刚面完阿里蚂蚁金服的大数据工程师,有话说
//蚂蚁金服//
蚂蚁金服,嗯,996 的岗位。
老读者可能很吃惊,小编不是纯做 SQL 吗,跑蚂蚁去做什么大数据工程师呢,SQL 能管用吗!很负责的告诉你,管用。Hive 与 SQL 本是同根生,语法相似,捧上 10 天半月的 《 Hive 》,边看边练,你也可以,前提是受得了 996. 我是受不了的,因为我有很多可爱的读者,想读我的文章啊,996 了哪有时间。
用 10 万块换自由,咱不干!
其实那是一年多前的事情了。还记得我有个团,里面都是 级别的人物嘛。老朋友约谈,必须赴约啊。技术人在一起,三句离不开老本行,不是数据,就是性能。单机,主从,副本,分布式,嗨了天的吹。但不可不说,大数据已经进入下半场了,有些朋友可能还以为是个噱头。该出去看看了!
谁知道,约谈,本是面基,结果变成了现场面试。
//大数据入门//
之前我写过 L 参加拉斯维加斯的 GIIS ( )峰会系列小说。其实那时我正在操练着 以及 Spark, 写的就是自己。
在朋友的指引下,对着岗位要求一路买书看了下来。前两天有读者问我是不是有大数据入门的书可以推荐,这里总结整理出来,算是有个交代。当然这些书都是我看过的,或者正在看的,给大家一份参考。
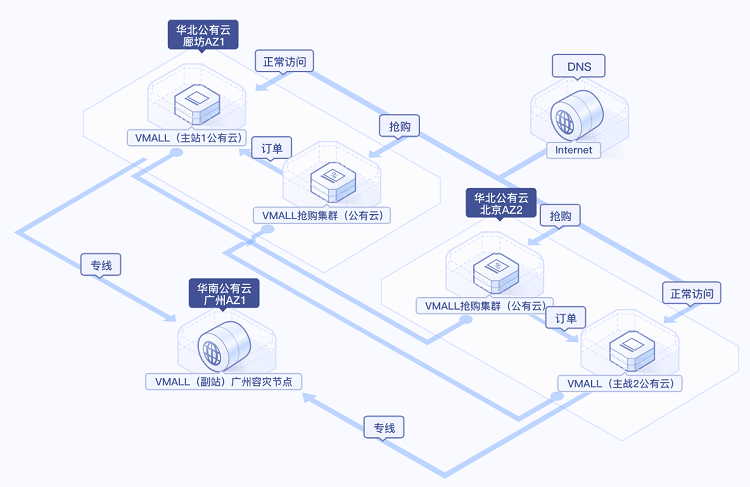
我们先来看看大数据技术栈,有哪些构成。
以上图来自 李智慧 老师的极客专栏《从0开始学大数据》。
(BTW,专栏已经写完了,现有拼团价 79,需要的入手,请勿冲动消费)
大数据真正火起来,是在 2013 年,该年被称为 “大数据元年”。
此前其实大数据已经真真实实的存在了,而那时还没有大数据(Big Data)这一说辞。2004年 先后发表了三篇论文,著名的“三驾马车”:
分布式文件系统 GFS
分布式计算框架
NoSQL 数据库
建议从头看这三篇论文,了解大数据的前史。
而是谁把大数据这门技术带到了世人面前呢,Doug , 全文搜索项目创始人。此人阅读完 的三驾马车后,用纯 Java 实现了 HDFS 和 . 此后,Yahoo, 阿里, 等先后部署了大数据 集群,继而发明了 Pig, Hive 等基于 的生态组件。
到此为止,要读的资料就开始多起来了:
《 Guide》

《Hive Guide》
《 Hive》
但前提至少, Java 你要通吧!
《Java 核心技术》
《Java 并发编程实践》
《深入理解 Java 虚拟机》
《 In Java》
从上面的历史知道,大数据其实是 率先提出来的, 是搜索公司,自然造就这么大的一个轮子是为了搜索用的。所以大数据的第一个应用就是为了搜索。此时外界对于大数据技术,还尚属于吃瓜群众系列,除了 Yahoo, Doug , 以及 , 等一小众公司痴迷之外,大家都很保守。
但平静之下暗流涌动,直到 做出了 Hive , 将数据仓库项目的 90% 任务都推向 Hive 的时候,大家才幡然醒悟,原来巨兽已经屹立很久了。纷纷跟进。这个阶段,大数据被应用最多的地方在数据仓库技术上。而且 Hive 对于 SQL 工程师特别友好,这也促使了 SQL 技术人员对于大数据的热忱。
说起数仓项目,大家耳熟能详的是 和 Inmon. 他俩的书必看:
《The Data : The Guide to 》(《数据仓库工具箱》)
《Data A for the Data :Big Data,Data and Data Vault》(《数据架构 大数据、数据仓库以及 Data Vault》)
至此为止,开发人员的作用是帮助企业完成一些大规模数据的统计,核算工作,提高了效率。但还仅仅是公司的“成本中心”,与“利润中心”格格不入。作为有追求的技术人肯定不愿意,既然数据在自己手里,为什么不能发挥他们的价值呢。所以数据应用进入了数据挖掘时代。此时的挖掘因有了大数据技术,与以往的抽样挖掘完全不一样,基本可以做到全量数据挖掘。所以有关挖掘的技术栈,也可以了解下。
这个阶段可以参考的数目有:
《概率论与数理统计》
《数据挖掘:使用机器学习工具与技术》
前提是计算机基础必须牢靠:
《数据结构与算法分析》
《算法》
也是跑不掉的。
数据挖掘在大数据之前就已经存在了,常规的算法有决策树,分类,关联,线性回归,贝叶斯,聚类等。但都是基于抽样的不完整数据。而现在大数据来了之后,数据喂得更多,模型就更加有效了。依靠人规定的算法已经不能满足机器的胃口,机器可以自己吃进数据,调节参数,产生更多模型,得到更精确的预测。所以大数据应用直接将传统的数据挖掘带入了机器学习时代。
《机器学习》(周志华的西瓜书,必读)
《机器学习实战》

《推荐系统实战》
《计算广告》(洞悉互联网最原始的变现方式)
《集体智慧编程》
《深度学习》
这个领域就要看你研究什么方向了,自然语言处理,视觉识别,无人驾驶等等,都有各自的专业书和技巧需要阅读和掌握。
值得一说的是,数据仓库类的应用涉及到最多的还是离线应用,通过一段时间的数据同步,将计算生成的聚合数据、挖掘模型同步到存储中,方便 UI 调用。但有些实时性很高的应用,比如金融风控,无人驾驶,量化交易等,对数据模型有很高的高频要求,此时再用 , Spark 就会不达标了。因此更多的实时分布式计算引擎就被发明出来了,比如 Spark , Flink, Storm 等。
关于这些流式计算引擎,参考书目有:
《 Spark: -fast Data 》(《Spark 快速大数据分析》
《 With Spark 》(《Spark 高级数据分析》)
《Real-Time Big Data 》(《实时大数据分析,基于 Storm、Spark 技术的实时应用》
《Storm 分布式实时计算模式》
《 Flink 》
《 to Flink》
以上都是主流生态组件的参考数目,有些框架粘合剂的组件,比如 Kafka, , 等NoSQL 书籍,也需要适当看看:
《 :The Guide》(《 权威指南》
《Kafka: The Guide》(《Kafka 权威指南》
《从 Paxos 到 分布式一致性原理与实践》
//总结//
如果你开始进入细节化的学习了,强烈建议不要只看书,一定要多动手!Code 不写出来,那就等于书白看。类似于粘合剂的技术,其实完全可以参考官方资料,在动手实现中,通过搜索引擎帮你解决。
最后,一定别忘了看看 的《 Data- 》, 此书将所有前面提到的应用都总结成方法论,让你有种一览众山小的感觉。
以上都是工程类的基建入门书。
祝你眼光远大,心狠手辣。
————e n d————