pytorch头脑风暴20220315:cell选择器,任务失败
头脑风暴:cell选择器,任务失败
一层+cell选择器任务失败:
loss加入 第二层方差(差异越大越好)、第二层权重相似度(不相似) 第1个epoch测试集精度72% ;
一层+cell选择器有个根本问题: 选择器的输出尺寸始终是cell的个数 而不是分类个数 所以无法把选择器的输出当成分类概率分布
.py
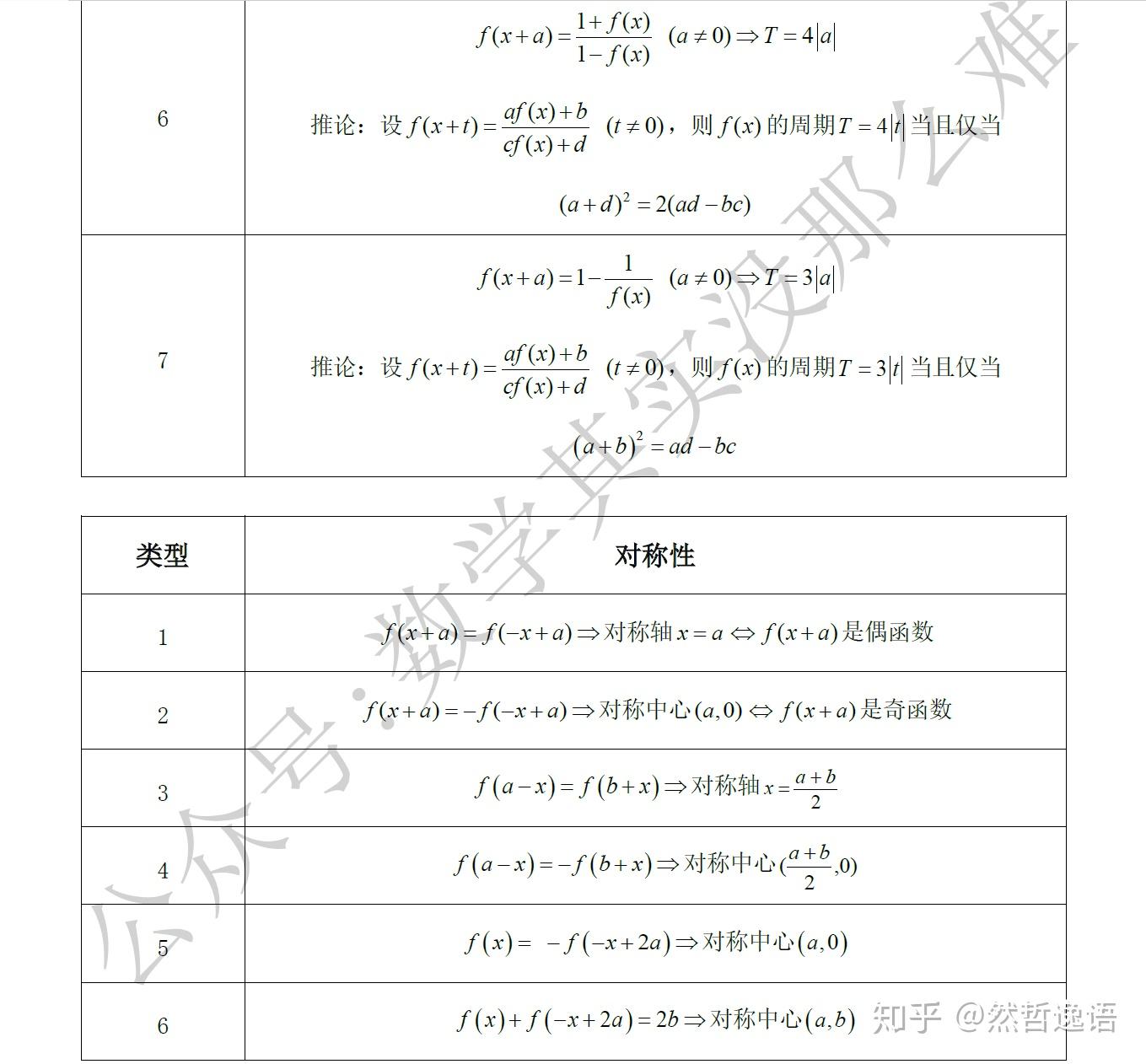
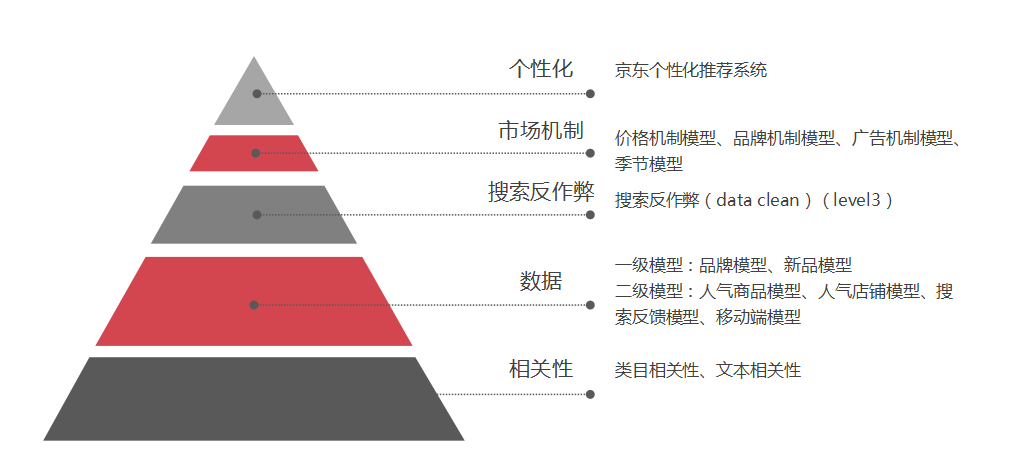
#mnist_shape_size.py
class MnistDim:_TRAIN_SAMPLE_CNT = 60000PIC_H = 28PIC_W = 28_TEST_SAMPLE_CNT = 10000PIC_HW = PIC_H * PIC_WCELL_H=4CELL_W = 4CELL_HW=CELL_W*CELL_HCELL_CNT_H=int(PIC_H/CELL_H) #7CELL_CNT_W=int(PIC_W/CELL_W) #7LV1_FC_O_SZ=3NEB_SZ=4 #NEIGHBOR_SIZE:邻居尺寸, 比如 左右上下四个小格子 合成 上一层的一个小格子, 左右上下四个小格子 共4个小格子 故邻居尺寸为4LV2_IN_SZ = LV1_FC_O_SZ * NEB_SZLV2_FC_O_SZ = 3#6# LV2_CELL_CNT_H=int((CELL_CNT_H+1)/2)# LV2_CELL_CNT_W =int((CELL_CNT_H+1)/2)CLSFY_FC_IN_SZ= NEB_SZ * LV2_FC_O_SZ#4*6args.py
#args.pyclass Args:def __init__(self):self.epochs = 30self.lr = 4.0self.gamma = 0.9self.seed = 1self.log_interval = 100self.save_model = Truedef update(self, d):self.__dict__.update(d.__dict__)class TrainArgs(Args):def __init__(self):Args.__init__(self)self.batch_size = 100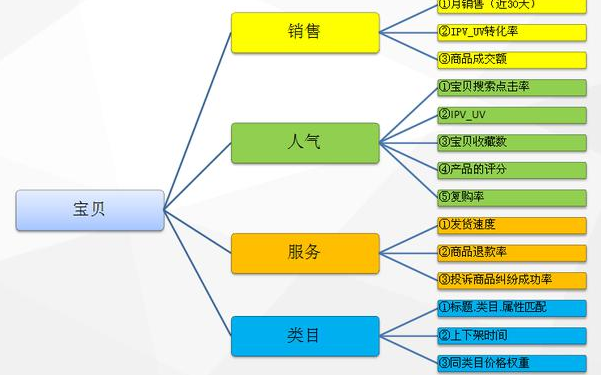
.py
#mnist_example.py
from typing import Listimport plotly.express
import plotly.graph_objects
import plotly.subplots
from torch.nn.parameter import Parameter
from torch.optim.adadelta import Adadeltafrom mnist_shape_size import MnistDim
from run_plotly_dash_web_server_in_new_thread import runPlotlyDashWebServerInNewThread_TRAIN_SAMPLE_CNT,PIC_H,PIC_W=None,None,None
_TRAIN_SAMPLE_CNT=MnistDim._TRAIN_SAMPLE_CNT
PIC_H=MnistDim.PIC_H
PIC_W=MnistDim.PIC_W
_TEST_SAMPLE_CNT=MnistDim._TEST_SAMPLE_CNT
PIC_HW=MnistDim.PIC_HW
#PIC_H==28;PIC_W==28;PIC_HW==28*28LINEAR_1_OUT_SIZE=64
R_LINEAR_1_OUT_SIZE=LINEAR_1_OUT_SIZE
CLASS_CNT=10import numpy
from load_mnist import loadMnistimport argparse
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.optim.lr_scheduler import StepLR
from args import Args,TrainArgsclass Net(nn.Module):"""简写约定:小格子:cell, (一个28*28的图片被分割成7*7个 4*4的小格子)层级:level:lv选择器:selector:sel分类器:classify:clsfy尺寸:size:sz输出:output:o激活:active:a, 经过非线性函数后的输出 称为 激活 或 激活值输入:input:in图片高度:高度:height:h图片宽度:宽度:width:w图片高度*图片宽度:height*width:HW:hw全连接:full connection:fcself.level*_fc*:lv*_fc*self.level1_selector:lv1_selself.classify_fc:clsfy_fcLV1_FC_O_SZ:LEVEL1_FC_OUTPUT_SIZE"""LV1_FC_CNT =5 #5:指代__init__中的5个self.lv1_fc*LV2_FC_CNT = 8 # 8:指代__init__中的5个self.lv2_fc*lv1_w_pair_cnt=int(LV1_FC_CNT * (LV1_FC_CNT - 1) / 2)lv2_w_pair_cnt=int(LV2_FC_CNT * (LV2_FC_CNT - 1) / 2)def __init__(self):super(Net, self).__init__()CELL_HW=MnistDim.CELL_HWCELL_H = MnistDim.CELL_HCELL_W = MnistDim.CELL_WCELL_CNT_H = MnistDim.CELL_CNT_HCELL_CNT_W = MnistDim.CELL_CNT_WLV1_FC_O_SZ = MnistDim.LV1_FC_O_SZNEB_SZ = MnistDim.NEB_SZLV2_IN_SZ = MnistDim.LV2_IN_SZLV2_FC_O_SZ = MnistDim.LV2_FC_O_SZCLSFY_FC_IN_SZ = MnistDim.CLSFY_FC_IN_SZself.lv1_sel=nn.Linear(CELL_HW, Net.LV1_FC_CNT)#(4*4, 5)# lv1_sel: 在以下5个lv1_fc*中选择哪一个self.lv1_fc1 = nn.Linear(CELL_HW, LV1_FC_O_SZ, bias=False)#(4*4, 2)self.lv1_fc2 = nn.Linear(CELL_HW, LV1_FC_O_SZ, bias=False)#(4*4, 2)self.lv1_fc3 = nn.Linear(CELL_HW, LV1_FC_O_SZ, bias=False)#(4*4, 2)self.lv1_fc4 = nn.Linear(CELL_HW, LV1_FC_O_SZ, bias=False)#(4*4, 2)self.lv1_fc5 = nn.Linear(CELL_HW, LV1_FC_O_SZ, bias=False)#(4*4, 2)self.lv1_fc = [self.lv1_fc1,self.lv1_fc2,self.lv1_fc3,self.lv1_fc4,self.lv1_fc5]#5个 (4*4, 2)self.clsfy_fc = nn.Linear(CLSFY_FC_IN_SZ, CLASS_CNT)#临时用的转到分类的fcself.lv2_sel=nn.Linear(LV2_IN_SZ, Net.LV2_FC_CNT)#(4*4, 5)# lv1_sel: 在以下8个lv2_fc*中选择哪一个self.lv2_fc1 = nn.Linear(LV2_IN_SZ, LV2_FC_O_SZ, bias=False)#(2+2+2+2, 6)self.lv2_fc2 = nn.Linear(LV2_IN_SZ, LV2_FC_O_SZ, bias=False)#(2+2+2+2, 6)self.lv2_fc3 = nn.Linear(LV2_IN_SZ, LV2_FC_O_SZ, bias=False)#(2+2+2+2, 6)self.lv2_fc4 = nn.Linear(LV2_IN_SZ, LV2_FC_O_SZ, bias=False)#(2+2+2+2, 6)self.lv2_fc5 = nn.Linear(LV2_IN_SZ, LV2_FC_O_SZ, bias=False)#(2+2+2+2, 6)self.lv2_fc6 = nn.Linear(LV2_IN_SZ, LV2_FC_O_SZ, bias=False)#(2+2+2+2, 6)self.lv2_fc7 = nn.Linear(LV2_IN_SZ, LV2_FC_O_SZ, bias=False)#(2+2+2+2, 6)self.lv2_fc8 = nn.Linear(LV2_IN_SZ, LV2_FC_O_SZ, bias=False)#(2+2+2+2, 6)self.lv2_fc = [self.lv2_fc1,self.lv2_fc2,self.lv2_fc3,self.lv2_fc4,self.lv2_fc5,self.lv2_fc6,self.lv2_fc7,self.lv2_fc8]#8个 ( 2)def forward(self, x:torch.Tensor):CELL_HW=MnistDim.CELL_HWCELL_H = MnistDim.CELL_HCELL_W = MnistDim.CELL_WCELL_CNT_H = MnistDim.CELL_CNT_HCELL_CNT_W = MnistDim.CELL_CNT_WNEB_SZ = MnistDim.NEB_SZHALF_NEB_SZ=int(NEB_SZ/2)LV1_FC_O_SZ = MnistDim.LV1_FC_O_SZLV2_FC_O_SZ = MnistDim.LV2_FC_O_SZbatch_size=x.shape[0]
# print(f"xxx:{x.shape}")
# plotly.express.imshow(x[0].reshape((PIC_H,PIC_W))).show()xflat:torch.Tensor=x.view(-1, PIC_HW)#(-1,28*28)xCell:torch.Tensor=torch.swapdims(input=x.reshape((-1, CELL_CNT_H,CELL_H, CELL_CNT_W,CELL_W)), dim0=2, dim1=3) #(0:-1, 1:7,2:4, 3:7,4:4)assert list(xCell.shape)[1:] == [CELL_CNT_H,CELL_CNT_W, CELL_H,CELL_W] #xCell.shape:7,7,4,4lv1_fc_selected_ls:List[torch.Tensor]=[]lv1_sel_a_stdVar_mean:torch.Tensor=torch.zeros((batch_size,))for h in range(CELL_CNT_H):#7for w in range(CELL_CNT_W):#7xCellhw:torch.Tensor=xCell[:,h,w]#xCell[:,0,0].shape:-1,4,4xCellhwFlat:torch.Tensor=xCellhw.reshape((-1,CELL_HW))#xCellhwFlat.shape:-1,4*4lv1_sel_o:torch.Tensor=self.lv1_sel(xCellhwFlat)#level1_selector_o.shape:-1,5lv1_sel_a:torch.Tensor=torch.softmax(lv1_sel_o,dim=1)#level1_selector_o.shape:: 0:-1, 1:5lv1_sel_a_stdVar:torch.Tensor=torch.std(input=lv1_sel_a,dim=1)lv1_sel_a_stdVar_mean=torch.add(input=lv1_sel_a_stdVar_mean,other=lv1_sel_a_stdVar)lv1_fc_o_ls:List[torch.Tensor]= [self.lv1_fc[i](xCellhwFlat) for i in range(Net.LV1_FC_CNT)]lv1_fcAll_o:torch.Tensor=torch.concat(tensors=lv1_fc_o_ls, dim=1).reshape((-1, Net.LV1_FC_CNT, LV1_FC_O_SZ)) #level1_fcAll_o.shape:-1,5,2lv1_fc_selected_hw:torch.Tensor=torch.einsum("bi,bik->bk",(lv1_sel_a,lv1_fcAll_o))#相当于在lv1_fc*_o中选一个最大的lv1_fc_selected_ls.append(lv1_fc_selected_hw)"""#bi,bik->bk ;# ; b:-1 i:5, b:-1 i:5 k:2 -> b:-1 k:2# ; -1_5,-1_5_2 -> -1_2#level1_fc_selected.shape: -1,2"""####dev...# level1_fc_selected_ls:列表, 该列表中由7*7个 (50,2) 的Tensorlevel1_fc_selected:torch.Tensor=torch.concat(tensors=lv1_fc_selected_ls,dim=1)level1_fc_selected_hw_lv1osz_:torch.Tensor=level1_fc_selected.reshape((-1, CELL_CNT_H, CELL_CNT_W, LV1_FC_O_SZ))#level1_fc_selected_hw_lv1osz_.shape: -1, 7, 7, 2level1_fc_selected_hw_lv1osz:torch.Tensor=torch.nn.ZeroPad2d(padding=(0, 0, 0,CELL_CNT_H%HALF_NEB_SZ, 0,CELL_CNT_H%HALF_NEB_SZ ))(level1_fc_selected_hw_lv1osz_)#CELL_CNT_H%NEB_SZ: 7%2==1; #level1_fc_selected_hw_lv1osz.shape: -1, 8, 8, 2CELL_CNT_H_flr: int = level1_fc_selected_hw_lv1osz.shape[1] #:8CELL_CNT_W_flr:int=level1_fc_selected_hw_lv1osz.shape[2]#:8lv2_fc_selected_ls: List[torch.Tensor] = []# lv2_sel_a_stdVar_mean:torch.Tensor=torch.zeros((batch_size,))for h in range(0,CELL_CNT_H_flr,NEB_SZ):#8for w in range(0,CELL_CNT_W_flr,NEB_SZ):#8xCellhw: torch.Tensor = torch.cat(tensors=[level1_fc_selected_hw_lv1osz[:,h,w,:],level1_fc_selected_hw_lv1osz[:,h,w+1,:],level1_fc_selected_hw_lv1osz[:, h+1, w, :], level1_fc_selected_hw_lv1osz[:, h+1, w + 1, :]],dim=1)#xCellhw.shape:-1,2+2+2+2lv2_sel_o: torch.Tensor = self.lv2_sel(xCellhw)# lv1_sel_o: torch.Tensor = self.lv1_sel(xCellhwFlat) # level1_selector_o.shape:-1,5lv2_sel_a: torch.Tensor = torch.softmax(lv2_sel_o, dim=1) # level1_selector_o.shape:: 0:-1, 1:5# lv2_sel_a_stdVar:torch.Tensor=torch.std(input=lv2_sel_a,dim=1)# lv2_sel_a_stdVar_mean=torch.add(input=lv2_sel_a_stdVar_mean,other=lv2_sel_a_stdVar)lv2_fc_o_ls:List[torch.Tensor]= [ self.lv2_fc[i](xCellhw) for i in range(Net.LV2_FC_CNT)]lv2_fcAll_o:torch.Tensor=torch.concat(tensors=lv2_fc_o_ls, dim=1).reshape( (-1, Net.LV2_FC_CNT, LV2_FC_O_SZ)) #level1_fcAll_o.shape:-1,5,2lv2_fc_selected_hw:torch.Tensor=torch.einsum("bi,bik->bk",(lv2_sel_a,lv2_fcAll_o))#相当于在lv2_fc*_o中选一个最大的lv2_fc_selected_ls.append(lv2_fc_selected_hw)# level1_fc_selected_hw_lv1osz[:,h,w,:],level1_fc_selected_hw_lv1osz[:,h,w+1,:]#level1_fc_selected.shape:-1,7*7*2# _=[level1_fc_selected_hw_lv1osz[:,:,i+k,:] for k in range(NEB_SZ) for i in range( 0, CELL_CNT_H_flr, NEB_SZ) ]# level1_fc_selected_hw_lv1osz[:,:,i+0,:] , level1_fc_selected_hw_lv1osz[:,:,i+1,:]level2_fc_selected: torch.Tensor = torch.concat(tensors=lv2_fc_selected_ls, dim=1)clsfy_fc_o:torch.Tensor = self.clsfy_fc(level2_fc_selected)ŷ = F.log_softmax(clsfy_fc_o, dim=1)return ŷ,lv1_sel_a_stdVar_mean#,lv2_sel_a_stdVar_meanfrom sklearn.utils import shuffle
from scipy.sparse import coo_matrix
def train(trainArgs:TrainArgs, model:Net, xTrain:torch.Tensor,yTrain:torch.Tensor, optimizer:Adadelta, epoch)->List[float]:""":param trainArgs::param model::param xTrain::param yTrain::param optimizer::param epoch::return:"""LV1_FC_O_SZ=MnistDim.LV1_FC_O_SZLV2_FC_O_SZ=MnistDim.LV2_FC_O_SZCELL_HW=MnistDim.CELL_HWmodel.train()#模型设置为训练模式batch_size=trainArgs.batch_sizebatch_cnt = int(_TRAIN_SAMPLE_CNT / batch_size)loss_float_ls:List[float]=[]for batch_index in range(batch_cnt):beginIndex=batch_index * batch_sizeendIndex=(batch_index + 1) * batch_sizex=xTrain[beginIndex: endIndex]y=yTrain[beginIndex:endIndex]x_sparse = coo_matrix(x)x, x_sparse, y = shuffle(x, x_sparse, y, random_state=numpy.random.randint(low=0,high=1000,size=(1,))[0] )
# print(f"x:{x.shape},y:{y.shape}")optimizer.zero_grad() # 用 optimizer.zero_grad() 还是 model.zero_grad(), 试了一下 感觉一样的. 但不知道两者差异# model.zero_grad()ŷ,lv1_sel_a_stdVar_mean = model(x) #,lv2_sel_a_stdVar_mean# print(f"ŷ:{ŷ.shape} ,{ŷ.dtype} ; y:{y.shape},{y.dtype}")# output:torch.Size([50, 10]) ,torch.float32 ; y:torch.Size([50]),torch.int64lv1_w_similar= torch.stack([torch.dot(model.lv1_fc[i].weight.flatten(), model.lv1_fc[i_].weight.flatten()).abs() for i in range(Net.LV1_FC_CNT) for i_ in range(i + 1, Net.LV1_FC_CNT)]).sum() / Net.lv1_w_pair_cnt / (LV1_FC_O_SZ * CELL_HW)# lv2_w_similar= torch.stack([torch.dot(model.lv2_fc[i].weight.flatten(), model.lv2_fc[i_].weight.flatten()).abs() for i in range(Net.LV2_FC_CNT) for i_ in range(i + 1, Net.LV2_FC_CNT)]).sum() / Net.lv2_w_pair_cnt / (LV2_FC_O_SZ * MnistDim.NEB_SZ)real_loss=F.nll_loss(ŷ, y)loss = real_loss+lv1_w_similar-torch.mean(input=lv1_sel_a_stdVar_mean) #+lv2_w_similar-torch.mean(input=lv2_sel_a_stdVar_mean)loss.backward()#计算导数optimizer.step()#B. 用导数更新参数w #更新w, 则再次计算导数 便是在原来的w点附近的w点上计算的导数, 这是此处想要的效果loss_float:float=loss.item() ; real_loss_item:float=real_loss.item()loss_float_ls.append(real_loss_item)if batch_index % trainArgs.log_interval == 0:sample_idx=batch_index * len(x)batch_progress=100. * batch_index / batch_cntprint(f'Train Epoch: {epoch} [{sample_idx}/{_TRAIN_SAMPLE_CNT} ({batch_progress:.0f}%)]\tLoss: {loss_float:.6f} {real_loss_item:.6f} ' )return loss_float_lsdef test(model:Net, xTest:torch.Tensor,yTest:torch.Tensor):model.eval()#模型设置为测试模式test_loss = 0correct_avg = 0with torch.no_grad():x, y = xTest , yTestŷ,lv1_sel_a_stdVar_mean = model(x)#,lv2_sel_a_stdVar_meantest_loss = F.nll_loss(ŷ, y, reduction='sum').item() / _TEST_SAMPLE_CNT # sum up batch losspred = ŷ.argmax(dim=1, keepdim=True) # get the index of the max log-probabilitycorrect_avg = pred.eq(y.view_as(pred)).sum().item() / _TEST_SAMPLE_CNTprint(f'\nTest set: Average loss: {test_loss:.6f}, Accuracy: {correct_avg} ({100. * correct_avg :.0f}%)\n')return test_lossdef plot_split_single_mnist_pic(xTrain:torch.Tensor):"""mnist单样本分割 分割成4*4小格子显示出来, 重点逻辑是: (7, 4, 7, 4) [h, :, w, :]:param xTrain::return:"""fig: plotly.graph_objects.Figure = plotly.subplots.make_subplots(rows=7, cols=7, shared_xaxes=True, shared_yaxes=True, vertical_spacing=0, horizontal_spacing=0)xTrain0Img: torch.Tensor = xTrain[0].reshape((PIC_H, PIC_W))plotly.express.imshow(img=xTrain0Img).show()xTrain0ImgCells: torch.Tensor = xTrain0Img.reshape((7, 4, 7, 4))xTrain0ImgCells=torch.swapdims(input=xTrain0ImgCells,dim0=1,dim1=2)#交换 (7, 4, 7, 4) 维度1、维度2 即 (0:7, 1:4, 2:7, 3:4)for h in range(7):for w in range(7):print(f"h,w:{h},{w}")fig.add_trace(trace=plotly.express.imshow(xTrain0ImgCells[h, w]).data[0], col=h + 1, row=w + 1)fig.show()fig:plotly.graph_objects.Figure
fig,_,_=runPlotlyDashWebServerInNewThread()args = Args()torch.manual_seed(args.seed)trainArgs = TrainArgs()xTrain:torch.Tensor;yTrain:torch.Tensor; xTest:torch.Tensor; yTest:torch.Tensor
(xTrain,yTrain,xTest,yTest)=loadMnist()xTrain=torch.Tensor(xTrain).type(torch.float32)
yTrain=torch.Tensor(yTrain).type(torch.int64)
xTest=torch.Tensor(xTest).type(torch.float32)
yTest=torch.Tensor(yTest).type(torch.int64)model = Net()
optimizer = optim.Adadelta(model.parameters(), lr=args.lr)
scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma)for epoch in range(1, args.epochs + 1):xTrain_sparse = coo_matrix(xTrain)xTrain, xTrain_sparse, yTrain = shuffle(xTrain, xTrain_sparse, yTrain, random_state=numpy.random.randint(low=0,high=10000,size=(1,))[0] )xTest_sparse = coo_matrix(xTest)xTest, xTest_sparse, yTest = shuffle(xTest, xTest_sparse, yTest, random_state=numpy.random.randint(low=0,high=10000,size=(1,))[0] )loss_float_ls: List[float] =train(trainArgs, model, xTrain,yTrain, optimizer, epoch)test_loss:float=test(model, xTest, yTest)scheduler.step()_len_loss_float_ls:int=len(loss_float_ls) ;fig.add_trace(plotly.graph_objects.Scatter(x=list(range((epoch-1)*_len_loss_float_ls, epoch*_len_loss_float_ls)), y=loss_float_ls,mode="markers"))if args.save_model:torch.save(model.state_dict(), "mnist_example.pt")loss plot例子
tags:
cell