Gupiao (dataname,fristdata,secondata,thridata) \VALUES (%s,%s,%s,%s)", (item['dataname'], item['fristdata'], item['secondata'], item['thridata']))self.conn.commit()except pymysql.Error:print("Error%s,%s,%s,%s" % (item['dataname'], item['fristdata'], item['secondata'], item['thridata']))return item
三.
# -*-coding:utf-8-*-from scrapy.spiders import Spider
from scrapy.http import Request
from scrapy.selector import Selectorfrom Mycrawl.items import GupiaoItem
import requestsclass MovieSpider(Spider):# 爬虫名字,重要name = 'gupiao0'# 反爬措施# headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36'}# url = 'https://movie.douban.com/top250'allow_domains = ['quotes.money.163.com']start_urls = ['http://quotes.money.163.com/hkstock/cwsj_00700.html']'''def start_requests(self):# url = 'https://movie.douban.com/top250'yield Request(self.url, headers=self.headers, callback=self.parse)'''def parse(self, response):item = GupiaoItem()selector = Selector(response)datas1 = selector.xpath('//table[@class="9b06-b23f-a7f4-b85a mod-table2 column"]')contents = selector.xpath('//table[@class="b23f-a7f4-b85a-5e22 mod-table2 thWidth205"]')content1 = contents[0].xpath('tbody/tr/td[1]/div')content2 = contents[0].xpath('tbody/tr/td[2]/div')content3 = contents[0].xpath('tbody/tr/td[3]/div')data = datas1[0].xpath('tr/td')for i, each in enumerate(data):name = each.xpath('text()').extract()frist = content1.xpath('text()').extract()second = content2.xpath('text()').extract()thrid = content3.xpath('text()').extract()item['dataname'] = name[0]item['fristdata'] = frist[0]item['secondata'] = second[0]item['thridata'] = thrid[0]yield item'''nextpage = selector.xpath('//span[@class="a7f4-b85a-5e22-c96b next"]/link/@href').extract()if nextpage:nextpage = nextpage[0]yield Request(self.url+str(nextpage), headers=self.headers, callback=self.parse)'''
# -*-coding:utf-8-*-from scrapy.spiders import Spider
from scrapy.http import Request
from scrapy.selector import Selectorfrom Mycrawl.items import GupiaoItem
import requestsclass MovieSpider(Spider):# 爬虫名字,重要name = 'gupiao1'# 反爬措施# headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36'}# url = 'https://movie.douban.com/top250'allow_domains = ['quotes.money.163.com']start_urls = ['http://quotes.money.163.com/hkstock/cwsj_00700.html']'''def start_requests(self):# url = 'https://movie.douban.com/top250'yield Request(self.url, headers=self.headers, callback=self.parse)'''def parse(self, response):item = GupiaoItem()selector = Selector(response)datas1 = selector.xpath('//table[@class="5e22-c96b-20a0-b2f6 mod-table2 column"]')contents = selector.xpath('//table[@class="c96b-20a0-b2f6-2212 mod-table2 thWidth205"]')content1 = contents[1].xpath('tbody/tr/td[1]/div')content2 = contents[1].xpath('tbody/tr/td[2]/div')content3 = contents[1].xpath('tbody/tr/td[3]/div')data = datas1[1].xpath('tr/td')for i, each in enumerate(data):name = each.xpath('text()').extract()frist = content1.xpath('text()').extract()second = content2.xpath('text()').extract()thrid = content3.xpath('text()').extract()item['dataname'] = name[0]item['fristdata'] = frist[0]item['secondata'] = second[0]item['thridata'] = thrid[0]yield item'''nextpage = selector.xpath('//span[@class="d6f8-fbd6-5969-998b next"]/link/@href').extract()if nextpage:nextpage = nextpage[0]yield Request(self.url+str(nextpage), headers=self.headers, callback=self.parse)'''
# -*-coding:utf-8-*-from scrapy.spiders import Spider
from scrapy.http import Request
from scrapy.selector import Selectorfrom Mycrawl.items import GupiaoItem
import requestsclass MovieSpider(Spider):# 爬虫名字,重要name = 'gupiao2'# 反爬措施# headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36'}# url = 'https://movie.douban.com/top250'allow_domains = ['quotes.money.163.com']start_urls = ['http://quotes.money.163.com/hkstock/cwsj_00700.html']'''def start_requests(self):# url = 'https://movie.douban.com/top250'yield Request(self.url, headers=self.headers, callback=self.parse)'''def parse(self, response):item = GupiaoItem()selector = Selector(response)datas1 = selector.xpath('//table[@class="5969-998b-e230-2a65 mod-table2 column"]')contents = selector.xpath('//table[@class="998b-e230-2a65-e610 mod-table2 thWidth205"]')content1 = contents[2].xpath('tbody/tr/td[1]/div')content2 = contents[2].xpath('tbody/tr/td[2]/div')content3 = contents[2].xpath('tbody/tr/td[3]/div')data = datas1[2].xpath('tr/td')for i, each in enumerate(data):name = each.xpath('text()').extract()frist = content1.xpath('text()').extract()second = content2.xpath('text()').extract()thrid = content3.xpath('text()').extract()item['dataname'] = name[0]item['fristdata'] = frist[0]item['secondata'] = second[0]item['thridata'] = thrid[0]yield item'''nextpage = selector.xpath('//span[@class="e230-2a65-e610-fd87 next"]/link/@href').extract()if nextpage:nextpage = nextpage[0]yield Request(self.url+str(nextpage), headers=self.headers, callback=self.parse)'''
# -*-coding:utf-8-*-from scrapy.spiders import Spider
from scrapy.http import Request
from scrapy.selector import Selectorfrom Mycrawl.items import GupiaoItem
import requestsclass MovieSpider(Spider):# 爬虫名字,重要name = 'gupiao3'# 反爬措施# headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36'}# url = 'https://movie.douban.com/top250'allow_domains = ['quotes.money.163.com']start_urls = ['http://quotes.money.163.com/hkstock/cwsj_00700.html']'''def start_requests(self):# url = 'https://movie.douban.com/top250'yield Request(self.url, headers=self.headers, callback=self.parse)'''def parse(self, response):item = GupiaoItem()selector = Selector(response)datas1 = selector.xpath('//table[@class="e610-fd87-2143-9b06 mod-table2 column"]')contents = selector.xpath('//table[@class="fd87-2143-9b06-b23f mod-table2 thWidth205"]')content1 = contents[3].xpath('tbody/tr/td[1]/div')content2 = contents[3].xpath('tbody/tr/td[2]/div')content3 = contents[3].xpath('tbody/tr/td[3]/div')data = datas1[3].xpath('tr/td')for i, each in enumerate(data):name = each.xpath('text()').extract()frist = content1.xpath('text()').extract()second = content2.xpath('text()').extract()thrid = content3.xpath('text()').extract()item['dataname'] = name[0]item['fristdata'] = frist[0]item['secondata'] = second[0]item['thridata'] = thrid[0]yield item'''nextpage = selector.xpath('//span[@class="2143-9b06-b23f-a7f4 next"]/link/@href').extract()if nextpage:nextpage = nextpage[0]yield Request(self.url+str(nextpage), headers=self.headers, callback=self.parse)'''分成四个爬虫只是为了存入数据库后的数据简介明了,而且后面三个和第一个相比只是修改了一点点,直接复制粘贴修改一下即可,并不特别费力。
四.结果显示
主要财务指标
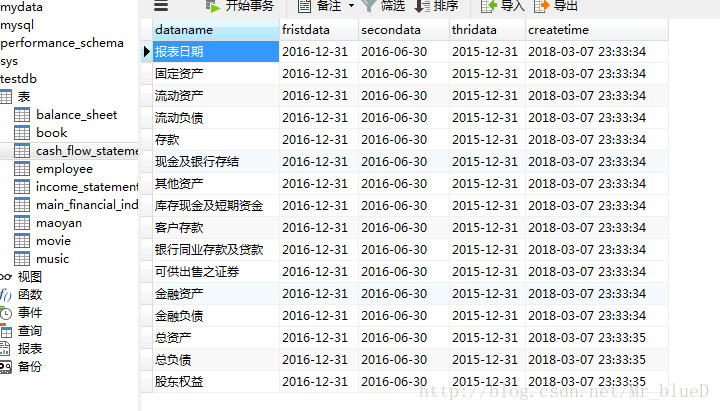
利润表
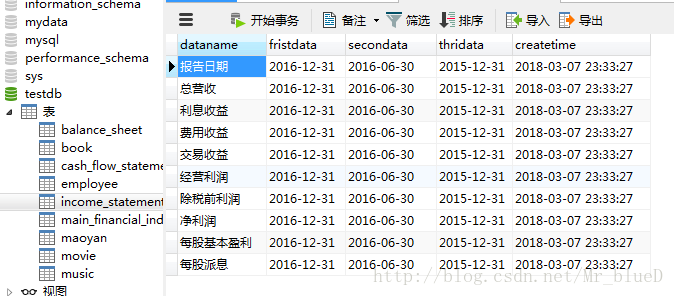
资产负债表
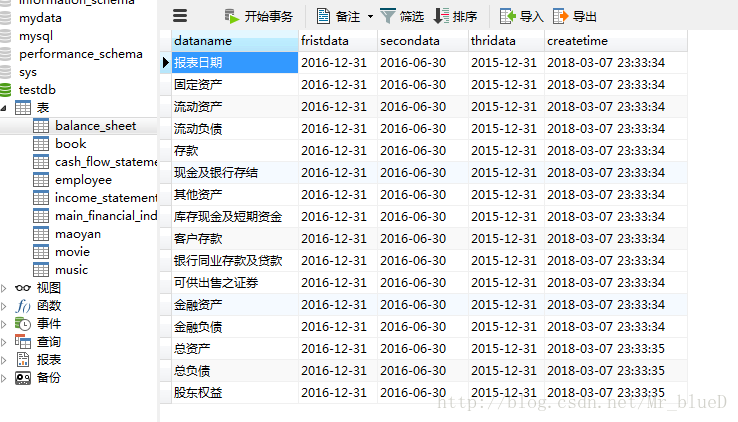
现金流量表
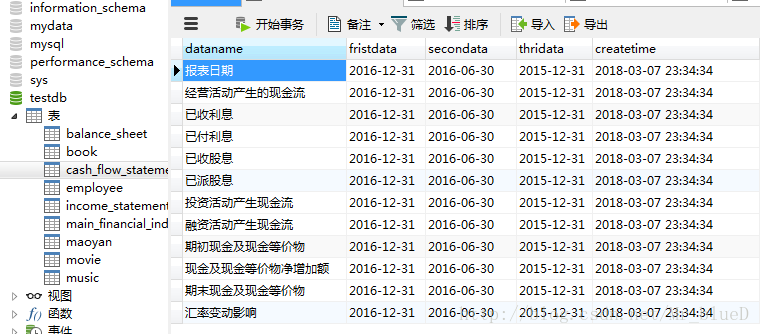
到此我们的爬虫就搭建成功了。