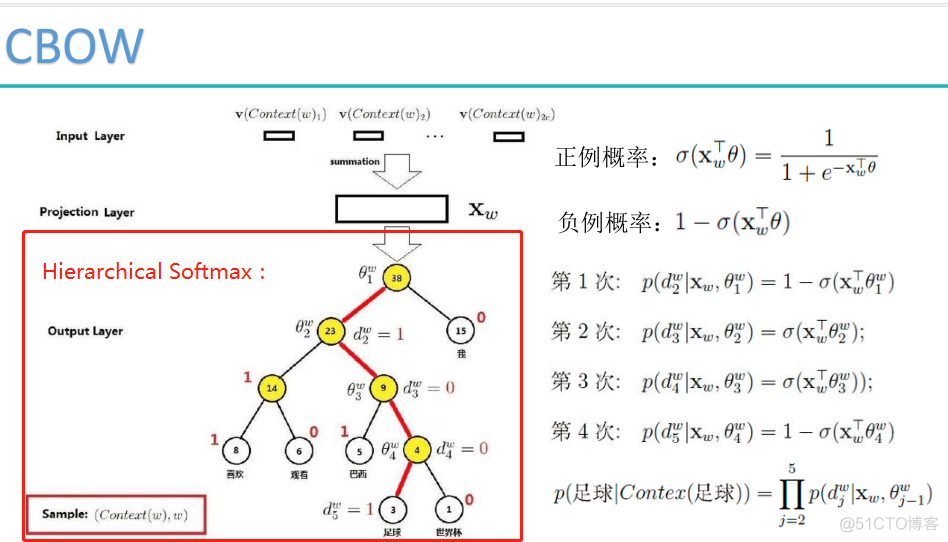
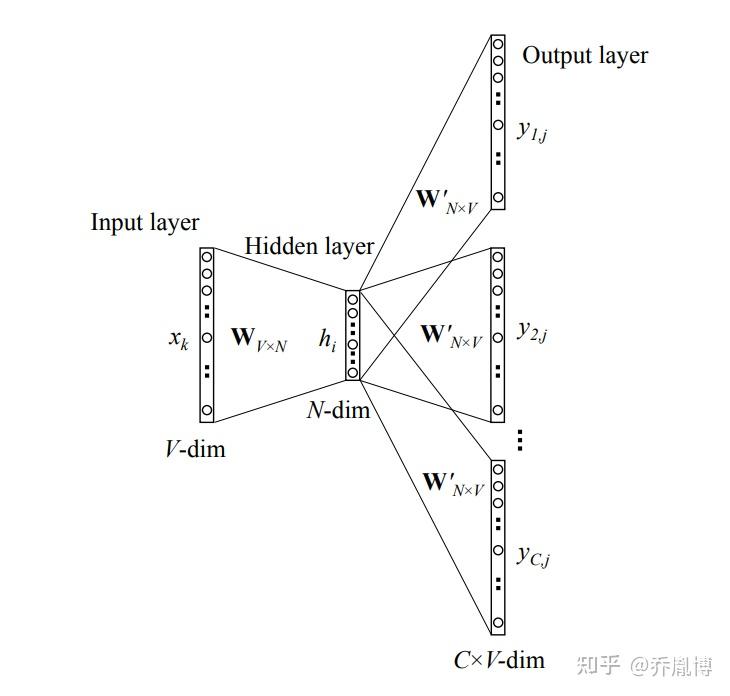
NLP 的 Task 和 Metric (Perplexity,BLEU
Task
1. 信息检索IR( )
信息检索(NLU)是指通过在大规模的文本库或数据库中搜索相关信息,将与用户查询匹配的文档或记录返回给用户。信息检索主要涉及到索引构建、查询处理和结果排序等技术,旨在帮助用户快速有效地获取所需的信息。
讲query和映射到同一个特征空间,进行相似度计算,避免传统IR中词汇和语义失配的问题。
模型架构
Cross-架构:先将 query 和 的进行拼接一起送入共同的LM,将CLS token作为两者的共同表征。 hinge loss 类似三元组损失,用于拉近正样本对,分离负样本对。
Dual-架构:分别对query 和 进行编码,再对特征向量计算NLL损失,对比学习。
这个架构的好处在于,可以提前对进行编码,构建index索引,有新的query时,只对query进行编码,使用faiss等KNN向量库,实现快速匹配。
评价指标
用于衡量检索系统在返回前K个结果时的性能 (仅对TOP-K个检索对象进行评价)。
发展方向 如何挖掘更难的负样本对儿?
ANCE使得模型在训练过程中,异步维护一个程序,每训练k步做一次,把推理中排名靠前的错误结果作为难负样本,将其加入下一轮的训练过程中。
如何更好的做大模型的预训练?
SEED使用 很弱的 去强迫 产生更强的CLS特征表示。
如何提升模型的few-shot性能?
2. 文本生成TG(Text )
文本生成(NLG)是指使用计算机自动生成自然语言文本的过程。文本生成可以基于特定的规则、模板或者统计模型来进行,它可以用于生成各种形式的文本,如文章、对话、摘要、标题等。文本生成的应用领域包括自动摘要、机器翻译、智能客服等。
主要包含两种文本生成模式:、,这2个任务都属于自然语言生成领域,但关注的问题和任务目标略有不同。主要关注如何将结构化数据转化为自然语言文本,而则涵盖了各种文本到文本的转化任务。
2.1 Data-to-text

输入的data可以是image(图像理解)、table(表格理解)、graph、json等非文本数据,输出对data的总结文本
(数据到文本):该任务的目标是根据给定的结构化数据,将其转化为自然语言文本。常见的应用包括生成报告、摘要、描述等。例如,在天气预报中,将气象数据(如温度、湿度等)转化为可读的天气预报文本。
2.2 Text-to-text
(文本到文本)是一个广泛的任务领域,涵盖了各种自然语言生成任务。的目标是将输入的自然语言文本转化为另一种形式的自然语言文本,如机器翻译、文本摘要、问答生成、文本风格转换等。例如,将一篇英文文章翻译成中文,将一段文本生成概括性摘要,或者将问题转化为回答。
比如摘要 总结
比如对话系统旨在实现人机之间的自然对话交互。它可以是任务驱动型对话系统,根据用户提供的指令或需求回答问题或完成任务;也可以是开放型对话系统,与用户进行自由对话。对话系统需要理解上下文、生成连贯的回复并与用户进行有效的交互。
模型架构
类型:
评价指标
**通用指标:**BLUE、、ROUGH、NIST、METOR、CIDEr
其他指标:
可控文本生成 TG
输入: + text
模型层面: + Model
修改概率分布:
修改模型结构:
3. 问答QA( )
问答(NLU+NLG)是指系统根据用户提出的问题,在预定义的知识库或文本集合中,寻找并生成准确的答案。问答可以结合NLU和NLG两个方面的技术。NLU用于理解用户的问题,将其转化为机器可以理解的形式,并确定查询的关键信息。NLG则用于将从知识库中找到的答案生成自然语言形式的回答并返回给用户。
3.1 阅读理解RC
RC Task设计有:Cloze test完形填空(CNN/Daily Mail、CBT)、 多选(RACE)、 答案在原文的提取问答(SQuAD)
模型架构
可以直接把query和拼在一起,送入BERT等语言模型一起编码交互:
大模型统一了阅读理解的形式:将提取式阅读理解(答案在文中)、总结式阅读理解(答案不在文中)、选择题、判断题等多种问题,统一为的范式。
3.2 开放域问答 OQA
Open- QA则是我们可以问任何事实性问题,一般是给你一个海量文本的语料库,比方/百度百科,让你从这个里面去找回答任意非主观问题的答案,这显然就困难地多。
模型架构
RAG检索增强生成:联合预训练检索器和大语言模型,如REALM。
mask掉的文本做完形填空,将mask的text作为query,将query和检索到的前k个知识库内容拼接,送入大模型进行生成(回答被mask掉的text)。
除了在提前构架好的外部知识库中检索,还可以在互联网上进行海量检索:
BLEU, , ROUGE 一般在机器翻译里用,CIDEr 一般在图像字幕生成里用
BLEU
所谓BLEU,最开始是用于机器翻译中。他的思想其实很,对于一个给定的句子,有标准译文S1,还有一个神经网络翻译的句子S2。BLEU的思想就是对于出现机器翻译S2的所有短语,看有多少个短语出现在S1中,然后算一下这个比率就是BLEU的分数了(类似)。首先根据n-gram划分一个短语包含单词的数量,有BLEU-1,BLEU-2,BLEU-3,BLEU-4。分别就是把文章划分成长度为1个单词的短语,长度为2个单词的短语…然后统计这些短语出现在标准译文中个数,在分别除以划分总数,就是对应的BLEU-1分数,BLEU-2分数…,其实就是准确率。看这些划分的短语中有多少是出现在标准译文当中的。一般而言: 的准确率可以用于衡量单词翻译的准确性,更高阶的 n-gram 的准确率可以用来衡量句子的流畅性 n{1,2,3,4}
但是BLEU会有个缺陷,假如我就翻译一个单词,而这个单词正好在标准译文中(译文特别短),那岂不是准确率100%,对于这个缺陷,BLEU算法会有个长度惩罚因子,就是翻译太短了就会有惩罚。还有一个缺陷就是BLUE score没有考虑译文中单词的顺序。
代码层面具体怎么使用建议看:
METOR
其大意是说有时候翻译模型翻译的结果是对的,只是碰巧跟参考译文没对上(比如用了一个同义词),于是用 等知识源扩充了一下同义词集,同时考虑了单词的词形(词干相同的词也认为是部分匹配的,也应该给予一定的奖励,比如说把 likes 翻译成了 like 总比翻译成别的乱七八糟的词要好吧?)在评价句子流畅性的时候,用了 chunk 的概念(候选译文和参考译文能够对齐的、空间排列上连续的单词形成一个 chunk,这个对齐算法是一个有点复杂的启发式 beam ),chunk 的数目越少意味着每个 chunk 的平均长度越长,也就是说候选译文和参考译文的语序越一致。最后还有召回率和准确率两者都要考虑,用 F 值作为最后的评价指标。
的缺点也很明显,其一是只有 Java 实现,而且还是 jar 包不是 API,只能算整个测试集上的 而不是每条语句单独测(除非你把每条语句单独写到文件里然后调 jar 包),实在是太蠢了。在 统治深度学习的当下,可想而知很少有人用这个指标……
ROUGH
ROUGE算法基本思路和BLEU差不多,不过它统计的是召回率,也就是对于标准译文中的短语,统计一下它们有多少个出现在机器翻译的译文当中(刚好和BLUE反过来),其实就是看机器翻译有多少个翻译对了,这个评价指标主要在于标准译文中的短语都出现过,那么自然机器翻译的译文越长结果越好。
CIDEr
常用语图像字幕生成,CIDEr 是 BLEU 和向量空间模型的结合。它把每个句子看成文档,然后计算 TF-IDF 向量(只不过 term 是 n-gram 而不是单词)的余弦夹角,据此得到候选句子和参考句子的相似度,同样是不同长度的 n-gram 相似度取平均得到最终结果。优点是不同的 n-gram 随着 TF-IDF 的不同而有不同的权重,因为整个语料里更常见的 n-gram 包含了更小的信息量。图像字幕生成评价的要点是看模型有没有抓取到关键信息,比如说一幅图的内容是『白天一个人在游泳池游泳』,其中最关键的信息应该是『游泳』,生成字幕时如果包含或者漏掉了一些别的信息(比如说『白天』)其实是无关紧要的,所以需要这么一种对非关键词降权的操作。