入门|Python爬虫架构介绍
大数据时代,海量数据的获取离不开爬虫技术。再加上代理ip的帮助,爬虫技术的应用也就越来越广泛。许多企业和个人开始学习爬虫技术,而学习爬虫技术首先要掌握爬虫框架。
爬虫架构主要由五个部分组成,分别是调度器、URL管理器、网页下载器、网页解析器、应用程序(爬取的有价值数据)。
调度器:相当于一台电脑的CPU,主要负责调度URL管理器、下载器、解析器之间的协调工作。
URL管理器:包括待爬取的URL地址和已爬取的URL地址,防止重复抓取URL和循环抓取URL,实现URL管理器主要用三种方式,通过内存、数据库、缓存数据库来实现。
网页下载器:通过传入一个URL地址来下载网页,将网页转换成一个字符串,网页下载器有(官方基础模块)包括需要登录、代理、和,(第三方包)
网页解析器:将一个网页字符串进行解析,可以按照我们的要求来提取出我们有用的信息,也可以根据DOM树的解析方式来解析。网页解析器有正则表达式(直观,将网页转成字符串通过模糊匹配的方式来提取有价值的信息,当文档比较复杂的时候,该方法提取数据的时候就会非常的困难)、html.(自带的)、(第三方插件,可以使用自带的html.进行解析,也可以使用lxml进行解析,相对于其他几种来说要强大一些)、lxml(第三方插件,可以解析xml和HTML),html.和以及lxml都是以DOM树的方式进行解析的。
应用程序:就是从网页中提取的有用数据组成的一个应用。
下面用一个图来解释一下调度器是如何协调工作的
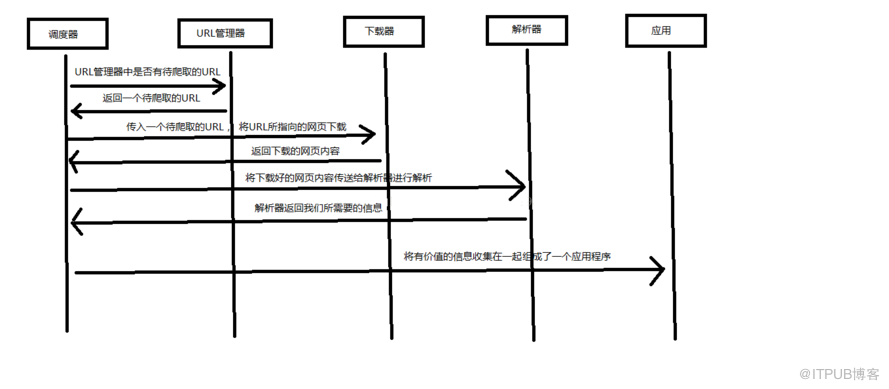
了解了爬虫架构可以帮助我们更好的爬取数据,不过频繁操作爬取可能会导致IP受限哦,所以得使用代理IP软件哦~