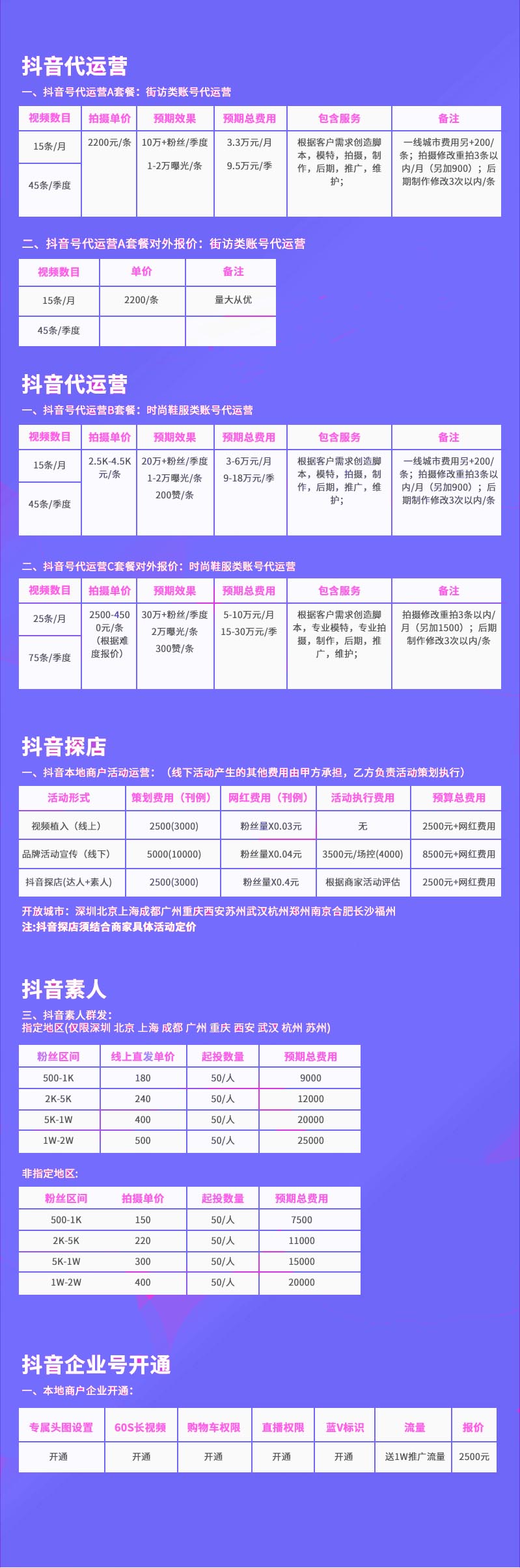
百度怎么抓取关键词?百度收录网站抓取网页的流程揭秘
要做SEO优化和推广,就不得不说一下百度收录的问题。很多人不明白,这么多相同的页面,百度怎么区分先收录哪篇文章?明明内容是一样的,为什么其他网站都收录了自己却没有收录,我们来看看百度蜘蛛收录一个网站的全过程,有需要的朋友可以参考以下
我们知道搜索引擎的工作过程非常复杂。今天给大家分享一下我所知道的百度蜘蛛是如何实现网页索引的。
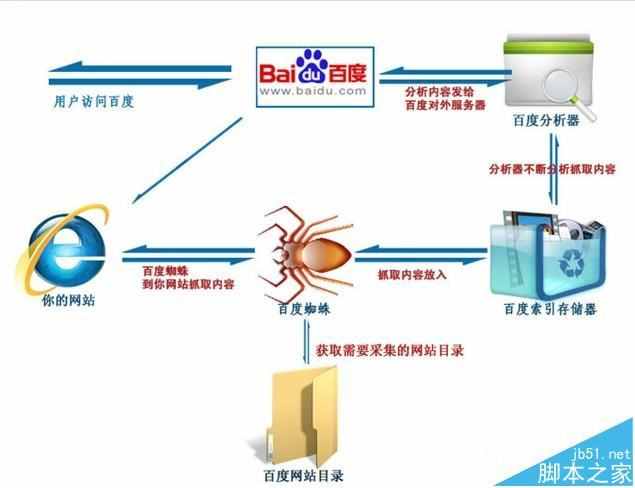
搜索引擎的工作大致可以分为四个过程。
1、蜘蛛爬行。

2、信息过滤。
3、创建网络关键字索引。
4、用户搜索输出结果。
当百度蜘蛛来到一个页面时,它会跟随页面上的链接,从这个页面爬到下一个页面,就像一个递归的过程,这不仅是多年的累人工作。例如,当蜘蛛来到常州昌润信息网首页时,首先会读取根目录下的.txt文件。如果没有禁止搜索引擎抓取,蜘蛛就会开始对网页上的链接进行一一跟踪和抓取。比如我们的文章《畅润资讯:百度收录网站抓取网页的流程揭秘》,引擎会以多进程的方式来到本文所在的网页进行信息抓取。
为了避免重复爬取和爬取网址,搜索引擎会有一个已爬取和未爬取地址的数据库。如果你有新网站,可以去百度官网提交网站的网址,引擎会记录下来。并将其归类为未爬取的URL,然后蜘蛛会使用该表从数据库中提取URL,访问并爬取页面。
蜘蛛不会索引所有页面,它会受到严格的检查。蜘蛛在爬取网页内容时,会进行一定程度的重复内容检测。如果网页所在的网站权限较低,大部分文章都是抄袭的,那么蜘蛛可能不喜欢你的网站。 ,如果不继续抓取,您的网站将不会被收录。
蜘蛛在抓取页面时,首先会分析页面的文本内容。通过分词技术,将网页内容简化为关键词,将关键词和对应的URL做成表格进行索引。
索引有正向索引和反向索引。正向索引是网页内容对应的关键词,反向是关键词对应的网页信息。
当用户搜索某个关键词时,会通过之前建立的索引表进行关键词匹配,通过反向索引表找到该关键词对应的页面,网页的综合得分为由发动机计算。分数决定页面的排名顺序。
郑重声明:本文版权归原作者所有,转载文章仅出于传播更多信息之目的。如果作者信息标注有误,请尽快联系我们修改或删除,谢谢。