用Python获取可能是全网最全的杰尼龟表情包(第一弹)
这些流传的表情包无非就是截取自动画片《精灵宝可梦》,然后有选择性地缩放或是剪切图片,再对应图片加上相关的文字。因此按照这个逻辑,我们需要首先在这视频上做文章。
作为第一代御三家的一员,杰尼龟主要活跃在《精灵宝可梦》的第一部无印篇,因而我们仅需要考虑第一部的视频,而这第一部中,不乏一些杰尼龟专集。
直接下载这第一部的视频费时费力,恰好B站有up主上传了所有含杰尼龟的集数合集,这里偷个小懒,我直接采用了@写得非常棒的B站视频爬虫将该专辑合集的所有视频下载到本地。
视频切割
既然已经将所有视频下载,接下来便可以利用将每个视频切割为图片。这里fps便是帧率,意为每一秒刷新的图片数量,则是一整段视频中总的图片数量。
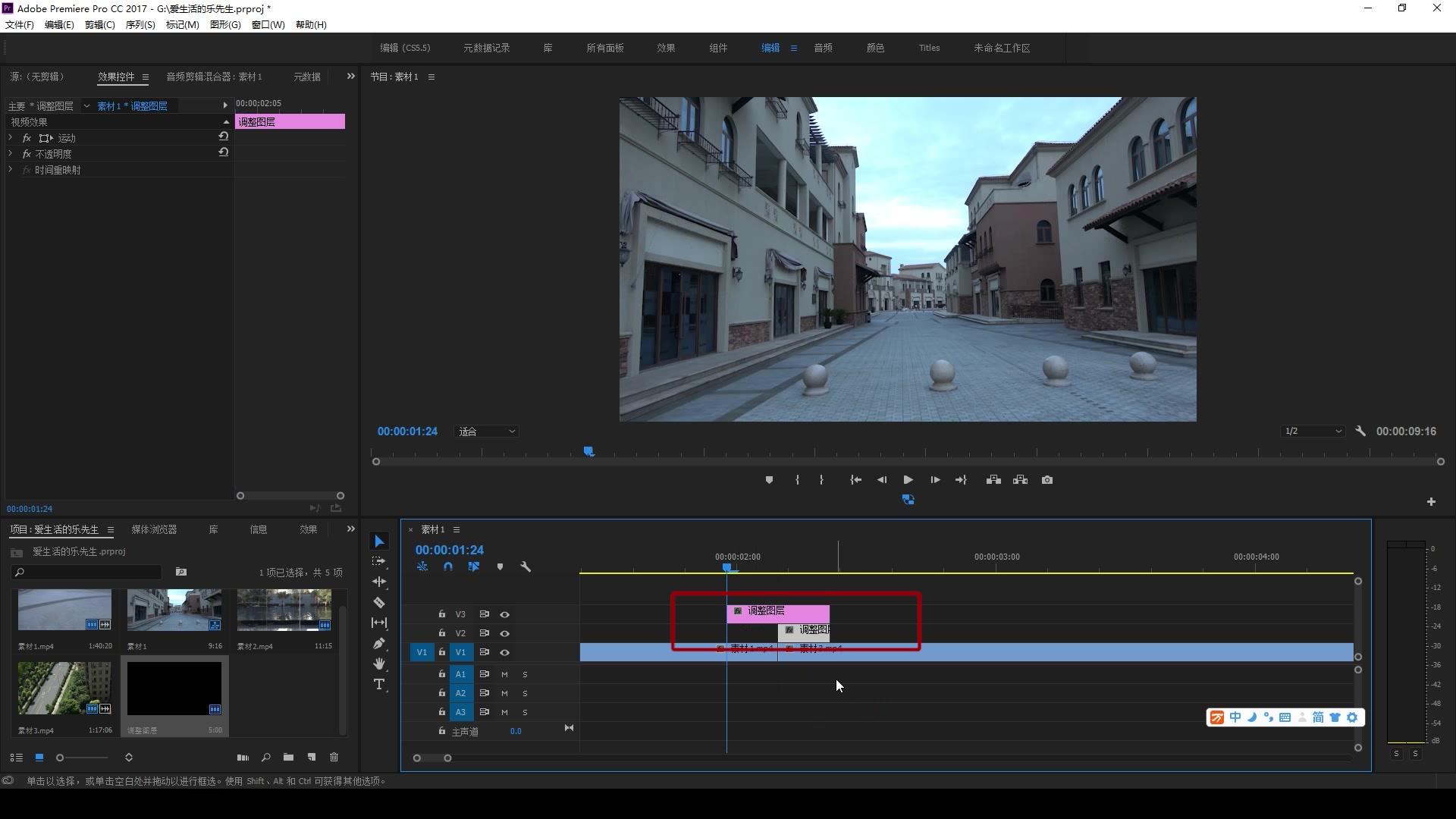
def vedio_to_pic(path):vedio_path=os.listdir(path)count=0for vedio in vedio_path: videoCapture=cv2.VideoCapture()videoCapture.open(os.path.join(path,vedio,vedio+'.flv'))fps=videoCapture.get(cv2.CAP_PROP_FPS)frames = videoCapture.get(cv2.CAP_PROP_FRAME_COUNT) print("fps=",fps,"frames=",frames)for i in range(int(frames)):ret,frame=videoCapture.read()if ret:if i%int(fps/5)==0: cv2.imwrite("pic/jieni{}_{}.jpg".format(count+1,i),frame)count+=1这里每一帧仅保存1/5的图片,因为每一帧内的图片较为相似,帧内所有图片获取存在较大的冗余。
至此,我们便拥有了海量可能包含杰尼龟的图片,下一弹便来讲讲如何使用机器学习来帮助我们筛选那些包含杰尼龟的图片!