人人都懂计算机(二):0和1的世界
前言:《人人都懂计算机》系列博客的目的是让没有接触过计算机,或者对计算机的认识仅停留在会上网、打游戏和看电影等水平的人,能够知道计算机是什么,它的工作原理是什么。本系列博客尽量做到通俗易懂和深入浅出,同时也兼顾学术严谨,因而难免会出现一些相对专业的术语,读者如果对某些术语不是很了解,大可不必在意,这些术语完全不影响对内容的理解。
第二章 0和1的世界
很多人觉得程序员捣鼓的东西很复杂,普通人搞不懂。而事实上,程序员的世界比普通人的更简单,因为程序员的眼里只有0和1,而普通人的世界里除了0和1之外,还有有2、3、4、5、6、7、8、9。接下来就让我们一起走进程序员0和1的世界。
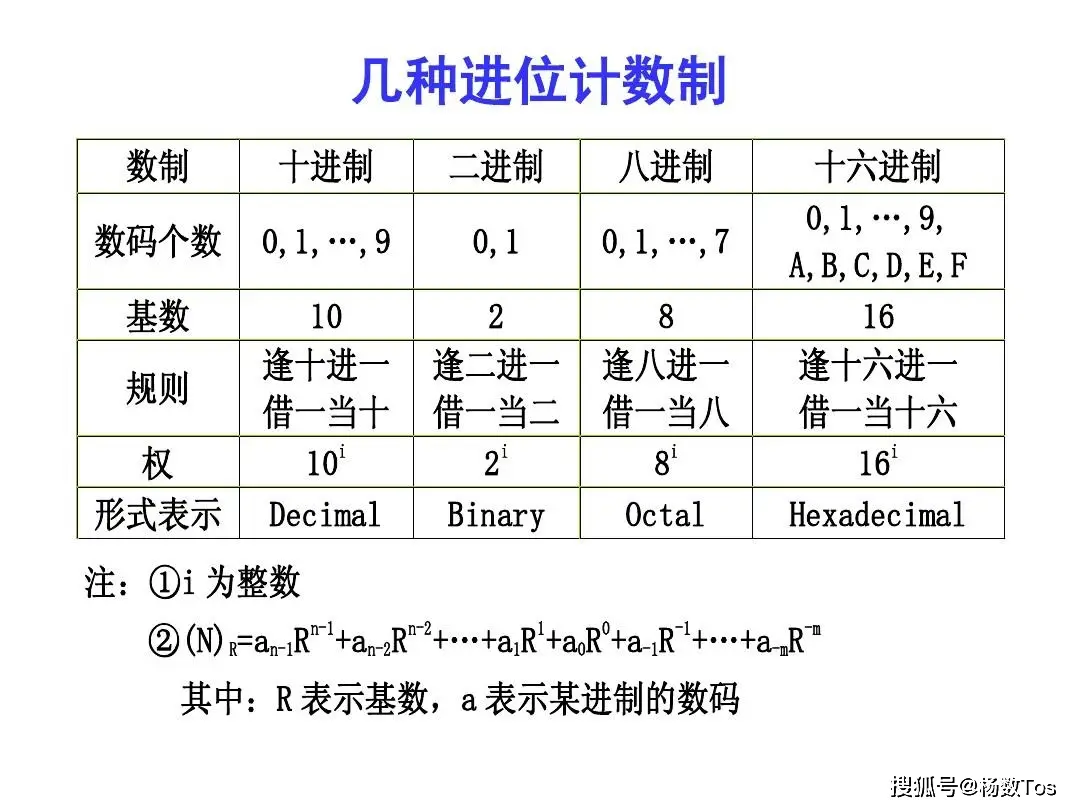
2.1 进制的概念
所谓“进制”,实际上只是人们用来计数的一种方法。现实生活中,我们天天都在使用的由0到9组成的数字就属于“十进制”。对此,大家早就习以为常,但接下来我们将换个角度来看待十进制,进而认识十进制的本质。
2.2 十进制
在十进制中,从右(低)到左(高)依次是个位、十位、百位……,而且每一位都是0~9这十个数码(符号) 中的一个。十进制下的任意一个数都可以表示成这十个基本符号的组合。之所以称为十进制,是因为在计数的时候,每当最高位的值超过9就必须再增加一位来表示,即“逢十进一”。为了更好地理解十进制,我们将一个十进制的浮点数 123.45用科学计数法表示成如下形式:
123.45=1×102+2×101+3×100+4×10−1+5×10−2(2.1)
在上式中,我们将123.45的每一位分别用该位的符号 i (i=0,1,...,9)乘以该位的 权重(个位的权重为 100 ,十位的权重为 101 ,依次类推;小数点后第一位的权重为 10−1 ,第二位的权重为 10−2 ,依次类推),而浮点数的值恰好是这些乘积的和。由此我们得出结论:十进制就是用0到9这十个互不相同的 基本符号,通过 多位数的形式来计数,高位和相邻低位之间存在十倍的关系。这就是十进制的本质。 2.3 二进制
认识了十进制之后,再理解二进制就会容易很多。不过,在正式介绍二进制之前,我们还需要先讨论一下为什么计算机会使用二进制而不是十进制。在生活中,十进制我们用得那么舒服,为什么程序员却偏偏选择了二进制呢?
2.3.1 计算机为何采用二进制
这个问题的答案,会随着你对计算机软硬件了解的不断深入而不断完善,本书只给出几个主要的原因,读者也可以在此基础上分析出更多的原因。尽管现在的计算机好像无所不能,但实际上,它数数的能力和上幼儿园时的我们差不多。还记得上幼儿园的时候学习数数吗?一开始,我们都是借助十个手指头来完成的。老师让我们数3,我们就伸出3根手指;老师让我们数5,我们就伸出5根手指;老师向你伸出4根手指,你就对老师喊4……当时的我们,没有去思考这意味着什么。实际上,我们的十根手指代表了十一种(包括伸出0根到10根手指这11种情况)可以相互区分的手势(状态),或者说十一种互不相同的符号。当时的我们很自然地将这十一种手势和数字0到10一一对应了起来。
类似地,如果计算机也采用十进制来计数的话,那么它也需要一种具有十种互不相同状态的元件,就像上幼儿园时的我们需要十根手指一样。这样的元件存在么?遗憾的是目前还没有找到。现今计算机芯片中大量集成使用的晶体管 (包括二极管、三极管、场效应管等,这些元件都是利用半导体材料制成,其中半导体是一种导电性介于导体和绝缘体之间的材料,其导电能力在制造成元器件时可以人为控制。),都只能处于两种状态:导通和不导通。这和我们平时使用的电灯开关是类似(实际上这两种情形还是有差别的:晶体管利用的是其自身的单向导通性,而电灯开关则是将电路断开)的:按一下开关,电路导通,于是电灯亮了;再按一下开关,电路断开,于是电灯灭了。计算机就是用晶体管(实际中用来记录0和1的不只是一个晶体管,而是由包括晶体管、电容和电感等组成的基本电路单元,如SRAM、DRAM等)的导通和不导通这两种状态来分别代表0和1的 。事实上,元件的“二态性”限制是计算机采用二进制的最主要原因。看到这里,你可能会疑惑:一个晶体管只能表示0和1,那比1更大的数呢?很简单:将两个相互独立的晶体管并排起来,则这两个晶体管就可以表示00、01、10和11这四种状态。如果再将这四种状态和0、1、2、3一一对应,这是不是就意味着两个并排的晶体管可以表示任何小于4的正整数了呢?类似地,如果将三个晶体管并排起来,则能表示的状态就更多,再通过一一对应,能表示的数字也就更大。计算机内存(组成计算机的不同硬件存储0和1的原理并不相同,比如硬盘就利用了磁铁的南极和北极来存储0和1。但这些硬件无一例外都利用了某种元件的二态性。其它相关硬件的存储原理本书后续会逐步介绍)就是通过这样的方式来计数的。
另外,除了电路只有导通和不导通这两种状态之外,生活中还有很多只有两种对立状态的情形:真与假、对与错、白天和黑夜、电流的正向与反向、磁铁的南极与北极等等,这些情形使用0和1来表示显然比十进制更合适。于是有学者在这类情形的基础上,建立了一套完善的理论,即逻辑代数。逻辑代数是二进制运算的理论基础。
再有,因为二进制只有0和1这两个符号,所以二进制的加法、减法、乘法和除法运算比十进制更简单,具体原因本章后续会更详细地介绍。
最后一点也很重要:二进制的抗干扰性比十进制更强。我们知道,计算机内部使用的是弱电(在电工领域,电力分为强电和弱电,其中弱电的直流电压一般在36V以内,强电则在36V以上)。以CMOS(CMOS有多重含义,这里指受电压控制的一种放大器件,是组成CMOS数字集成电路的基本单元)为例,它的正常电压范围是0V~5V。如果采用十进制,那么需要将5V等分成十份,即0.5V表示1,1V表示2,以此类推。假设现在计算机保存了数字“3”,那么它对应的电压就应该是1.5V。这时,如果电压一不小心升高了0.5V,这个数字就变成了4,就出错了。而如果采用二进制的话,由于二进制只有高(对应1)和低(对应0)两种电压取值,我们可以以2.5V为界,就算电压发生一定程度的变化,仍然容易分辨出电压的高低,从而避免出错。
2.3.2 二进制的(原码)表示
在了解了计算机使用二进制的原因,也搞懂了十进制的本质之后,再来看二进制就显得十分简单了。与十进制类似,二进制的每一位只能是0或1这两个符号之一,二进制的低位和相邻高位之间存在2倍关系,即“逢二进一”。我们用科学计数法来表示一个二进制数:
(101.01)2=1×22+0×21+1×20+0×2−1+1×22=(5.25)10(2.2)
上式中的下标“ 2 ”和“ 10 ”分别表示二进制和十进制。也有人用B()和D()分别代替“ 2 ”和“ 10 ”这两个下标,即分别表示为 (101.01)B 和 (5.25)D 。上述表示法又称为二进制的原码表示。 2.3.3 二进制的四则运算
二进制的四则运算规则和十进制的四则运算规则几乎一模一样,唯一的区别在于二进制数是“逢二进一”,而十进制数是“逢十进一”。下面以 (10.01)2 和 (1.01)2 这两个二进制数为例来介绍二进制的四则运算。

图2-1 二进制的四则运算
仔细观察图2-1中的四个例子可以看到,二进制的乘法可以通过若干次的“被乘数(或0)左移一位”和“被乘数(或0)与左移了的被乘数(或0)相加”这两种操作完成;二进制的除法则可以通过若干次的“除数右移一位”和“从被除数或余数中减去除数”这两种操作完成。换句话说,二进制的乘法可以通过左移操作转换成加法运算,而二进制的除法则可以通过右移操作转换成减法运算。这在十进制中,是没办法做到的。而且,随后我们还将看到,通过“补码”这种特殊的编码方式,二进制的减法运算也可以转换成加法运算。也就是说,十进制中复杂的四则运算在二进制中最终被简化成了只有相加、移位(左移和右移)和取反(求补码时使用)这三种对计算机来说非常简单的基本操作。这样的简化极大地降低了计算机内部电路的复杂程度,使得计算机的运算速度大幅提升。
2.3.4 二进制的补码表示
在计算机中,一个二进制位称为一个“位”或比特(Bit)。我们已经知道,一位数的十进制可以表示0到9这十个数,但一位数的二进制只能表示0和1这两个非常小的数。所以在计算机中,通常以8个二进制位为一个基本单位,每8个二进制位称为一个字节(Byte)。举例来说,十进制的5,表示成二进制就是101(如果你还不会算,看看 2.2 式)。但如果以8个二进制位为一个单位来表示的话,那就是00,000,101(当然,你也可以用两个或者多个字节来表示,即00,000,000 00,000,101。我们通常会根据数字的大小选择合适的若干个字节来表示,比如1024我们就表示成00,000,100 00,000,000),即高位全部用零补全。当然,一个字节能表示的数也是有限的(最大可以表示127,后面你就能理解为什么),对于大于127的数,我们需要用多个字节来表示。通常,两个字节称为一个字(WORD),而4个字节称为双字(DWORD)。
现在问题来了,负数怎么表示呢?有人提出了方案:让最高位作为二进制的符号位来表示数的符号,最高位为0则代表正数,为1代表负数(这种编码方式就称为原码)。在这样的编码方式下,我们有:
+5的原码是: 0−0,000,101
–5的原码是: 1−00,00,101
这样编码可以吗?答案当然是不可以。因为这样的话,由于0既可以看成是正数,也可以看成是负数,因而0的原码就有两种结果:
+0的原码是: 0−0,000,000
–0的原码是: 1−0,000,000
显然,0用原码表示不具有唯一性。于是又有人在原码的基础上提出用反码表示:正数的反码与原码相同,负数的反码则是将原码除符号位(仍为1)外,其余各位取反(取反就是0变1,1变0)。在这种编码方式下,我们有:
+5的反码是: 0−0,000,101
–5的原码是: 1−0,000,101
–5的反码是: 1−1,111,010
用反码表示行吗?很可惜,答案还是不可以。因为0的反码仍然有两种结果:
+0的反码是: 0−0,000,000
–0的原码是: 1−0,000,000
–0的反码是: 1−1,111,111
最后,有人在反码的基础上提出了补码,终于彻底解决了0表示的唯一性问题。补码的定义是:正数的补码和原码相同,负数的补码则是在反码的基础上再加1。同样地,我们有:
+5的补码是: 0−0,000,101
–5的原码是: 1−0,000,101
–5的反码是: 1−1,111,010
–5的补码是: 1−1,111,011
这里,我们来检查0的是否唯一:
+0的补码是: 0−0,000,000
–0的原码是: 1−0,000,000
–0的反码是: 1−1,111,111
–0的补码是: 100,000,000−−−−−−−−−
在上面的例子中,-0的补码在反码的基础上加1之后,变成了9位的二进制数,原本的8位无法表示了(程序员们称之为溢出)。对于这种情况,在计算机中是直接将溢出的1给丢弃,保留剩下的8位。于是,-0的补码最终变成了00,000,000,从而和+0的补码表示是一样的。于是我们得出结论:0的补码是唯一的。实际上,在计算机内部,整数都是以二进制补码的形式存储的。看到这里,你可能会问:像 (123.45)10 这样的浮点数又是如何存储的呢?对于这个问题,我们将在2.7小节予以解答。当然,计算机以补码的形式存储二进制整数还有一个更重要的原因是可以将减法运算转换成加法运算,从而进一步简化计算机硬件复杂度。具体的转换过程将在下一小节中介绍。
2.3.5 二进制补码的四则运算
在上一小节我们只是简单地给出了补码的定义,可能你对补码以及补码的特点还不是很了解。这里我们用两个简单地例子来“刷新”你对补码的认识。
第一例子来源于生活。戴过手表的人应该都会有类似的经历:早上七点起来的时候,发现手表在昨天夜里11点的时候停了。那么这个时候你有两种办法进行调整:第一,把表针往回拨4个小时(11-4 = 7);第二,把表针往前拨8个小时(11 + 8-12 = 7)。为什么第二种方法也可以呢?因为手表最大的数字是12,超过12的“进位”将被丢弃。这和我们前面讲的二进制的溢出是类似的:不管是8位、16位或者更高位的二进制,当位数确定了,它能表示的最大数字也就确定了,超过该数字的部分就溢出了。在手表这个例子中,11-4这个减法运算可以用11+8这个加法运算来代替。在这个例子中,我们称8为-4对模12的补码,其中12又称为模值。互为补码的两个数字的绝对值的和恰好等于模值。
在第二个例子中,我们直接分析二进制的补码。由前一小节可知,5的补码为00,000,101,而-5的补码为11,111,011。我们将5的补码和-5的补码直接相加得到 100,000,000−−−−−−−−− 。我们发现,相加后的结果变成了9位,而且除了最高位为1之外,低8位全部为零。如果我们直接舍弃溢出的进位,结果变成了00,000,000,即5 + (-5) = 0。看到这里,聪明的你应该已经能隐约感觉到补码的好处了吧?没错,通过补码可以将减法运算转换成加法运算。如果你还是不放心,我们再看个例子:3的补码为00,000,011,那么-3的补码为111,111,101。我们都知道5-3 = 2,那么5的补码和-3的补码直接相加为: 100,000,010−−−−−−−−− ,去掉溢出的进位变成了00,000,010,转换成十进制刚好是2。
至此,我们得出最后的结论:在二进制运算中,减去某个正数等价于加上这个数的负数所对应的补码并舍弃溢出的进位。
最后,再次重申:通过取反和移位这两种操作可以将减法、乘法和除法运算都转化为加法运算,从而极大地简化计算机内部电路的复杂程度,使得计算机的运算速度得到大幅提升。
2.4 八进制
二进制对于计算机来说固然很好,但不知道你有没有发现它的一个致命弱点:用二进制表示的数太长了。为了缩短表示数字的长度,在一些场合也会使用八进制和十六进制。和二进制类似,八进制就是用0到7这八个基本符号,通过多位数的形式来计数,高位和相邻低位之间“逢八进一”。
我们还是用科学计数法来表示一个八进制的浮点数:
(123.45)8=1×82+2×81+3×80+4×8−1+5×8−2=(664.)10(2.3)
与二进制类似,上式中的下标“ 8 ”和“ 10 ”分别表示八进制和十进制。有人也用O(Octal)来代替“ 8 ”这个下标,即表示为 (123.45)O 。除此之外,在更多的场合,我们会在八进制数的前面加一个“0”来表示这个八进制数,如:0123.45。 2.5 十六进制
相信看到这里的你已经能够理解,如果要表示十六进制的数,肯定需要十六个互不相同的基本符号。所以除了0到9这十个符号之外,我们还使用了A、B、C、D、E和F(字母大小写都可以)来分别代表10、11、12、13、14和15。如果你还是感觉理解起来有点别扭的话,我再提醒一下,请将这些数字当成是一个个的基本符号,而不要当成数字。十六进制就是用0到9和A到F这十六个基本符号,通过多位数的形式来计数的,高位和相邻低位之间“逢十六进一”。
下面用科学计数法来表示一个十六进制的浮点数:
(AB1.C)16=A×162+B×161+1×160+C×16−1=10×162+11×161+1+12×16−1=(2737.75)10(2.4)
上式中的下标“16”表示十六进制。有人也会用H()来代替“16”这个下标,即表示为(AB1.C)16。除此之外,在更多的场合,我们会在十六进制数的前面加“0x”来表示这个十六进制数,如:0xAB1.C。
题外话(看不懂也没关系):看到这里,细心的你可能会有点疑惑:八进制的英文是Octal,十六进制的英文是,那么为什么八进制前缀是“0”,而不是“o”呢?为什么十六进制是“0x”,而不是“x”呢?为什么十六进制是“0x”,而八进制不是“0o”呢?
首先解释八进制的前缀为什么是“0”而不是“o”。我们知道,计算机之所以能对我们的操作做出回应,那是因为程序员用编程语言编写了控制计算机的代码。而几乎所有编程语言都会规定,代码中变量的首字母不能是数字。所以如果八进制的前缀用“o”的话,比如“o123”出现在代码中,那计算机就不知道这到底是个变量还是一个八进制数了。相反,如果用“0”作为前缀,由于数字不能作为变量的首字母,所以计算机能肯定它不是变量。十六进制不用“x”也是同样的道理。
接着再来解释为什么十六进制用“0x”,而八进制不用“0o”。要知道,搞计算机的那些家伙都是些“极简主义者”,他们觉得 “0”和“0x”已经能区分八进制还是十六进制了,为什么还要多加一个字母,用“0o”作前缀呢?
2.6 不同进制间的互转
我们已经知道,不管是二进制、八进制、十进制还是十六进制,都是用多位数的形式来计数的,所以进制之间的转换,本质上就是计算“目标进制”下每一位上的符号(数字)。
2.6.1 二-十转换
二进制转十进制是非常简单的,只需像( 2.2 )式那样将二进制数展开,然后各项相加就可以得到等值的十进制数了。例如
(110.01)2=1×22+1×21+0×20+0×2−1+1×2−2=(6.25)10(2.5)
2.6.2 十-二转换
十进制转二进制相对来说要稍微复杂一些。如果本书直接告诉你转换的规则,相信聪明的你应该也能理解,不过可能印象就不会那么地深刻,所以在这里我打算让你自己来发现转换的规则。为此,让我们来看十进制转十进制。
我们首先来看十进制的整数转十进制。假设现在有整数 (123)10 ,让你把它转换成十进制,你要怎么转呢?你可能会觉得我脑子有问题, (123)10 转成十进制不就是 (123)10 么,还需要什么转换嘛?没错, (123)10 转换成十进制就是 (123)10 ,但这其中的转换原理却和十进制转二进制是一致的。
还记得十进制的定义吗?十进制就是用0到9这十个互不相同的基本符号,通过多位数的形式来计数,高位和相邻低位之间存在十倍的关系。十进制转十进制就可以依据这个定义来实现。为了获取十进制每一位上的符号(数字),需要用到除法和取余数这两种操作。下面是具体的转换过程:
123÷10=12余数312÷10=1余数21÷10=0余数1(2.6)
由于十进制的高位和相邻低位之间存在十倍的关系,所以在 (2.6) 式中,我们让123除以10,并将所得的商再除以10,一直除下去,直到商为零。看到这里,聪明的你应该已经觉察到了,余数3、2、1就分别对应了 (123)10 这个数字的个位、十位、百位。也就是说,将余数按反序进行排列就完成了最终的转换。
类似地,如果将十进制的整数转换成二进制的数,就可以让这个数除以2,并将所得的商再除以2,一直除下去,直到商为零。最后将余数反序排列即可。例如将 (11)10 转换成二进制就有:
11÷2=5余数15÷2=2余数12÷2=1余数01÷2=0余数1(2.7)
于是 (11)10 转换成二进制就是 (1011)2 。如果你还有疑虑,不妨仿照 (2.5) 式将转换后的 (1011)2 再转换成十进制验证一下。
学会了十进制的整数转二进制,我们接着再来看十进制的小数转二进制。相信有了前面这些基础作铺垫,这部分理解起来就很容易了。我们首先还是来分析十进制的小数转十进制。假设现在有小数 (0.103)10 ,要想把它转换成十进制,只需要获取它在十进制下每一位对应的数字即可。为此,我们需要用到乘法和取整这两种操作。下面是具体的转换过程:
0.103×10=1.03整数部分10.03×10=0.3整数部分00.3×10=3整数部分3(2.8)
在 (2.8) 式中,我们让0.103乘以10,并将所得的结果去掉整数部分,然后再将结果乘以10,直到没有小数部分。最后将每次去掉的整数部分 顺序排列起来,就得到转换后的结果。不过由于是小数,所以需要在排列结果前加上“0.”这样的前缀。
到此,十进制的小数转换成二进制的小数详细聪明的你已经知道怎么转换了吧?没错,就是每次乘以2,然后取整,直到没有小数部分为止。然后将取整的值顺序排列起来即可。比如 (0.25)10 转换成二进制就是 (0.01)2 。
最后,对于既有整数部分,又有小数部分的浮点数,如 (6.25)10 ,就可以对整数部分和小数部分分别进行转换,然后将转换后的结果相加即可。由( 2.5 )式可知, (6.25)10 转换成二进制为 (110.01)2 。
2.6.3 十-八/十六转换
十进制转八进制或者十进制转十六进制和十进制转二进制的方法完全一样,本文将不会在此再花费篇幅进行讲解。
2.6.4 二-八转换
我们知道,2的3次方恰好等于8。利用这个性质,可以极大地简化二进制和八进制之间的相互转换。为了说明这一点,我们来看一个例子: (30.25)10 对应的二进制数为 (11110.01)2 ,而对应的八进制数为 (36.2)8 。为了便于讲解,我需要将对应的二进制数作如下调整: (011−−−,110−−−.010−−−)2 (即在整数的最高位和小数的末尾都分别加了一个“0”)。看到这里,不知道聪明的你有没有发现什么神奇的地方:011、110、010分别对应了3、6、2。你也许会觉得这可能是偶然,但我告诉你,这不是偶然,恰恰是因为2的3次方刚好等于8导致的。也就是说,如果要将一个二进制数转换成八进制,我们只需要以小数点为起始点,往左和往右,每三位划分为一组(最后不足三位的用0补足),然后在组内将二进制分别转换成八进制,并将转换后的结果顺序排列即可。反过来,将八进制转换为二进制就是将八进制数的每一位转换为三位的二进制,再将转换后的结果顺序排列即可。
2.6.5 二-十六转换
我们知道,2的4次方恰好等于16。所以如果你能很好地理解二进制和八进制之间的相互转换,那么你也能很好地理解二进制和十六进制之间的相互转换。类似地,如果要将一个二进制数转换成十六进制,我们需要以小数点为起点,往左和往右,每四位划分为一组(最后不足四位的用0补足),然后在组内将二进制分别转换成十六进制,并将转换后的结果顺序排列即可。反过来,将十六进制转换为二进制就是将十六进制数的每一位转换为四位的二进制,再将转换后的结果顺序排列即可。
为了进一步巩固二进制和十六进制的转换,本文再举一个例子: (30.25)10 对应的二进制数为 (11110−−−−.0100−−−−)2 ,而对应的十六进制数为 (1E.4)16 。可以看到,以四位为一组,即可以实现二进制和十六进制的相互转换。
2.7 浮点数的存储
在2.3.4小节,我们介绍了整数是以二进制补码的形式存储的。而为了便于计算机进行四则运算,浮点数则采用了完全不同的存储方式,同时浮点数的四则运算也与整数运算大不相同。本小节先介绍浮点数在计算机中的存储方式,下一小节介绍浮点数的四则运算。
在介绍浮点数的存储方式之前,我们还需要先了解科学计数法。以 (123.45)10 为例,该浮点数用科学计数法可以表示为 (1.2345×102)10 或者 (0.12345×103)10 。浮点数在计算机中就是用科学计数法来表示的。因为通过科学计数法,不同大小的浮点数可以有统一的表示方式。不过,由于计算机采用二进制,所以,在计算机中使用的是二进制的科学计数法。例如, (−110.01)2 在计算机中可以表示为 (−1−.1001−−−−×22)2 ,其中小数点后面的“1001”被称为尾数,而上标“2”被称为指数或阶数,小数点左边的“1”被称为“附加位”(又叫整数位),“-”则为符号标志,表示这是个负数。当然, (−110.01)2 还可以表示为 (−0−.11001−−−−×23)2 。对二进制来说,将任意一个二进制浮点数转换为整数位为1(类似 (−1−.1001−−−−×22)2 )或者为0(类似 (−0−.11001−−−−×23)2 )这两种特定表示的过程称为规格化。实际上,整数位为1和为0这两种表示分别对应了两种不同的规格化标准,本文中所有的例子都采用第一种规格化标准。
在计算机中,按照精度(精度越高,能表示的数越准确)的不同,浮点数又可以分为单精度(float)和双精度()两种,分别用32位和64位来表示(64位所表示的浮点数精度更高)。对于浮点数的存储,目前使用最广的是由IEEE 754定义的浮点数格式。在IEEE 754的定义中,一个浮点数由3部分组成:符号位、指数位(阶数位)和尾数位。以32位的单精度为例,符号位占1位,表示正负数,指数位占8位,尾数位占23位,即
图2-2 浮点数的格式
浮点数的取值则为 sflag∗a.m∗2e−127 。其中 sflag 表示符号,当s为0时, sflag 为1,当s为1时, sflag 为-1。e为指数位,用8位表示。a为附加位,其值取决于e:当e全为0时,a的值为0,否则a的值为1。m为尾数位。下面我们以一个实际的例子来认识浮点数在计算机中的存储方式。
假设计算机中存储了一个浮点数:“ 1−−−−−−−−−0−−−−−−−−−−−−−−−−−−−−− ”,由符号位我们知道,这个数为负数,即 sflag=−1 ;指数位为“”,转换成十进制为129,即 e=129 ;由于指数e不为零,所以其附加位 a=1 ;尾数 m=011 。综合起来,该浮点数为: −1×1.011×2129−127=(−5.5)10 。
题外话:到此,我们已经知道,当指数位全部为零时,附加位为0,否则附加位为1。也就是说,用于存储浮点数的这32位中,并不包含附加位,附加位是推断出来的。这样做的好处也是显然的:能够表示的浮点数精度提高了一位。由此我们不得不再次叹服:这帮搞计算机的就是想着法儿地“压榨”计算机,尽可能地利用计算机有限的资源来达到更高的目标。
2.8 浮点数的四则运算
在上一小节我们介绍了单精度的浮点数是用32位来存储的,那么它能表示的最大的浮点数是“ 1−−−−−−−−−1−−−−−−−−−−−−−−−−−−−−− ”,能表示的最小正浮点数是“ 0−−−−−−−−−1−−−−−−−−−−−−−−−−−−−−− ”,超过这个范围的浮点数是无法用单精度来表示的。很显然,两个浮点数四则运算的结果很可能会超出单精度能表示的范围。实际上,浮点数的四则运算需要考虑两种情况:溢出(两个很大的浮点数相加)和精度丢失(一个很大的浮点数和一个很小的浮点数相加)。下面分别介绍浮点数的加减运算和乘除运算。
2.8.1 浮点数的加/减法
由于浮点数是用科学计数法存储的,当两个浮点数的阶数不同时,尾数部分(这里的尾数包含了附加位)无法直接进行加减运算。所以对两个浮点数做加减运算的第一步就是调整阶数。浮点数的加减运算包含五个步骤:对阶、尾数求和/求差、规格化、舍入和溢出判断。由于减法运算可以通过补码转换成加法运算,所以下面仅以 (1.011×22)2 和 (1.11,000,000,000,000,000,000,001×21)2 相加为例来介绍上述五个步骤。
第一步:对阶。小阶向大阶看齐。
这一步需要将 (1.11,000,000,000,000,000,000,001×21)2 的阶数转换成2。转换后该数就变成了 (0.111,000,000,000,000,000,000,001×22)2 。前面已经说了,尾数只占23位,而此次转换后的尾数有24位,超出了计算机的存储范围。对于这种情况,计算机会直接将尾数第23位以后的所有数码全部丢弃。最终,此次对阶操作的结果为 (0.11,100,000,000,000,000,000,000×22)2 。
第二步:尾数求和。由于我们这里采用了附加位,所以这里的尾数求和需要带附加位。
(1.011×22)2 的尾数带附加位后为1.011, (0.11,100,000,000,000,000,000,000×22)2 的尾数带附加位后为0.11,100,000,000,000,000,000,000,所以带附加位的尾数求和的结果为10.01,000,000,000,000,000,000,000。
第三步:规格化。规格化又分为左规和右规。左规时尾数左移一位,阶码减一,直到符合补码的规格化表示为止;右规时尾数右移一位,阶码加一,直到符合补码的规格化表示为止。
截止到第二步,我们得到的结果为 (10.01,000,000,000,000,000,000,000×22)2 ,将其左规后就变成了 (1.001,000,000,000,000,000,000,000×23)2 。
第四步:舍入。
第一步的对阶和第三步的规格化操作都会涉及到尾数的移位,移位就可能导致数码丢失。在本例中的第一步就出现了尾数的丢失而对精度造成影响。舍入操作就是用来提高尾数的精度。常用的舍入法有“截断处理”和“0舍1入”。其中截断处理就是直接丢掉正常尾数最低位之后的全部数码;0舍1入则类似于十进制的“四舍五入”,即在右移时,被舍弃的最高位如果是“1”,则在尾数的末位加1,否则不加。这样做可能使尾数又溢出,此时需要再做一次规格化。
在本例中,如果我们采用0舍1入,则由于在第一步对阶时,被舍弃的最高位为“1”,所以需要在求和结果的尾数末位再加1,最终的结果即为 (1.001,000,000,000,000,000,000,001×23)2 。
第五步:溢出判断。
溢出实际上包含上溢和下溢。下溢是指运算结果的绝对值趋于零,而且超出了计算机能表示的最小正数;上溢是指运算结果的绝对值非常大,超出了计算机能表示的最大的正数。对于下溢,计算机通常会直接将运算结果记为零,而对于上溢,计算机会停止运算,并作溢出中断处理。本例中并没有溢出,所以计算机会直接返回运算的最终结果 (1.001,000,000,000,000,000,000,001×23)2 。
2.8.2 浮点数的乘/除法
在理解了浮点数加减运算的原理之后,再来看浮点数的乘除法就会容易很多。与加减运算类似,乘除运算同样涉及尾数运算、规格化、舍入和溢出判断等操作。不过,由于除法运算的除数不能为0,所以与加减运算相比,乘除运算多了一步预处理。另外,加减运算中的对阶在乘除运算中变成了阶码运算。下面依次对这五个步骤进行介绍。
第一步:预处理。
对于乘法运算,检测两个尾数中是否有一个为0,若有,则乘积必为0,不再做其它操作;如果两个尾数均不为0,则可进行乘法运算。对于除法运算,如果被除数的尾数为0,则商为0,不再做其它操作;如果除数的尾数为0,则商为无穷大,通常会返回异常;如果两个尾数都不为0,则可进行除法运算。
第二步:阶码运算。
对于乘法运算,则是将两个阶码值相加;对于除法运算,则是直接将两个阶码相减。阶码的加减运算规则参见2.3.3小节。当然,由前面介绍的知识可知,阶码占8位,能表示的范围是0~255(这里的最高位不是符号位),而两个阶码相加或者相减有可能会超出这个范围。超出这个范围则称为阶码溢出。阶码溢出同样分为上溢(大于255)和下溢(小于0),对于下溢,则说明此次运算的最终结果的指数值小于-127(一个负数减去127肯定小于-127),这样的结果和0非常地接近。所以对于下溢,计算机通常会直接将整个运算结果记为0并返回;对于上溢,计算机会停止运算,并作溢出中断处理。如果阶码运算并未溢出,则进行下一步运算。
第三步:尾数运算。
浮点数尾数的乘除运算规则参见2.3.3小节。
第四步:规格化。
对于尾数相乘的结果可能要进行左规,左规时调整阶码后如果发生阶码下溢,则计算机将整个运算结果记为0并返回;如果发生阶码上溢,则做溢出中断处理。对于尾数的除法运算,为了防止除法结果溢出,一般是先比较被除数和除数的绝对值,如果被除数的绝对值小于除数的绝对值,则先将被除数左移一位,其阶码减1,再做尾数相除。此时所得的结果必然是规格化的定点小数,原因请自行分析。
第四步,舍入。
尾数相乘会得到一个双倍字长的结果,而尾数相除也有可能因为除不尽而导致结果超出限制。舍入的方法同样有截断处理和0舍1入。其中0舍1入同样有可能造成尾数再次溢出,需要再次规格化。
第五步,溢出判断。
参见2.8.1小节中的溢出判断。
2.9 一切皆01
到这里,二进制的相关知识基本上就介绍完了。最后,再补充强调一点:在计算机内部,一切皆01。也就是说,存储在计算机内部(不管是内存还是硬盘)所有的文字、图片、视频和声音,实际上都只是多个0和1的排列组合。看到这里大家可能会有这样的疑惑:用01串来表示数字现在已经可以理解了,但用01串表示文字、图片、视频和声音该怎么理解呢?为了让大家对此有更深刻的认识,我们需要讨论两个问题:第一,计算机为什么要用01串来表示文字、图片、视频和声音;第二,计算机如何用01串来表示文字、图片、视频和声音。
首先回答第一个问题。其实,与其解释计算机为什么要用01串来表示文字、图片、视频和声音,不如直接回答说计算机确实只能存储01串。我们都知道,计算机是靠电力驱动的。在2.3.1小节我们介绍了计算机内存使用以晶体管为主要元件的基本电路单元来代表0和1,而实际上内存只不过是大量基本电路单元的集成,所以内存只能存储01串。计算机的其它组成硬件也都类似。因而计算机确实只能存储01串。
在理解了第一个问题之后,第二个问题就等同于如何将文字、图片、视频和声音转换成01串。我们首先来看文字。以“汉”字为例,图2-3的左边模拟了一个16×16的点阵图,图中的每个小方格代表一个像素点(真实的显示器即是由大量的像素点紧密排列而成的矩形,真实的像素点非常小),图的右边即为左图对应的位码图。位码为“1”则代表该像素点为黑色,为“0”则为白色。在这幅图中,如果我们将位码图按行每8位取为一个字节,那么总共可以取32个字节。这32个字节就唯一地代表了“汉”这个字。不同的汉字用同样的方法将得到不完全相同的32个字节。这32个字节就称为字形码。在计算机中,我们将常用汉字的字形码按照一定的次序保存到一个专门的文件里,当需要显示某个汉字时,直接到该文件中调用该汉字的字形码来控制显示器的显示就可以了。在UCDOS和CCDOS中,存储常用汉字字形码的文件名为HZK16。
图2-3 “汉”字及位码图
当然,字形码只解决了汉字的显示问题,而在我们自己编辑的文件中是不可能直接存储汉字的字形码的,因为那样太浪费资源了(一个字形码占32个字节)。刚刚已经说了,我们是将字形码按照一定的次序保存到HZK16里的,那么每个字形码都会有一个唯一的序号。通过这个序号,我们就可以唯一地确定一个汉字。在具体的实现中,这个序号又被称为 区位码,因为HZK16就是用区位码的方式对汉字进行排序并存储的。那么什么叫区位码呢?在学校上体育课时,老师通常会让同学们集合,而同学们通常会站成几排,每一排和每一列都要对齐。老师通常还会要求每一排的同学从左到右依次报数。如果将每个同学当成一个汉字的话,那么每一行的行号减1(计算机都是从0开始计数的)就称为 区号,而每个同学报的数减1即为 位号。所谓的“区位码”,就由这里的区号和位号构成。例如,在-80代码表中,一共有94行,每行有94列,即一共有94个区,每个区有94个汉字。我们将区号和位号分别用两位的十进制表示,不足两位的前面补0。这样每个汉字都可以用一个4位的十进制数表示,这个十进制数这就是区位码。
那么我们自己编辑的文件中的汉字在存储时存的是区位码吗?很遗憾,也不是。我们存储在计算机中的实际上是 机内码(顾名思义,机内码就是指存储在计算机内部的编码)。不过机内码和区位码之间存在一一对应的关系: 机内码=区位码+A0A0H(A0A0H表示十六进制数,参见2.5小节)。到此,我们理解了计算机存储汉字的原理,对于其他国家的文字,其原理也是相似的。
题外话(看不懂也没关系):你可能会好奇计算机为什么不直接存储区位码,而是存储机内码,这是有历史原因的。我们知道,计算机最早由美国人发明,而美国的语言是英语。由于所有的英语单词都可以由26个字母来构成,所以美国人在发明计算机时设计了一种编码方式ASCII,这种编码方式就是将需要用到的控制符号、标点符号、数字0~9以及26个英文字母(分大小写)和0~127一一对应起来。由于英语需要表示的字符数量很少,所以ASCII编码只需要一个字节就够了(一个字节在最高位不表示符号的情况下最大值为255)。实际上,ASCII就是英文字符对应的机内码。但汉字不同,由于汉字的数量众多,用一个字节无法区分,因此国家标准局采用两个字节来存放一个汉字的内码,称为 国标码。国标码的每个汉字对应的两个字节的最高位均为0,而查ASCII编码表可知,每个字符对应的二进制的最高位也为0。这就容易引起歧义:当出现两个最高位都为0的字节时,不知道这是对应一个汉字还是对应两个英文字符。为了解决这个问题,将国标码的每个字节的最高位置为1,就得到机内码。将两个字节每个字节的最高位置为1等价于加上 (,)2 ,转换成十六进制就是8080H,即 机内码=国标码+8080H。另外,由于ASCII的前32个字符都是控制字符,国标码为了避免与ASCII的控制字符相冲突,于是在区位码的基础上加上32,即20H。也就是说,国标码和区位码之间存在如下关系: 国标码=区位码+2020H。到此,由机内码与国标码之间的关系以及国标码与区位码之间的关系可以最终推导出机内码和区位码之间的关系: 机内码=区位码+A0A0H。
说完了文字,我们接着来说图片。一幅数字图像实际上是由一个个像素点紧挨着排列而成的一个矩形。由于像素点非常小,所以肉眼看起来就是一幅完整的画,而不是一个个孤立的像素点。对色彩学有所了解的都知道,肉眼能看到的颜色可以用红、绿、蓝这三种基色来合成。而这三种基色都是可以用数字进行量化的。以红色为例,红色的取值范围为0到255,数字越大则看起来越红。那么,在计算机中,我们只需要存储每个像素点对应的三基色值就可以了。当需要打开这幅图片时,计算机会将每个像素点对应的三基色值读出来交给显卡,由显卡来完成图片的最终展示。
我们再来说说声音的存储。声音的存储涉及到话筒及音响的原理。实际上,话筒和音响的原理是一样的。话筒里边有一层对空气振动非常敏感的薄膜,在这层膜上粘着线圈,线圈的外面是磁铁。当人对着话筒说话时,会引起话筒周围的空气振动,空气振动会带动话筒里的薄膜也跟着振动,薄膜上粘着的线圈也就运动起来。在高中物理课上我们学过法拉第的电磁感应现象:线圈在运动时如果切割了磁感线就会产生电流,而且如果线圈切割磁感线的方向相反,产生的电流方向也相反。随着薄膜的来回振动,线圈也会来回地切割磁感线,从而交替地产生正向电流和反向电流。正向电流的大小为正数,反向电流的大小为负数。声卡每隔约0.023(1/44)秒检查一次电流的方向和大小,并将该值存储在计算机中。当需要播放这段声音时,计算机首先将这些数字读取出来交给声卡,声卡用这些数字在线圈中产生对应的电流。由于线圈外面有磁铁,电磁感应会使得线圈产生运动,线圈的运动会带动薄膜的运动,薄膜的运动又会引起空气的振动,最终就成了传到我们耳朵的声音。以上只是介绍了话筒和音响的核心原理,真实的话筒和音响并非这么简单,比如空气振动产生的电流实际上很小,需要进行放大处理。
我们已经懂得了图片和声音的存储原理,那么视频的存储就很好理解了:视频实际上是多张图片以及一段声音的集合。到此我们相信,在计算机内部存储的确实都只是0和1而已。
2.10 本章小结
本章主要介绍了二进制的相关知识,包括计算机为什么采用二进制,二进制的源码、反码及补码的表示,二进制的四则运算,二进制和八进制、十进制、十六进制的相互转换,浮点数的存储原理和四则运算,最后介绍了计算机如何存储文字、图片、视频和声音。通过本章的学习,我们不仅认识了二进制,还知道了计算机内部的存储原理,从而为进一步深入了解计算机打下基础。
完结。
原创不易,如果你觉得本文对你有帮助,希望你能支持一下~