目标检测--损失函数
4 、Focal loss
损失函数分类
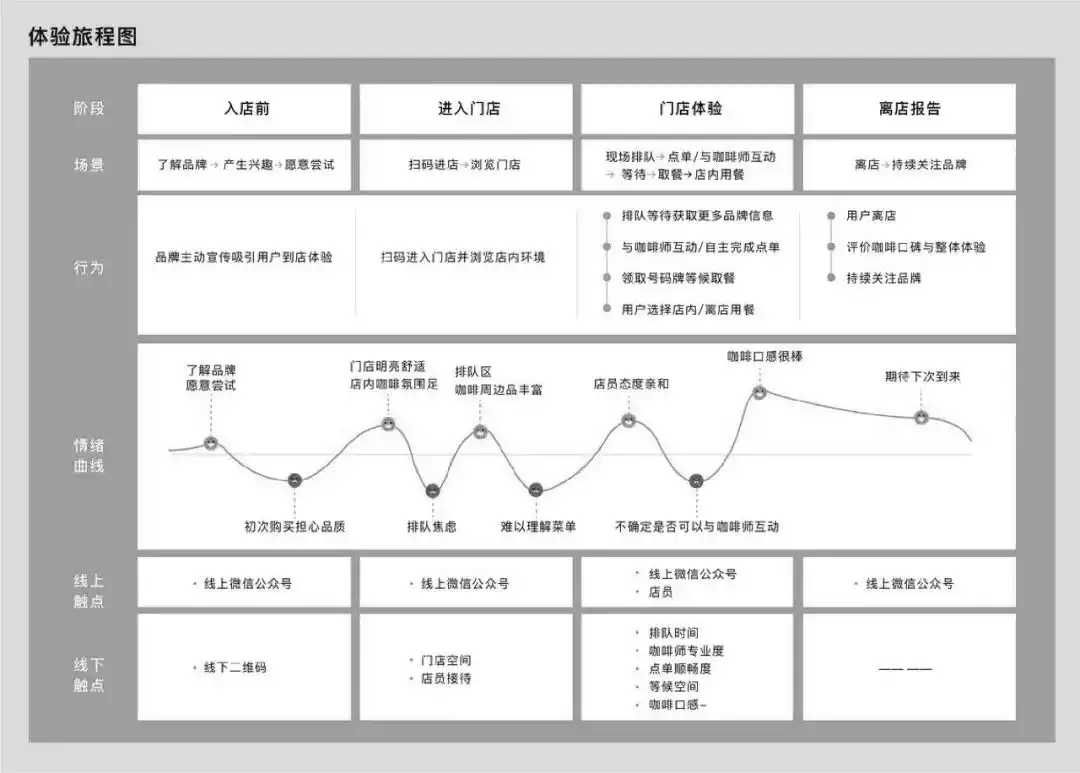
1.预测政治倾向例子
我们希望根据一个人的年龄、性别、年收入等相互独立的特征,来预测一个人的政治倾向,有三种可预测结果:民主党、共和党、其他党。假设我们当前有两个逻辑回归模型(参数不同),这两个模型都是通过的方式得到对于每个预测结果的概率值:
模型1对于样本1和样本2以非常微弱的优势判断正确,对于样本3的判断则彻底错误。
模型2对于样本1和样本2判断非常准确,对于样本3判断错误,但是相对来说没有错得太离谱。
好了,有了模型之后,我们需要通过定义损失函数来判断模型在样本上的表现了,那么我们可以定义哪些损失函数呢?
1、 Error(分类错误率)
最为直接的损失函数定义为:
我们知道,模型1和模型2虽然都是预测错了1个,但是相对来说模型2表现得更好,损失函数值照理来说应该更小,但是,很遗憾的是, 根据公式结果并不能判断出来,所以这种损失函数虽然好理解,但表现不太好。
2 、Mean Error (均方误差)
均方误差损失也是一种比较常见的损失函数,其定义为:
对所有样本的loss求平均:
对所有样本的loss求平均:
我们发现,MSE能够判断出来模型2优于模型1,那为什么不采样这种损失函数呢?
主要原因是逻辑回归配合MSE损失函数时,采用梯度下降法进行学习时,会出现模型一开始训练时,学习速率非常慢的情况。
为什么呢?
这导致模型在一开始学习的时候速率非常慢,而使用交叉熵作为损失函数则不会导致这样的情况发生。
有了上面的直观分析,我们可以清楚的看到,对于分类问题的损失函数来说,分类错误率和均方误差损失都不是很好的损失函数,下面我们来看一下交叉熵损失函数的表现情况。
3 、Cross Loss (交叉熵损失函数)
3.1 表达式
(1) 二分类
在二分的情况下,模型最后需要预测的结果只有两种情况,对于每个类别我们的预测得到的概率为p和 1-p 。此时表达式为:
(2) 多分类
多分类的情况实际上就是对二分类的扩展:
现在我们利用这个表达式计算上面例子中的损失函数值:
对所有样本的loss求平均:

对所有样本的loss求平均:
可以发现,交叉熵损失函数可以捕捉到模型1和模型2预测效果的差异。
2.函数性质
可以看出,该函数是凸函数,求导时能够得到全局最优值。
3. 学习过程
交叉熵损失函数经常用于分类问题中,特别是在神经网络做分类问题时,也经常使用交叉熵作为损失函数,此外,由于交叉熵涉及到计算每个类别的概率,所以交叉熵几乎每次都和(或)函数一起出现。
我们用神经网络最后一层输出的情况,来看一眼整个模型预测、获得损失和学习的流程:
1、神经网络最后一层得到每个类别的得分;
2、该得分经过(或)函数获得概率输出;
3、模型预测的类别概率输出与真实类别的one hot形式进行交叉熵损失函数的计算。(注意看举例模型计算交叉熵损失函数的值)
4、学习任务分为二分类和多分类情况,我们分别讨论这两种情况的学习过程。
3.1 二分类情况(反向传播的一个过程)
上图是2分类交叉熵损失函数学习过程
如上图所示,求导过程可分成三个子过程,即拆成三项偏导的乘积:
可以看到,我们得到了一个非常漂亮的结果,所以,使用交叉熵损失函数,不仅可以很好的衡量模型的效果,又可以很容易的的进行求导计算。
4 、Focal loss