2. L1 Loss(绝对值损失函数)
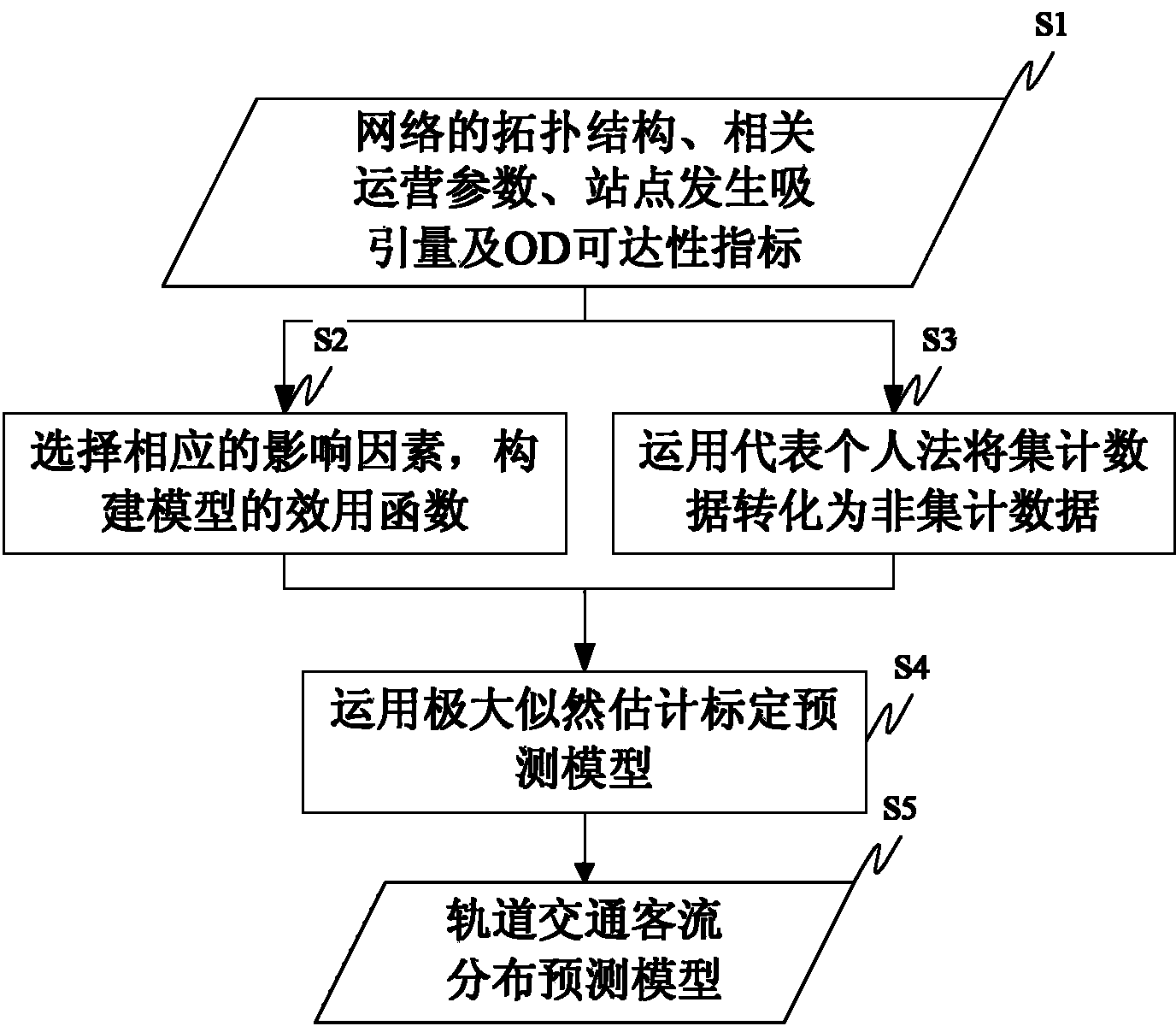
1. L2 loss (均方损失)
除以2就是可以在求导时2和1/2可以相乘抵消。
蓝色的曲线表示:y=0时,变化预测值y’的函数。
绿色曲线表示:似然函数。e^-l。 是一个高斯分布。
橙色的线:表示损失函数的梯度
可以看到:但真实值y‘和真实值隔得比较远的时候,梯度的绝对值比较大,对参数的更新是比较多的。随着预测值慢慢靠近真实值的时候,靠近原点的时候,梯度的绝对值会变得越来越小,也意味着参数更新的幅度也变得越来越小。
但是有时候这够好,比如有时候,我希望离原点远的时候也不要那么大的梯度来更新参数。
似然函数
似然:描述的是在结果已知的情况下,该事件在不同条件下发生的可能性。
似然函数的值越大,表示该事件在对应条件下发生的可能性越大。
最大似然估计就是要找到使得概率最大的时候的参数值。
2. L1 Loss(绝对值损失函数)
3. Huber‘s Loss(鲁棒损失)
定义:当预测值和真实值差得比较大时,绝对值大于1时,是绝对值误差-1/2.当预测值和真实值靠的比较近的时候,就是平方误差。
好处是:当真实值和预测值差得比较远的时候,梯度是个固定值,用一个比较均匀的力度帮你往回拉,在比较靠近的时候,也就是优化末期的时候,梯度的绝对值会变得越来越小,这样可以保证优化是比较平滑的。