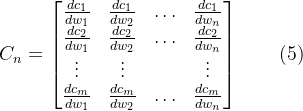2.1. Neural 3D shape representation
论文阅读 iNeRF: for Pose 3. . iNeRF 4.3. Self- NeRF with iNeRF 5.
2022.12.3更新:1、经过实验,该方法可以克服小规模的平移、旋转、尺度偏移;2、测试了几张风格迁移的数据,居然也能找到位姿,这个要再研究看看。
Pose has been a hot spot for a long time. It is used in SLAM and can be as an for tasks. This paper a that can 6DoF of the input image a pre- NeRF model, which means this from the ones that rely on CAD .
这类文章给我最大的冲击和启示就是:当你想像一个人一样智能地研究一个视觉问题,目前你最可能的就是去寻求神经网络方法的帮助,那么如何让网络能够懂你的意图,最直接的就是设计一个合理的loss 。在有了loss的评判规则后,可以设计例如, filed等机制帮助网络更好地找侧重点。
以本文的位姿估计任务为例,这里采用的是一种“-by-”的方法,在其中通过预训练的NeRF模型来投射光线到已知内参数的相机影像上,比较和之间的loss, then we the to the NeRF model. 通过这样的迭代方式不断优化 image的和。
本文的位姿估计需要三个条件:1、一张 image;2、这张影像的初始位姿;3、一个对场景或物体的预训练NeRF。后面的一篇文章对这个做了改进,其中一个就是利用运算效率的巨大提升,采用蒙特卡洛采样的方式,可以不需要初始位置(但是也只是小范围内),并且由于同时并行多个判断,可以使算法避免陷入局部最优的困境(这个很好理解)。
1.
-by-的方法在上述中有一个问题,就是计算和之间的loss时,最直白的方式就是要渲染出一张与观测值内参相同的影像,这需要一定的计算代价。iNeRF的解决方案是,利用NeRF模型可以同时独立地渲染光线和像素(NeRF’s ray- rays and to be )(NeRF模型允许在其场有效范围内以射线的形式渲染光线),采用一种基于兴趣点的( point-based)的采样策略来决定哪些光线是揭示物体姿态的最优选择,从而采样这些光线。
同时,iNeRF还可以增强NeRF的渲染效果,因为很多没有经过标注的影像在得到位姿估计后可以加入train set来提升NeRF模型构建效果。(人一定要学会联想,我以前也看到了无初始外参的NeRF训练方法,我怎么就没想到可以用到位姿估计里面?少用一类的傻瓜软件,用多了自己就变傻瓜了!)
文章说iNeRF可以用于类别级目标位姿估计。
解释一下,类别级目标位姿估计(-level pose ):
-level pose aims to find 6D poses of from known to CAD .
在文章的main 中提到,文章详细研究了光线采样和梯度优化的对结果的鲁棒性和局限性。
2. Works
两点:
2.1. 3D shape
以NeRF和其衍生模型为代表。
2.2. Pose from RGB
经典的方式是检测影像和已知的三维模型的特征点,2d和3d匹配。(貌似就是提了一个PnP graph 来解决这个问题)
近期的方式有:1)使用CNN-based结构直接估计物体的姿态;2)估计2D关键点,并用PnP-算法求解姿态。但上述所有工作都需要在训练和测试期间访问物体的三维模型,这极大地限制了这些方法的适用性。
本文的方法使用了NeRF模型形式的连续隐式3D表示,这些模型已经被经验证明可以产生更多的真实感新视角图像渲染( novel ),我们假设这样可以实现更高保真的位姿估计,然后使用迭代图像对齐来估计位姿。
3.
这部分讲了NeRF的原理,不了解的同学可以看看。
4. iNeRF
这里需要学一点李群、李代数。不然看不懂SO(3)( Group)特殊正交群、SE(3)( Group)特殊欧式群。快速入门参照:入门,空间旋转的李群李代数简述,更系统地入门。
李群和李代数在此处简而言之:旋转矩阵属于三维空间的特殊正交群SO(3),李代数so(3)是李群的指数坐标表示,在表示空间旋转时,旋转矩阵采用左乘的运算 R ′ = Δ R ⋅ R R'=\Delta R\cdot R R′=ΔR⋅R,其中 Δ R \Delta R ΔR 是微小旋转。由于旋转矩阵是特殊正交群且对加法不封闭,在对旋转过程求导时会变得很复杂,因此希望寻求一种“化乘为加”的方式。因此引入李代数,用BCH公式将旋转表示为:(不会用这个公式编辑器,此处用A取代^,表示该向量的反对称矩阵)
Δ R ⋅ R = e x p ( Δ ϕ A ) e x p ( ϕ A ) = e x p ( ( ϕ + J l − 1 ( ϕ ) Δ ϕ ) A ) \Delta R\cdot R=exp(\Delta \phi^{A} )exp(\phi^{A})=exp((\phi+J_{l}^{-1}(\phi)\Delta \phi)^{A}) ΔR⋅R=exp(ΔϕA)exp(ϕA)=exp((ϕ+Jl−1(ϕ)Δϕ)A)
这样或许有助于空间旋转的求导。回到iNeRF的整个逻辑。文章首先指出了,求解pose就是求解Loss的优化问题,式中 T T T:Pose , Θ Θ Θ: of a NeRF, I I I:
用 T T T表示位姿pose,且 T T T是特殊欧式群(可以理解为SO(3)是三维旋转变换,SE(3)是三维刚体变换:旋转+平移)。Loss的思想可以来源于NeRF训练时采用的损失函数,但是反向传播的时候不是作用在NeRF的权值上,而是更新在 T T T上。
文章在这里指出:Loss在6DoF的李群空间(SE(3))上是非凸的(non-),并且渲染完全的图像这个计算代价在迭代循环中是无法容忍的。针对这个问题,文章讨论了下面三个问题:(这块是文章的核心,注意了!)
(i) The -based SE(3)
(ii) Ray
(iii) How to use iNeRF’s poses to NeRF
4.1. -Based SE(3)
T ^ i \hat{T}_i T^i 表示为当前(i轮迭代)的估计位姿。原文表述为:为了使估计的pose T ^ i \hat{T}_i T^i 能够“ to lie on the SE(3) -based ”,这里的指的是下图(other paper)的绿色流形,该流形是因为刚体变换产生, S S S指代了刚体运动,其中 S = [ S ω , S v ] S=[S_\omega, S_v] S=[Sω,Sv], ω \omega ω 指代旋转, v v v 指代平移。
(接上文)文章用指数坐标参数化 T ^ i \hat{T}_i T^i,设置一个从相机frame到模型frame初始位姿估计: T ^ 0 ∈ S E ( 3 ) \hat{T}_0∈ SE(3) T^0∈SE(3), T ^ i \hat{T}_i T^i可以表示为:
上面这个公式的解释我实在看不懂 ,是一本书里面讲的“ ”,这个公式的讲解视频李群指数坐标参数化讲解。
2022.12.5更新一下该”旋转“表示的理解:三维空间的刚体运动求导可以参考这篇博客:运动旋量和李代数求导
首先引入运动矢量概念,以旋转为例: w = [ a 1 , a 2 , a 3 ] w=[a_1,a_2,a_3] w=[a1,a2,a3],单位向量表示旋转轴,模长表示旋转角度。对线速度来说同理,模长表示运动距离。
刚体运动由旋转和平移组成,以运动旋量的表示: S = [ w , v ] T S=[w,v]^T S=[w,v]T 表示运动旋量。同时 S = [ w , v ] T S=[w,v]^T S=[w,v]T 也可以用来表示螺旋轴,此时 w , v w,v w,v 其中有一个为单位矢量。(螺旋轴,原文表述是:screw axis。 w 和 v w和v w和v中只能有一个单位矢量,因为只有一个 θ \theta θ去表示量级),其中 w w w 表示刚体运动的旋转运动矢量, v v v 表示刚体运动的平移运动矢量。 ∣ ∣ w ∣ ∣ = 0 ||w||=0 ∣∣w∣∣=0 表示只存在平移运动; ∣ ∣ v ∣ ∣ = 0 ||v||=0 ∣∣v∣∣=0 表示只存在旋转运动。
整个iNeRF的优化过程可以理解为函数的迭代拟合,iNeRF的前向传播函数就是:
T i ^ = f o r w a r d ( T 0 ^ ) , T i ^ = e [ S i ] θ i T 0 ^ \hat{T_i}=(\hat{T_0}),\quad\hat{T_i}=e^{[S_i]\}\hat{T_0} Ti^=(T0^),Ti^=e[Si]θiT0^
对于任意的运动旋量 V V V 都可以分解为旋转和平移 V = [ w , v ] V=[w,v] V=[w,v],当 ω ! = 0 \omega!=0 ω!=0 时,存在一个等效的螺旋轴 S S S 和旋转速度 θ \theta θ。在原文中对 θ \theta θ 的解释是:。有一种解释中说:
当 ω ! = 0 \omega != 0 ω!=0 时, θ = ∣ ∣ w ∣ ∣ \theta=||w|| θ=∣∣w∣∣,螺旋轴 S = [ w ∣ ∣ w ∣ ∣ , v ∣ ∣ w ∣ ∣ ] = V ∣ ∣ w ∣ ∣ S=[\frac{w}{||w||},\frac{v}{||w||}]=\frac{V}{||w||} S=[∣∣w∣∣w,∣∣w∣∣v]=∣∣w∣∣V,因此有: S θ = V S\theta=V Sθ=V。
当 ω = 0 \omega=0 ω=0 时,仅有平移运动, θ = ∣ ∣ v ∣ ∣ \theta=||v|| θ=∣∣v∣∣。
则有:
S = [ w , v ] T ∈ R 6 S=[w,v]^T∈R^6 S=[w,v]T∈R6
[ S ] = [ [ w ] v 0 0 ] [S]= \left[ \begin{array}{ccc} [w] & v\\ 0 & 0 \end{array} \right ] [S]=[[w]0v0]
在描述螺旋轴时(screw axis), w w w, v v v 为单位矢量,而描述运动旋量的时候则不需要(可以用自身的模长来表示各自的标量)。
经过上面的转换,优化问题变成了
优化问题的难点就在于,计算出来的Loss要如何改正 T i T_i Ti 也就是 e [ S i ] θ i T 0 e^{[S_i]\}T_0 e[Si]θiT0。用最基础的梯度下降法,即对 e [ S i ] θ i T 0 e^{[S_i]\}T_0 e[Si]θiT0 求导:
e [ S ] θ = [ e [ w ] θ K ( S , θ ) 0 1 ] e^{[S]\theta}=\left[ \begin{array}{ccc} e^{[w]\theta} & K(S,\theta)\\ 0 & 1 \end{array} \right ] e[S]θ=[e[w]θ0K(S,θ)1]
K ( S , θ ) = ( I θ + ( 1 − c o s θ ) [ ω ] + ( θ − s i n θ ) [ ω ] 2 ) v , 注 意 这 里 的 I 是 单 位 矩 阵 K(S,\theta)=(I\theta+(1-cos\theta)[\omega]+(\theta-sin\theta)[\omega]^2)v,\quad注意这里的I是单位矩阵 K(S,θ)=(Iθ+(1−cosθ)[ω]+(θ−sinθ)[ω]2)v,注意这里的I是单位矩阵
上面这个公式形似罗德里格斯公式。至此,pose的姿态变换(刚体运动)被表示成了一个可微的形式: e [ S ] θ e^{[S]\theta} e[S]θ,在迭代的过程中更新参数 w , v w,v w,v,收敛后获得最终的位置姿态。在实践中具体的求导就交给的()吧。
4.2. Rays
这部分的逻辑很通畅。背景是:对一张图像做full size的渲染和前向、反向传播,所带来的计算代价是无法容忍的。因此需要找到一种采样策略,通过采样那些对位姿估计有帮助的光线提升精度和计算效率。
文章列出了三种采样策略:随机采样,兴趣点采样,兴趣区域采样。
图中的三种标识,蓝色 x 表示兴趣点(兴趣光线)采样到了背景上;红色 + 表示采样点在和上的非背景区域都存在;绿色 o 表示采样点只存在于和的非背景区域之一。
蓝色显然是无效的,对位姿估计没有帮助;红色大多是情况下已经得到了校准,对位姿的更新帮助有限;而绿色的则可以帮助获取高精度的位姿估计和更快的收敛速度。
a)
效果和效率很差,不讨论了。
在NeRF的开源代码里面,有在为False的条件下使用了随机采样,具体那部分的代码我还没细看。
b) Point
受到图像对齐(image )文献的启发。兴趣点采样的方式是:首先用特征检测子检测兴趣点,如果数量不够则再用随机采样补充点数。
兴趣点采样的缺点在于,这样做在优化问题中容易陷入局部最优,因为采集到的点只考虑 image上的兴趣点(原文是:we found that it is prone to local as it only on the image of from both the and . 我也没懂这是为啥)。
与此同时虽然用了兴趣点采样方法可以避免full size的反向传播,但是要得到渲染图像上的兴趣点还是需要进行正向传播(即渲染过程),这个计算代价在迭代优化过程中不可忽视,原文论述为: to be used in the .
c)
为了解决局部最优和效率问题,文章提出了一种兴趣区域(松弛兴趣点)采样方案。首先还是对 image进行特征点提取,提取后对特征点区域进行 I I I 次5 x 5的形态学扩张(或者叫膨胀 )以此来扩大采样区域,避免全尺寸正向渲染结果。值得注意的是如果 I I I 太大,该方法就退化成了随机采样。在实验中文章发现这样做在batch size of rays较小的时候有着很大的提速效果。
4.3. Self- NeRF with iNeRF
这部分讲了iNeRF定位后的影像可以 NeRF的效果,这样可以让 NeRF 的训练成为一个半自监督的过程。这部分给我的启发是,空地NeRF的训练成为可能。这个很有价值,省去了配准过程,可以看看。
5.
文章后面的部分略。
较为遥远的下一步是研究在没有完整nerf的时候,看看能不能使用cGAN等的方法“脑补”场景,这一个启发来自于“从卫星视角找出地面视角拍摄的照片的大概水平位置”。