【论文笔记】Unsupervised Deep Embedding for Cl
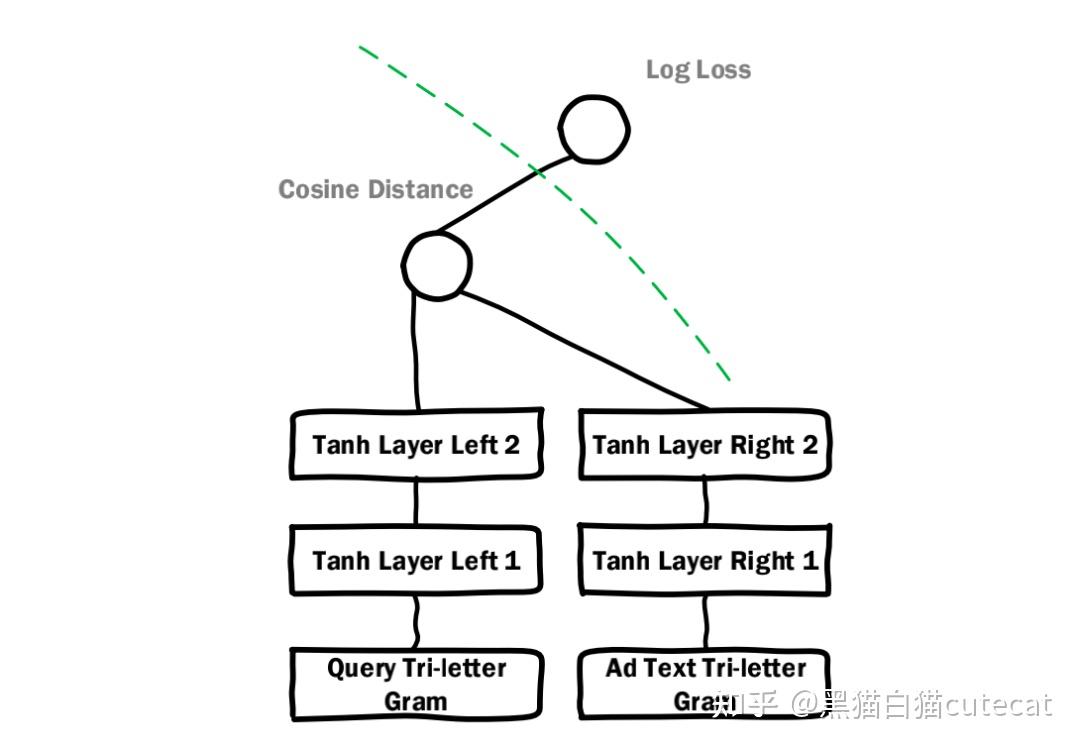
【论文笔记】 Deep for (DEC) 感性认识 堆叠自动编码器(SAE)参数初始化,构建非线性映射
一个AE是两层,训练多个AE,上层输出作为下层输入。逐层训练。把多个AE的前层放到一起作为,后层穿起来放到一起作为。中间有一个瓶颈层(潜在表示层),特征数目较少。完整的-输入输出维度不变,而DEC只取部分,使用瓶颈层的输出当作特征表示z。软分配
有了z,有了聚类中心,使用-t分布进行分配概率的计算,即模型分布Q。(受t-sne启发)构建辅助分布(目标分布)
利用软分配得到的模型分布,利用高置信度预测结果,定义目标分布P基于KL散度,定义目标函数
L = K L ( P ∣ ∣ Q ) L=KL(P||Q) L=KL(P∣∣Q)联合优化表示z与聚类中心μ,再用z去优化SAE的参数自训练策略
使用初始模型去预测数据,再使用高置信度的预测结果来训练模型。迭代提升,直到收敛。在两个连续迭代之间改变簇分配的点少于tol%时,过程停止。 理性认识
is to many data- and has been in terms of and . work has on for . In this paper, we Deep (DEC), a that and using deep . DEC a from the data space to a lower- space in which it a . Our on image and text show over state-of-the-art .
摘要
聚类是许多数据驱动应用领域的核心,在距离函数和分组算法方面已经得到了广泛的研究。相对而言,很少有研究聚焦于学习聚类表示。在本文中,我们提出了深度嵌入式聚类(DEC),一种使用深度神经网络同时学习特征表示和聚类分配的方法。DEC学习从数据空间到低维特征空间的映射,在其中迭代优化聚类目标。我们对图像和文本语料库的实验评估显示,与最先进的方法相比,有显著的改进。
1.
聚类是一种基本的数据分析和可视化工具,在无监督机器学习中已经从不同的角度进行了广泛的研究:什么是簇?什么是正确的距离度量?如何有效地将实例分组到簇中?如何验证簇?等等。在过去的文献中已经探索了许多不同的距离函数和嵌入方法。相对较少的工作关注特征空间的无监督学习,并用于聚类。
距离或差异这类概念是数据聚类算法的核心。而距离则依赖于数据在特征空间中的表示。例如,k-means聚类算法使用给定特征空间中点之间的欧氏距离,这对于图像可能是原始像素或梯度方向直方图。特征空间的选择通常作为应用程序特定细节留给最终用户来确定。然而,很明显,特征空间的选择至关重要;除了最简单的图像数据集,在原始像素上使用欧几里得距离聚类是完全无效的。在本文中,我们重新讨论了聚类分析,并提出了一个问题:我们是否可以使用数据驱动的方法来共同解决特征空间和聚类成员关系?
我们从最近关于计算机视觉深度学习的工作中获得了灵感,通过学习更好的特征,可以在基准任务中获得明显的收益。然而,这些改进是通过监督学习获得的,而我们的目标是无监督数据聚类。为此,我们定义了从数据空间X到低维特征空间Z的参数化非线性映射,在该映射中我们优化了聚类目标。与之前在数据空间或浅层线性嵌入空间上操作的工作不同,我们通过反向传播在聚类目标上使用随机梯度下降(SGD)来学习映射,这是由深度神经网络参数化的。我们将这种聚类算法称为深度嵌入式聚类,或DEC。
优化DEC具有挑战性。我们希望同时解决聚类分配和底层特征表示的问题。然而,与监督学习不同的是,我们不能用标记数据训练我们的深度网络。相反,我们建议用从当前的软聚类分配派生的辅助目标分布迭代地细化聚类。这一过程逐步改进了聚类和特征表示。
我们的实验表明,在图像和文本数据集上,与最先进的聚类方法相比,在准确性和运行时间方面都有显著的改进。我们在MNIST、STL和上评估DEC,并将其与标准和最先进的聚类方法进行比较。此外,我们的实验表明,与最先进的方法相比,DEC对超参数选择的敏感性显著降低。这种鲁棒性是我们聚类算法的一个重要特性,因为当应用于真实数据时,超参数交叉验证的监督是不可用的。
我们的贡献有:(a)深度嵌入和聚类的联合优化;(b)一种新的软分配迭代优化算法;©在聚类精度和速度方面最先进的聚类结果。
2. work 3. Deep
对于 n n n 个点 $ {x_i\in X}_{i=1}^{n} $ ,分为 k k k 个簇,每个簇都由质心(聚类中心)向量 μ j , j = 1 , 2 , . . . , k μ_j,j=1,2,...,k μj,j=1,2,...,k表示。我们建议首先用非线性映射 f θ : X → Z f_θ:X→Z fθ:X→Z 来转换数据,而不是直接在数据空间 X X X中聚类,其中, θ θ θ是参数, Z Z Z是潜在特征空间。为了避免“维度诅咒”, Z Z Z 的维度通常比 X X X 小得多。为了参数化 f θ f_θ fθ,深度神经网络(DNNs)是一种自然选择,因为它们的理论函数近似特性和它们所展示的特征学习能力
DEC对数据聚类,同时学习一套在特征空间Z中的k聚类中心和DNN中将数据点映射到Z的参数θ。
DEC有两个阶段:
(1)用深度自编码器(deep )参数初始化
(2)参数优化(例如,聚类),我们通过迭代计算辅助目标分布和最小化-(KL)散度。
我们从描述阶段(2)参数优化/聚类开始,给出了参数和聚类中心的初始估计。
3.1. with KL
在给出非线性映射f和初始聚类中心的初始估计后,我们提出使用两步交替的无监督算法来改进聚类。
在第一步,我们计算嵌入点和簇中心之间软分配。
第二步,我们更新深度映射f,并通过使用辅助目标分布学习当前的高置信度分配来细化聚类中心。这个过程一直重复,直到满足收敛准则。
3.1.1. SOFT
我们用学生t分布(’s t-)作为核来度量嵌入点与簇中心之间的相似性。
3.1.2. KL
我们提出在辅助目标分布的帮助下,通过学习它们的高置信分配来迭代地改进聚类。具体来说,我们的模型是通过软分配去匹配目标分布来训练的。为此,我们将我们的目标定义为软分配 q i q_i qi 和辅助分布 p i p_i pi 之间的KL散度损失,如下所示 L = KL ( P ∣ ∣ Q ) = ∑ i ∑ j p i j log p i j q i j L\ =\ \text{KL}\left( P||Q \right) \ =\ \sum_i{\sum_j{p_{ij}\log \frac{p_{ij}}{q_{ij}}}} L=KL(P∣∣Q)=i∑j∑pijpij目标分布P的选择对DEC的性能至关重要。一个简单的方法是将每个pi设置为高于置信阈值的数据点的delta分布(到最近的质心),然后忽略其余的。然而,由于qi是软分配,使用软概率目标更自然和灵活。
具体来说,我们希望我们的目标分布具有以下特性:
在我们的实验中,我们首先将 q i q_i qi 提高到2次方,然后根据每个簇的频率进行归一化,从而计算 p i p_i pi :
p i j = q i j 2 / f j ∑ j ′ q i j ′ 2 / f j ′ , f j = ∑ i q i j p_{ij}\ =\ \frac{q_{ij}^{2}/f_j}{\sum_{j'}{q_{ij'}^{2}/f_{j'}}}\ ,\ f_j=\sum_i{q_{ij}} pij=∑j′qij′2/fj′qij2/fj,fj=i∑qij
我们的训练策略可以看作是一种自训练。与自训练一样,我们采用一个初始分类器和一个未标记的数据集,然后用分类器对数据集进行标记,以便使用其自身的高置信预测进行训练。事实上,在实验中,我们观察到DEC通过从高置信预测中学习来改进每次迭代的初始估计,这反过来又有助于改进低置信预测。
3.1.3.
同时优化表示 z i z_i zi 与簇中心 μ j μ_j μj, z i z_i zi再传到DNN中,优化 θ θ θ。
当在两个连续迭代之间改变簇分配的点少于tol%时,过程停止。
3.2.
到目前为止,我们已经讨论了DEC如何运行,给出了DNN参数θ和聚类中心的初步估计。现在我们讨论如何初始化参数和簇中心。
我们使用堆叠自动编码器(SAE)来初始化DEC,因为最近的研究表明,它们在真实数据集上一致地产生有语义意义且区分良好的表示。因此,SAE学习的非监督表示自然有助于使用DEC学习聚类表示。
我们一层一层地初始化SAE网络,每一层都是经过训练的去噪自编码器,在随机破坏后重建前一层的输出。去噪自编码器定义为两层神经网络。
损失为 ∣ ∣ x − y ∣ ∣ 2 2 ||x-y||_2^2 ∣∣x−y∣∣22。在对一层进行训练后,我们用它的输出h作为输入来训练下一层。我们所有的编码器/解码器对中使用ReLUs,除了第一对的g2(它需要重构可能有正负值的输入数据,如零均值图像)和最后一对的g1(这样最终的数据嵌入保留了完整的信息。
在进行贪婪分层训练后,我们将所有编码器层依次连接,然后是所有解码器层,按照反向分层训练顺序,形成一个深度自动编码器,然后对其进行微调,使重构损失最小化。最终的结果是一个多层的深度自动编码器,中间有一个瓶颈编码层。然后我们丢弃解码器层,使用编码器层作为数据空间和特征空间之间的初始映射,如图1所示。
为了初始化聚类中心,我们将数据通过初始化的DNN传递得到嵌入的数据点,然后在特征空间Z中进行标准的k-means聚类,得到k个初始中心。
4.
4.1.
数据集:一个文本数据集和两个图像数据集:
对比算法:k-means、LDGMI和SEC。LDGMI和SEC是基于光谱聚类的算法,它们使用拉普拉斯矩阵和各种变换来提高聚类性能。LDMGI和SEC在很大范围的数据集上都优于传统的谱聚类方法。
5.
6.
本文提出了一种深度嵌入式聚类算法,即在联合优化的特征空间中对一组数据点进行聚类。DEC的工作原理是迭代优化基于KL散度的聚类目标和自训练目标分布。我们的方法可以看作是半监督自我训练的无监督扩展。我们的框架提供了一种方法来学习专门用于聚类的表示,而不需要聚类成员标签。
实证研究证明了我们提出的算法的有效性。DEC提供了相对于超参数设置的改进性能和鲁棒性,这在无监督任务中特别重要,因为交叉验证是不可能的。DEC在数据点数量上也具有线性复杂性的优点,这允许它扩展到大型数据集。
真·笔记
1.软分配
首先明确基本思想:硬分配的意思就是,样本1就是类型1,样本2就是类型2,软分配的意思是样本1有30%的可能是类型1,70%的可能是类型2
小尾巴
1.delta分布,学生t分布
2.LDGMI和SEC
3.谱聚类
4.t-sne
5.pij为何是这么定义的。
重点相关论文
1.van der , and , . data using t-SNE. JMLR, 2008
t-sne
2., , , Hugo, , , , , and , -. : in a deep with a local . JMLR, 2010.
SAE,自动编码器部分
参考资料
1.
2.
3.
4.
5.