论文笔记——Deep Residual Learning for Image R
论文地址:Deep for Image
——MSRA何凯明团队的 ,在2015年上大放异彩,在的、、以及COCO的和上均斩获了第一名的成绩,而且Deep for Image 也获得了的best paper,实在是实至名归。就让我们来观摩大神的这篇上乘之作。
最根本的动机就是所谓的“退化”问题,即当模型的层次加深时,错误率却提高了,如下图:

但是模型的深度加深,学习能力增强,因此更深的模型不应当产生比它更浅的模型更高的错误率。而这个“退化”问题产生的原因归结于优化难题,当模型变复杂时,SGD的优化变得更加困难,导致了模型达不到好的学习效果。
针对这个问题,作者提出了一个的结构:
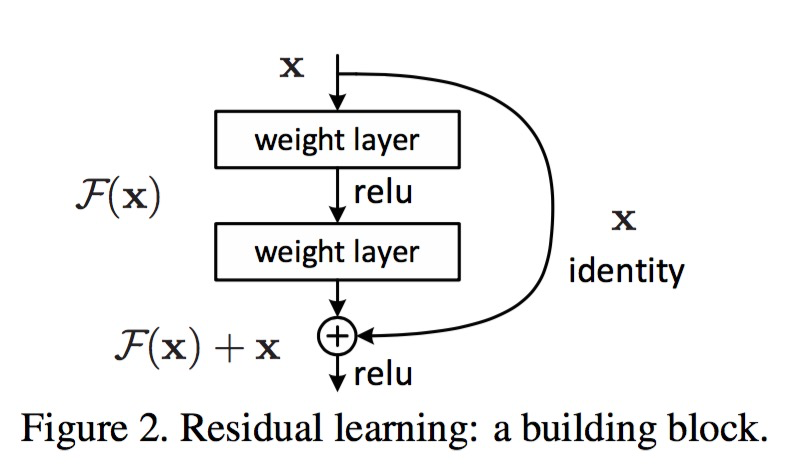
即增加一个 (恒等映射),将原始所需要学的函数H(x)转换成F(x)+x,而作者认为这两种表达的效果相同,但是优化的难度却并不相同,作者假设F(x)的优化 会比H(x)简单的多。这一想法也是源于图像处理中的残差向量编码,通过一个,将一个问题分解成多个尺度直接的残差问题,能够很好的起到优化训练的效果。
这个 block通过 实现,通过将这个block的输入和输出进行一个-wise的加叠,这个简单的加法并不会给网络增加额外的参数和计算量,同时却可以大大增加模型的训练速度、提高训练效果,并且当模型的层数加深时,这个简单的结构能够很好的解决退化问题。
接下来,作者就设计实验来证明自己的观点。
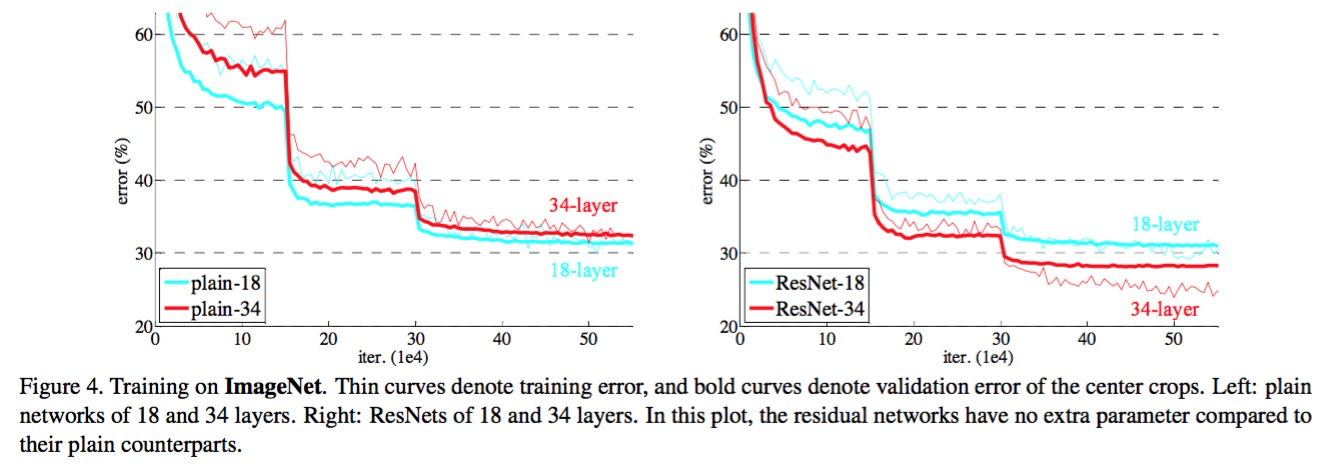
首先构建了一个18层和一个34层的plain网络,即将所有层进行简单的铺叠,然后构建了一个18层和一个34层的网络,仅仅是在plain上插入了,而且这两个网络的参数量、计算量相同,并且和之前有很好效果的VGG-19相比,计算量要小很多。(36亿FLOPs VS 196亿FLOPs,FLOPs即每秒浮点运算次数。)这也是作者反复强调的地方,也是这个模型最大的优势所在。
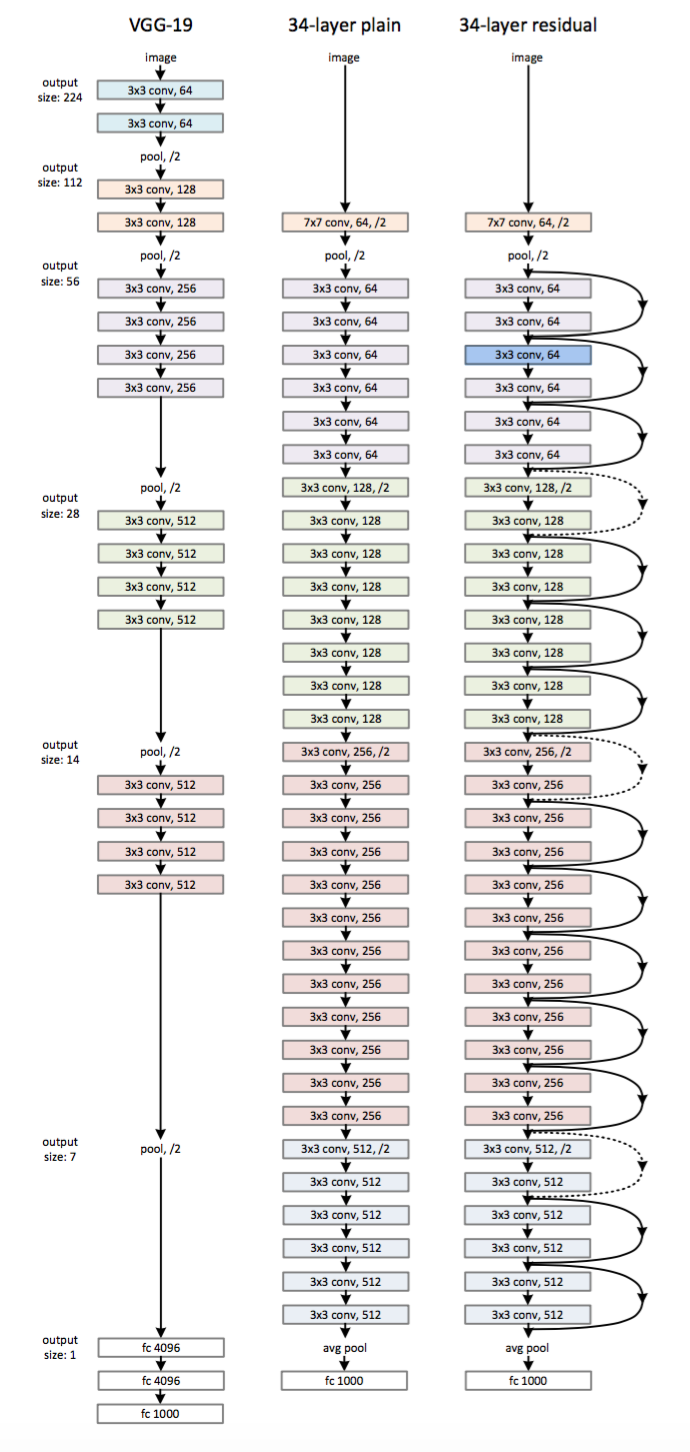
模型构建好后进行实验,在plain上观测到明显的退化现象,而且上不仅没有退化,34层网络的效果反而比18层的更好,而且不仅如此,的收敛速度比plain的要快得多。
对于的方式,作者提出了三个选项:
A. 使用恒等映射,如果 block的输入输出维度不一致,对增加的维度用0来填充;
B. 在block输入输出维度一致时使用恒等映射,不一致时使用线性投影以保证维度一致;
C. 对于所有的block均使用线性投影。
对这三个选项都进行了实验,发现虽然C的效果好于B的效果好于A的效果,但是差距很小,因此线性投影并不是必需的,而使用0填充时,可以保证模型的复杂度最低,这对于更深的网络是更加有利的。
进一步实验,作者又提出了的 block:
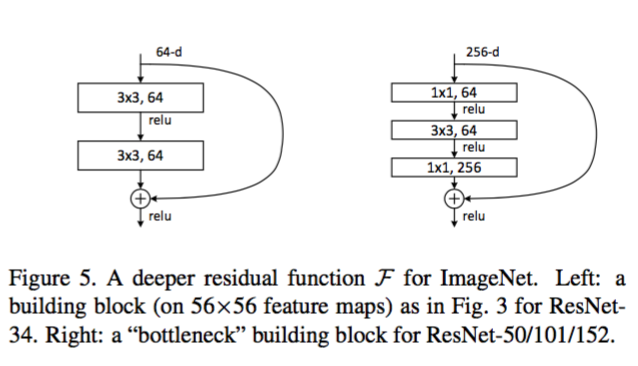
这相当于对于相同数量的层又减少了参数量,因此可以拓展成更深的模型。于是作者提出了50、101、152层的,而且不仅没有出现退化问题,错误率也大大降低,同时计算复杂度也保持在很低的程度。
这个时候的错误率已经把其他网络落下几条街了,但是似乎还并不满足,于是又搭建了更加变态的1202层的网络,对于这么深的网络,优化依然并不困难,但是出现了过拟合的问题,这是很正常的,作者也说了以后会对这个1202层的模型进行进一步的改进。(想想就可怕。)
在文章的附录部分,作者又针对在其他几个任务的应用进行了解释,毕竟获得了第一名的成绩,也证明了强大的泛化能力,感兴趣的同学可以好好研究这篇论文,是非常有学习价值的。
转至: