PTA乙级1049-数列的片段和最新AC20分
1. 最新PTA乙级1049满分代码 1.1 源码
#include1.2 关键点long 类型
上述代码的关键点在于利用long 类型对浮点数进行读入和累和。
2. 解题思路 2.1 序言
这题无非是一道找规律的题,每一个输入的数被重复累加的次数 f ( n u m [ i ] ) f(num[i]) f(num[i])满足如下公式:
f ( n u m [ i ] ) = ( i + 1 ) ∗ ( N − i ) f(num[i])=(i+1)*(N-i) f(num[i])=(i+1)∗(N−i)
*注意这里的num[i]指代输入的第 i i i个数据
这个规律不难发现,并且前人之述备矣,可参考柳神的blog1
然而此题的坑点在于不断更新的测试点2。在该测试点PTA拷打的是代码对于浮点误差的处理能力。
2.2 问题的根本来源
测试点2的问题来源说到底出在计算机的数据存储方式上,a.k.a二进制。由两个月的胎教知识我们轻松的知道二进制对于小数的存储实际上是在试着用一大堆 ( 1 2 ) n (\frac{1}{2})^{n} (21)n来逼近要存储的小数值。
也就是说如果 n n n不够大(i.e. 无法利用 ( 1 2 ) 1 t o ( 1 2 ) n (\frac{1}{2})^{1}\ to\ (\frac{1}{2})^{n} (21)1to(21)n来排列组合出想要的小数),那么我们存储的结果和预期的结果一定存在着误差。
而这里的 n n n实际上就是我们在浮点类型变量(Float-Class )中耳熟能详的“尾数精度xx位”中的那个xx。
2.3 细说浮点类型的存储精度
根据两个月胎教知识我们都知道常见的C/C++浮点型变量(i.e. 能存储小数的玩意)有如下三种:
float 单精度浮点型 % 双精度浮点型 % 长双精度浮点型 %Lf
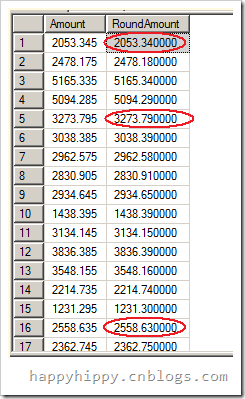
具体来说,我们现在聚焦于他们的小数/尾数精度,则可得下表:
浮点类型内存位数尾数精度
float
32
23
64
52
long
80
64
这意味着对于float类型变量而言,我们可以使用 2 − 1 t o 2 − 23 2^{-1}\ to\ 2^{-23} 2−1to2−23来逼近要存储的值。
e.g. 待存储的数据为0.,则我们可以利用float将其存储为:0,而利用结果将变成:。即0.在float存储时被近似存储为 2 − 4 + . . . + 2 − 9 + 2 − 12 + 2 − 13 + 2 − 15 + 2 − 17 + 2 − 18 + 2 − 20 2^{-4}+...+2^{-9}+2^{-12}+2^{-13}+2^{-15}+2^{-17}+2^{-18}+2^{-20} 2−4+...+2−9+2−12+2−13+2−15+2−17+2−18+2−20的结果
两个月时遗漏了这部分胎教内容的中国宝宝可以参考下文:C++基础—浮点型2
*上例中得到存储结果采用代码如下:
P.S. 因为懒得动手算,所以写了这个代码直接copy,懒是第一生产力!!!
#include
*一个有趣的point:观察内存位数可见占据共64位8字节的存储空间,而float占据32位4字节的存储空间,这就是为什么中文名中一个叫双精度一个单精度。
2.4 康康误差的产生
相信聪明的你读到上例时变察觉到了一丝不对劲,没错,在对0.的存储上,和float的结果在20~23这四位上分别为0111和1000。
然而这并非我们要讨论的误差,但是也很接近了。细心的你应该发现了这里的比较对象是两个不同类型的浮点型变量,而上文提到了浮点型变量是用二进制存储来逼近待存储的小数数据。
相信在四个月胎教中学过高等数学的你此时恍然大悟,这就好比float和是对同一个函数的某一个点进行泰勒展开最后取不同项数的结果。即这两个值对于待求值 f ( x 0 ) f(x_{0}) f(x0)而言都只是一个约数/近似值。
这时真正要讨论的误差便登上台面——浮点数的存储与真值之间存在着误差(可以类比成泰勒展开中的余项 R n + 1 ( x 0 ) R_{n+1}(x_{0}) Rn+1(x0))。举一个简单的例子如下:
e.g. 待存储数为0.,假设只用8位尾数空间存储(i.e. ),则得到如下误差: E r r = ∣ 0. − 2 − 4 − . . . − 2 − 8 ∣ = ∣ 0. − 0.0625 − . . . − 0. ∣ = 0. \begin{align*} Err&=|0.-2^{-4}-...-2^{-8}|\\ &=|0.-0.0625-...-0.|\\ &=0. \end{align*} Err=∣0.−2−4−...−2−8∣=∣0.−0.0625−...−0.∣=0.即相对误差为 ϵ % = 1.913 % \\%=1.913\% ϵ%=1.913%,貌似是可以容忍的对吧。
但是别忘了本题对于每一个输入的浮点数不仅需要累和,第 i i i个浮点数还要乘上 ( i + 1 ) ⋅ ( n − i ) (i+1)\cdot(n-i) (i+1)⋅(n−i)的权重,这也会将误差进行线性等比放大。
而这,便是不断更新的测试点2要拷打我们的地方,当被线性放大后的误差足以撼动到前两位小数时,我们便会得到错误答案。
2.5 广泛流传的解决方案
为了解决上述问题,广为流传的办法是将输入的浮点乘上1000,并将最后的结果除以1000输出。这意味着输入的前三位小数会被放大到整数部分。而两个月大便接受胎教的我们中国宝宝显然知道整数部分的二进制存储是没有误差的。
因此这一广为流传的办法可以巧妙的将0.xxx的二进制存储误差消除掉。
由此,可以得到如下代码:
#includeP.S. 补充一些C++胎教语法知识:
1.乘法中乘上1LL相当于声明该乘积将存储为long long格式
2.引用后,在输出语句前写上cout