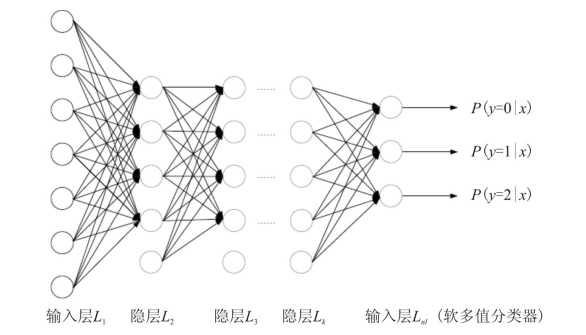
CVPR2020:Learning in the Frequency Domai
图像分析新方法:“频域学习”( in the )
就是省略图像压缩/解压缩中计算量最大的步骤,直接利用频域特征来进行图像推理,减少系统中模块之间的数据传输量,从而提升系统性能。输入的数据量更小,深度神经网络在图像分类/分割任务上的精度反而提升了。
论文地址:
摘要:
DNN在计算机视觉任务中取得了显著的成功。现有的神经网络主要在固定输入尺寸的空间域内运行。在实际应用中,图像通常很大,必须向下采样到预定的神经网络输入大小。尽管下采样减少了计算量和所需的通信带宽,但它同时在不影响冗余和显著信息的前提下消除了冗余和显著信息,从而导致精度下降。受数字信号处理的启发,从频率的角度分析了频谱偏差 bias,提出了一种基于学习的频率选择方法来识别可以在不损失精度的情况下去除的琐碎频率分量 。提出的频域学习方法利用众所周知的神经网络的相同结构,如-50、和Mask R-CNN,并输入获取的频域信息。
实验结果表明,与传统的下采样方法相比,基于静态信道选择 的频域学习方法可以获得更高的精度,同时进一步减小了输入数据的大小。针对相同输入大小的分类,分别在-50和上实现了1.41%和0.66%的top-1精度改进。即使只有一半的输入大小,该方法仍然可以将-50的前1位精度提高1%。此外,我们还观察到,在COCO数据集的实例分割方面,Mask R-CNN的平均精度提高了0.8%。
1.介绍
CNN在图像分类、目标检测、语义分割等各种任务上的优异表现,使计算机视觉领域发生了革命性的变化。由于计算资源和内存的限制,大多数CNN模型只接受低分辨率的RGB图像(如224×224)。然而,现代相机拍摄的图像通常要大得多。例如,高清晰度(HD)分辨率图像(1920×1080)被认为是相对较小的现代标准。即使是数据集的平均图像分辨率也是482×415,这大约是大多数CNN模型所能接受的尺寸的四倍。
因此,为了满足分类网络的输入要求,大量的真实图像被压缩到224×224。然而,图像的缩小不可避免地会带来信息的丢失和精度的下降。先前的工作旨在通过学习任务感知的缩小网络来减少信息损失。然而,这些网络是特定于任务的,需要额外的计算,这在实际应用中是不利的。
在本文中,我们提出在频域内对高分辨率图像进行,而不是在空间域对其进行调整,然后将重新调整后的DCT系数输入CNN模型进行推理。我们的方法需要对现有的以RGB图像为输入的CNN模型进行少许修改。因此,它是常规数据预处理通道的通用替代品。实验结果表明,与传统的基于RGB的方法相比,该方法在图像分类、目标检测和实例分割等方面具有更高的精度。在AI加速器/ gpu快速发展的情况下,该方法直接降低了所需的片间通信带宽inter-chip ,而片间通信带宽是现代深度学习推理系统的瓶颈,如图1所示。
(a)使用RGB图像作为输入的传统的基于CNN的方法的工作流程。
(b)采用DCT系数作为输入的方法的工作流程。CB表示CPU和GPU/加速器之间所需的通信带宽。
受人类视觉系统(HVS)对不同频率分量的不平等敏感性这一观察结果的启发,我们分析了频域内的图像分类、检测和分割任务,发现CNN模型对低频信道的敏感性高于高频信道,其与HVS重合。
这一观察结果通过一个基于学习的通道选择方法得到验证,该方法由多个“开关”组成。将具有相同频率的DCT系数打包成一个通道,每个开关堆叠在一个特定的频率通道上,以允许整个通道流入或不流入网络。
利用解码后的高保真图像进行模型训练和推理,在数据传输和计算方面都面临着巨大的挑战。由于CNN模型的频谱偏倚 bias,在推理过程中只能保留重要的频率信道,而不会丢失准确性。在这篇论文中,我们也发展了一种静态的信道选择方法来保留显著的信道,而不是使用整个频谱来进行推断。实验结果表明,当输入数据量减少87.5%时,CNN模型仍然保持相同的精度。
1.我们提出了一种系统方法可以在基本不改变现有的卷积神经网络(如,等)的前提下做基于频域的机器识别。2.由于基于频域的机器识别可以在不增加计算量的前提下,接受空间域尺寸更大的图片,因此提高了图像识别的精度。3.我们从频率的角度分析了频谱偏差,发现CNN模型对低频频道比对高频频道更敏感,类似于人类视觉系统(HVS)。4.我们提出了一种基于学习的动态信道选择方法来识别琐碎的频率成分,以便在推理过程中进行静态去除。在-50上的实验结果表明,在分类任务中,使用所提出的信道选择方法,在不降低或几乎不降低精度的情况下,可以修剪高达87.5%的频率信道。5.之前基于频域的机器学习只完成了单一物体的图像分类 ( ),我们首次将基于频域的机器学习扩展到了图像的物体检测( )和语义/实例分割( )任务中,通常物体检测和语义/实例分割被定义为高级视觉(High level ) 任务。
2.相关工作
频域学习:频域压缩表示包含丰富的图像理解任务模式。[14,15,16]联合训练专用的基于自动编码器的网络进行压缩和推理任务。[17]从频域提取特征对图像进行分类。[18]提出了一种模型转换算法,将空间域CNN模型转换为频域。我们的方法与以往的方法有两个不同之处。首先,我们避免了从空间到频域的复杂模型转换过程。因此,我们的方法具有更广阔的应用范围。其次,我们提供了一种分析方法来解释神经网络在频域上的频谱偏差。
动态神经网络:前人的研究[19,20,21,22,23]提出了基于对卷积块的激活来动态地选择性地跳过卷积块。这些工作根据每个卷积块的输入来调整模型的复杂度。在推理阶段,只计算与输入最相关的中间特征,以减少计算成本。相比之下,我们的方法只对原始输入进行操作,并提取显著的频率成分,以降低输入数据的通信带宽要求。
高效网络训练:近年来,人们对高效网络的训练产生了浓厚的兴趣[24,25,26,27],主要关注通过核剪枝、学习量化和熵编码 , , and 进行网络压缩。另一项工作是在频域内对CNN模型进行压缩。[28]通过将过滤器权值转换为频域并使用哈希函数将频率参数分组到哈希桶中来减少存储空间。[29]还将内核转换为频域,并抛弃了低能量的频域系数来进行高压缩。[30]限制了CNN内核的频谱以减少内存消耗。这些网络压缩工作在频域都依赖于基于FFT的卷积,在较大的内核上通常更有效。然而,最先进的CNN模型使用小内核,如3×3或1×1。需要付出大量的努力来优化这些基于FFT的CNN模型[31]的计算效率。相比之下,我们的方法对现有的CNN模型的修改很少。因此,我们的方法不需要额外的努力来提高它在小核CNN模型上的计算效率。另一个基本的区别是,我们的方法的目标是减少输入数据的大小,而不是减少模型的复杂性。