Android实现OCR文字识别并且转换为Excel、PDF格式输出
由于最近有一个项目有需要用到拍照识别字体,且将识别后的字体转换为对应的Excel,Word,PDF格式的文本输出,所以特地去网上搜集了很多资料来制作,但是网上的资料很少有写到如何在手机端实现OCR技术,即使有实现的人,也不会给出一个很全面的源码,所以小弟特地花了点时间去实现该技术,测试可用后记录下步骤,以备以后查看。
后面我会将我的Demo链接也给出,供大家下载互相交流
前期准备
因为使用的是文字识别技术,所以我这里使用的是的OCR引擎,这款相对于来说识别率还行。
是用c++实现的,需要封装Java API用于平台的调用,所以我们使用的是 Tools for 的一个git分支 -two,它集成了图形处理工具,使用起来很方便,但是网上的都是比较麻烦,需要自己去下载下来编译,才能在上实现,小弟使用的是一个已经编译好的,全部内容可以直接使用,无需再引用其他什么tess-two项目作为lib。
而至于将扫描出来的文字转换部分,小弟只实现了Excel 及 PDF 的转换,对于Word的转换失败了,一部分原因是因为Word的包和Excel,PDF出现了冲突,一部分是因为IText包对的支持还不是很全,中有一些java的API的使用还不支持,会出错。
其中包是某位大神重新对之前的iText进行了重新打包,使之能够支持在上使用中文的PDF,小弟就可耻的借来使用了
好了,下面开始进行实现。
代码实现
使用必须要在手机SD卡中建立// 并且将你的识别字库放入该文件夹下,否则你运行就会出错,很多朋友都推荐使用 adb 命令在手机中进行新建文件夹并推送字库进去,但这操作明显不符合一款成品软件的操作,难道要每个用户都在下载软件的时候 都回家使用adb命令推送一次吗?
所以我们手动写一段代码,在启动软件时,自动创建路径并推送字库进去
初始化OCR环境
先在我们的项目res中建立raw文件夹,并将字库.放进raw中等待稍后启动时推送
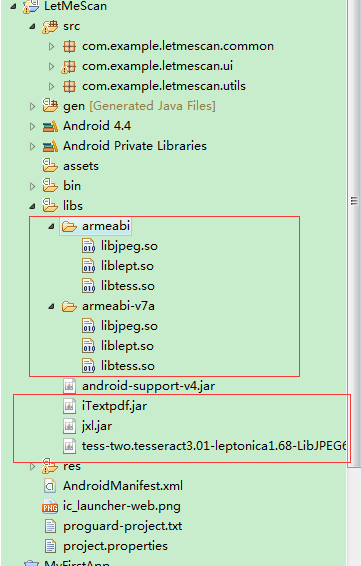
将三个jar包下载下来,以及两个的so文件下载好后放入libs文件夹中
操作完这几步后,我们要考虑几点
- SD卡的读写权限..GE
- SD卡中创建删除文件夹的权限..STEMS
- 我们拍照识别文字需要的拍照权限..
所以我们需要在清单文件中注册以下权限

弄好这几步后,我们开始在中实现推送代码吧,我们原理很简单,先判断有没有SD卡,有就再进行判断SD卡中是否有该字库,没有就进行推送。
判断是否有SD卡
/*** 判断手机是否有SD卡。* * @return 有SD卡返回true,没有返回false。*/public static boolean hasSDCard() {return Environment.MEDIA_MOUNTED.equals(Environment.getExternalStorageState());}将资源文件raw中的资源推送到目标位置
/*** 将资源转换成文件* * @param context* 上下文* * @param ResourcesId* 资源Id* * @param filePath* 目标文件地址* * @param fileName* 目标文件名* * @return 是否成功*/public static boolean ResourceToFile(Context context, int ResourceId,String filePath, String fileName) {InputStream is = null;FileOutputStream fs = null;try {if (!FileUtils.CreateFolder(filePath))return false;is = context.getResources().openRawResource(ResourceId);File file = new File(filePath + File.separator + fileName);fs = new FileOutputStream(file);while (is.available() > 0) {byte[] b = new byte[is.available()];is.read(b);fs.write(b);}return true;} catch (Exception e) {Log.e(TAG, e.toString());return false;} finally {try {if (is != null)is.close();} catch (Exception e) {Log.e(TAG, e.toString());}try {if (fs != null)fs.close();} catch (Exception e) {Log.e(TAG, e.toString());}}}判断是否有该文件
/*** 判断文件是否存在* * @param fileName* 文件名,必须为文件完整路径* * @return 文件存在返回true,文件不存在返回false*/public static boolean IsFileExists(String fileName) {try {File file = new File(fileName);return file.exists();} catch (Exception e) {TrackerUtils.e(e);return false;}}我们先定义好几个固定常量,然后在执行()的时候进行操作
private static final String TESSBASE_PATH = "/mnt/sdcard/tesseract/";private static final String DEFAULT_LANGUAGE = "chi_sim";private static final String IMAGE_PATH = "/mnt/sdcard/ccc.jpg";@Overrideprotected void onCreate(Bundle savedInstanceState) {super.onCreate(savedInstanceState);setContentView(R.layout.activity_main);findView();intercept();String path = TESSBASE_PATH;// 判断是否有SD卡if(FileUtils.hasSDCard()){// 判断字库是否存在if (!FileUtils.IsFileExists(path + DEFAULT_LANGUAGE))//推送字库到SD卡ResourceToFile(this, R.raw.chi_sim, path + "tessdata/",DEFAULT_LANGUAGE +".traineddata");}}OCR扫描解析代码实现
做好前期工作后,我们开始Ocr代码使用部分的编写
public void testOcr() {mHandler.post(new Runnable() {@Overridepublic void run() {ocr();}});}protected void ocr() {//获取图片的显示方向,判断图片是否需要调整try {ExifInterface exif = new ExifInterface(IMAGE_PATH);int exifOrientation = exif.getAttributeInt(ExifInterface.TAG_ORIENTATION,ExifInterface.ORIENTATION_NORMAL);int rotate = 0;switch (exifOrientation) {case ExifInterface.ORIENTATION_ROTATE_90:rotate = 90;break;case ExifInterface.ORIENTATION_ROTATE_180:rotate = 180;break;case ExifInterface.ORIENTATION_ROTATE_270:rotate = 270;break;}Log.v(TAG, "Rotation: " + rotate);int w = mBitmap.getWidth();int h = mBitmap.getHeight();Matrix mtx = new Matrix();mtx.preRotate(rotate);mBitmap = Bitmap.createBitmap(mBitmap, 0, 0, w, h, mtx, false);mBitmap = mBitmap.copy(Bitmap.Config.ARGB_8888, true);} catch (IOException e) {Log.e(TAG, "Rotate or coversion failed: " + e.toString());Log.v(TAG, "in the exception");}//为了获得更好的解析效果,将图片二值化Bitmap data = handleBlackWitheBitmap(mBitmap);ImageView iv = (ImageView) findViewById(R.id.image);iv.setImageBitmap(data);iv.setVisibility(View.VISIBLE);//实例化TessBaseAPITessBaseAPI baseApi = new TessBaseAPI();baseApi.setDebug(true);//初始化TessBaseAPIbaseApi.init(TESSBASE_PATH, DEFAULT_LANGUAGE);//设置需要解析的图片baseApi.setImage(data);//解析图片recognizedText = baseApi.getUTF8Text();//解析完后清除内容baseApi.clear();//结束TessBaseAPIbaseApi.end();if (!StringUtils.IsNullOrEmpty(recognizedText)) {((TextView) findViewById(R.id.field)).setText(recognizedText.trim());}}从代码上可以看出来,其实的使用很简单,就几行代码而已,但是识别率不是很高,所以我在图片操作上增加了一段二值化处理,为了使他更容易被解析,如果你们不需要,可以注释掉
转出到Excel
OCR解析完后,我们开始操作下如何转换成对应的输出格式,先放出转换成Excel的方法
Excel的保存和读取,我使用的是jxl包,研究了一会后稍微写了个方法,简单的实现了保存和读取,但是在我写的Demo中没有引用 读取的方法,只使用了保存的方法 ,且保存的方法也是用固定值进行保存的,各位要是有使用请自行修改
import java.io.File;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.util.ArrayList;import jxl.Range;
import jxl.Workbook;
import jxl.read.biff.BiffException;
import jxl.write.Label;
import jxl.write.WritableSheet;
import jxl.write.WritableWorkbook;
import jxl.write.WriteException;
import jxl.write.biff.RowsExceededException;
import android.os.Environment;
import android.util.Log;
/**** Excel工具类**/
public class ExcelUtils {private static String TAG = ExcelUtils.class.getSimpleName();/*** 保存数据到Excel* @param tableName => 文件名,无需后缀*/public static boolean saveToExcel(String content, String fileName) {WritableWorkbook wwb = null;boolean result = false;fileName = Environment.getExternalStorageDirectory() + File.separator+ fileName + ".xls";Log.i(TAG, fileName);// 假设数据 五行五列int numrows = 5;int numcols = 5;String[][] records = {{ "lin.yifan", "lin.erfan", "lin.sanfan", "lin.sifan","lin.wufan" },{ "lin.yifan", "lin.erfan", "lin.sanfan", "lin.sifan","lin.wufan" },{ "lin.yifan", "lin.erfan", "lin.sanfan", "lin.sifan","lin.wufan" },{ "lin.yifan", "lin.erfan", "lin.sanfan", "lin.sifan","lin.wufan" },{ "lin.yifan", "lin.erfan", "lin.sanfan", "lin.sifan","lin.wufan" } };Log.i(TAG, "开始保存到Excel");try {// 1 使用Workbook类的工厂方法创建一个可写入的工作薄(Workbook)对象wwb = Workbook.createWorkbook(new File(fileName));} catch (IOException e) {e.printStackTrace();}if (wwb != null) {// 创建一个可写入的工作表// 2 创建工作表 Workbook的createSheet方法有两个参数,第一个是工作表的名称,第二个是工作表在工作薄中的位置WritableSheet ws = wwb.createSheet("sheet1", 0);// 3 添加单元格for (int i = 0; i < numrows; i++) {for (int j = 0; j < numcols; j++) {// 这里需要注意的是,在Excel中,第一个参数表示列,第二个表示行Label labelC = new Label(j, i, records[i][j]);try {// 将生成的单元格添加到工作表中ws.addCell(labelC);} catch (RowsExceededException e) {e.printStackTrace();} catch (WriteException e) {e.printStackTrace();}}}try {// 从内存中写入文件中wwb.write();// 关闭资源,释放内存wwb.close();result = true;Log.i(TAG, "保存到Excel成功");} catch (IOException e) {e.printStackTrace();} catch (WriteException e) {e.printStackTrace();}}return result;}/*** 读取数据* @param fileName => 文件名,无需后缀* @return*/public static ArrayList> getExcel(String fileName) {ArrayList innerAList = null;ArrayList> outerAlist = new ArrayList>();fileName = Environment.getExternalStorageDirectory() + File.separator+ fileName + ".xls";Log.i(TAG, fileName);if (!FileUtils.IsFileExists(fileName)) {Log.e(TAG, "the file is not exists! return");return outerAlist;}File file = new File(fileName);Workbook wb = null;try {// 1 创建一个工作簿对象wb,该对象的引用指向某个待读取的Excel文件wb = Workbook.getWorkbook(file);// 2 创建一个工作簿wb中的工作表对象jxl.Sheet sheet = wb.getSheet(0);int stRows = sheet.getRows(); // 得到当前工作表中所有非空行号的数目int stColumns = sheet.getColumns();// 得到当前工作表中所有非空列号的数目Range[] range = sheet.getMergedCells(); // 得到所有合并的单元格for (int i = 0; i < stRows; i++) {innerAList = new ArrayList();for (int j = 0; j < stColumns; j++) {// 3 创建一个单元格对象,来存放从sheet的(第j列,第i行)读取的单元格;jxl.Cell cell = sheet.getCell(j, i);if (range.length > 0) {for (int z = 0; z < range.length; z++) {int lr = range[z].getTopLeft().getRow();// 左上角单元格行号int lc = range[z].getTopLeft().getColumn();// 左上角单元格列号int rr = range[z].getBottomRight().getRow();// 右下角单元格行号int rc = range[z].getBottomRight().getColumn();// 右下角单元格列号// 判断是否是合并的单元格if (i >= lr && i <= rr && j <= rc && j >= lc) {if (i == lr && j == lc) {innerAList.add(cell.getContents());} else {innerAList.add("><><");}} else {// 4 从当前单元格中获得一个已经转换为字符串类型的字符串,详见APIinnerAList.add(cell.getContents());}}} else {innerAList.add(cell.getContents());}}outerAlist.add(innerAList);}} catch (FileNotFoundException fnf) {fnf.printStackTrace();} catch (IOException ioe) {ioe.printStackTrace();} catch (BiffException be) {be.printStackTrace();} finally {wb.close();}return outerAlist;}
} 转出到PDF
PDF的操作我也单独写了一个操作工具类,使用的是包,由于是高手修改过的,所以可以使用中文,不会那么麻烦,但是麻烦的是,导致我无法对Word进行操作,不知道有没有好心的高手,帮忙封装一个支持 pdf 和 word 的 中文 的 itext包
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;import android.os.Environment;
import android.util.Log;import com.itextpdf.text.Document;
import com.itextpdf.text.DocumentException;
import com.itextpdf.text.Font;
import com.itextpdf.text.Paragraph;
import com.itextpdf.text.pdf.BaseFont;
import com.itextpdf.text.pdf.PdfReader;
import com.itextpdf.text.pdf.PdfWriter;
import com.itextpdf.text.pdf.parser.PdfTextExtractor;
/**** Pdf工具类**/
public class PdfUtils {private static String TAG = PdfUtils.class.getSimpleName();public static String getPDF(String fileName) {StringBuffer str = new StringBuffer();// 获取需要解析的文件路径fileName = Environment.getExternalStorageDirectory()+ File.separator + fileName + ".pdf";if(!FileUtils.IsFileExists(fileName)){Log.e(TAG, fileName + "the file is not exists! return");return null;}try {// 使用PdfReader打开pdf文件PdfReader reader = new PdfReader(fileName);// 模板// 获取总共页数int numberOfPages = reader.getNumberOfPages();// 循环获取每页内容for (int i = 0; i < numberOfPages; i++) {
// str.append(new String(reader.getPageContent(i + 1), "UTF-8"));str.append(PdfTextExtractor.getTextFromPage(reader, i + 1));}reader.close();} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();} return str.toString();}/*** 转换为PDF格式* * @param content => 内容* @param fileName => 文件名,无需后缀*/public static boolean transformationToPDF(String content, String fileName) {fileName = Environment.getExternalStorageDirectory() + File.separator+ fileName + ".pdf";boolean result = false;// 1.创建一个documentDocument doc = new Document();FileOutputStream fos;try {Log.i(TAG, "开始生成PDF文件!");fos = new FileOutputStream(new File(fileName));Log.i(TAG, "路径:" + fileName);// 2.定义pdfWriter,指明文件输出流输出到一个文件PdfWriter.getInstance(doc, fos);// 3.打开文档doc.open();doc.setPageCount(1);// 字体 注意,如果是中文,则必须选择字体Font font = setChineseFont();// 4.添加内容Paragraph paragraph = new Paragraph(content, font);doc.add(paragraph);// 添加段落
// for (int i = 0; i < 100; i++) {
// doc.add(new Paragraph("HelloWorld" + "," + "Hello iText" + ","
// + "HelloxDuan"));
// }// 5.关闭doc.close();fos.flush();fos.close();Log.i(TAG, "PDF文件生成成功!");result = true;} catch (FileNotFoundException e1) {e1.printStackTrace();} catch (DocumentException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}return result;}/*** 产生PDF字体* @return*/public static Font setChineseFont() {BaseFont bf = null;Font fontChinese = null;try {bf = BaseFont.createFont("STSong-Light", "UniGB-UCS2-H",BaseFont.NOT_EMBEDDED);fontChinese = new Font(bf, 12, Font.NORMAL);} catch (DocumentException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}return fontChinese;}
}
关键代码都给出来给大家参考了,可惜我使用的是官方给的中文字库,识别率实在不怎么样,但是,使用方法已经给出了,关于提升识别率的方法,过两天我会专门写一篇关于如何正确训练字库的方法,这次的内容如有错误的地方还请指出
下面给出小弟制作的Demo链接
Demo下载地址