头条项目推荐的相关技术(七): 离线排序模型训练与在线计算
1. 写在前面
这里是有关于一个头条推荐项目的学习笔记,主要是整理工业上的推荐系统用到的一些常用技术, 这是第七篇, 上一篇介绍了离线召回与定时更新技术, 这里说的就是根据用户的历史点击行为,基于模型或者是文章内容,从海量的文章中为每个用户在每个频道召回几百篇文章,并存储到HBase,供后面的精排模型所使用。 而今天这篇文章介绍的就是离线排序模型训练与实时计算用到的相关技术。这篇文章使用的数据就是前面召回回来的候选样本集。 主要内容如下:
小总
Ok, let’s go!
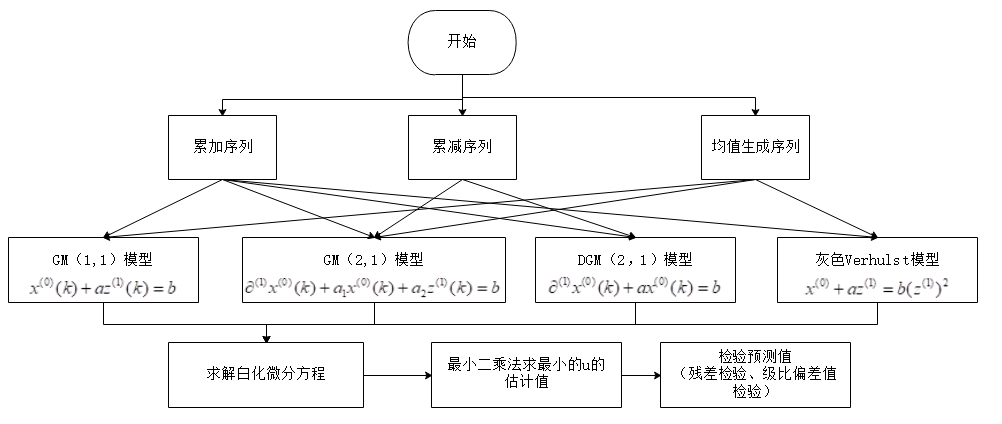
2. 离线排序模型训练基础 2.1 离线排序模型 - CTR预估
CTR(Click- Rate)预估:给定一个Item,预测该Item会被点击的概率
模型这块的逻辑是离线把模型训练好,然后实时的部分读取模型去进行服务。总体流程如下:
对于排序模型, spark本身支持的太少了,也就是有个LR还能用,而现在是深度学习的时代,一般这块都用一些比较优秀的深度学习模型,所以会基于框架去搭建深度学习模型去用于排序, 并且会提供服务, 为了能够快速的读取数据, 一般会把训练样本转成文件。 所以整体的流程就是上面这个图中表示的: 首先从前面保存的用户画像和文章画像中抽取出排序部分所用的特征,存入到HBase中。这些特征后面会提供给一些实施排序的模型,包括spark集成的LR模型,当然这个对于目前推荐来说不够强大,所以一般会用的深度学习模型,而这些模型实时排序读取起来不方便,所以一般会进行线上部署从而去服务, 而为了让TF模型快速的读取数据,一般还会把完整特征转一份文件保存。 这就是这块的整体逻辑了。 后面所介绍的,就是这上面图里面的各个模块的具体细节以及优化了。
2.2 排序模型
这里和我之前总结的王喆老师深度学习推荐系统上的模型对应起来了, 这里又给出了一个总结,最基础的模型目前都是基于LR的点击率预估策略,目前在工业使用模型做预估的有这么几种类型
深模型 宽模型 + 深模型
下面是先用一个LR模型做一些简单的预测, 因为这个模型spark里面已经集成了,直接可以拿过来使用。 等下下篇文章的时候,再去整理深度学习模型究竟是如何进行排序且线上服务的。 这里的重点是弄明白整个排序部分的逻辑,这一块究竟怎么玩才是最重要的,而排序模型,仅仅是模型而已,不是实战课程的重点内容哈哈。再说个特征处理原则就开始干了。
2.3 特征处理原则
这个其实我在第五篇文章的最后,参考王喆老师的书整理的比较详细,这里简单的复习一下吧
这里还有个图:
2.4 spark LR的训练与评估
逻辑回归优化训练方式: Batch SGD优化,并加入正则防止过拟合
下面介绍如何使用spark LR进行CTR预估,主要步骤如下:
需要通过spark读取Hive外部表, 需要新的spark 配置
增加HBase配置读取用户行为表,与用户画像,文章画像,构造训练样本LR模型进行训练LR模型进行预测与结果评估
下面一一来展开。
2.4.1 创建环境
这里就得再整理点新的东西了,我们的用户画像和文章画像是存在了HBase里面,而我们是通过Hive进行读取分析, 注意此时是Hive读取分析HBase里面的数据,之前都是Hive去读取分析HDFS上的数据,这不是一回事哈。所以在初始化配置中需要加入HBase的 IP以及 监控, 默认是2181端口, 但是为了避免与后面kafka那边的端口冲突,这里改成了22181.
下面在新建一个.ipynb文件,在这里面写代码,创建一个,注意这里的创建,不用之前的那个n()了,而是新配置了一个()
# 前面加环境变量这些参考前面的吧,因为我这边环境和它这里不一样,我就不贴了。# 导包
from pyspark.ml.feature import OneHotEncoder
from pyspark.ml.feature import StringIndexer
from pyspark.ml import Pipeline
from pyspark.sql.types import *
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.classification import LogisticRegression
from pyspark.ml.classification import LogisticRegressionModel
from offline import SparkSessionBaseclass CtrLogisticRegression(SparkSessionBase):SPARK_APP_NAME = "ctrLogisticRegression"ENABLE_HIVE_SUPPORT = Truedef __init__(self):self.spark = self._create_spark_hbase()ctr = CtrLogisticRegression()
这里关键是这个(), 我们后面需要通过spark读取HIVE外部表,需要新的配置, 这个基础的函数,可以加在那个中, 这样直接继承过来就OK。
def _create_spark_hbase(self):conf = SparkConf() # 创建spark config对象config = (("spark.app.name", self.SPARK_APP_NAME), # 设置启动的spark的app名称,没有提供,将随机产生一个名称("spark.executor.memory", self.SPARK_EXECUTOR_MEMORY), # 设置该app启动时占用的内存用量,默认2g("spark.master", self.SPARK_URL), # spark master的地址("spark.executor.cores", self.SPARK_EXECUTOR_CORES), # 设置spark executor使用的CPU核心数,默认是1核心("spark.executor.instances", self.SPARK_EXECUTOR_INSTANCES),("hbase.zookeeper.quorum", "192.168.56.101"), # 新加了与HBase连接的两个配置("hbase.zookeeper.property.clientPort", "22181") # 这里的端口变了)conf.setAll(config)# 利用config对象,创建spark sessionif self.ENABLE_HIVE_SUPPORT:return SparkSession.builder.config(conf=conf).enableHiveSupport().getOrCreate()else:return SparkSession.builder.config(conf=conf).getOrCreate()
2.4.2 读取用户点击行为表,与用户画像和文章画像,构造训练样本
这一步是核心,样本中的主要构成就是特征与标签, 而这两块,主要是来自于用户行为表,用户画像和文章画像。 在用户行为表中记录着用户对于某篇文章的点击行为,而这个就是我们的label。所以这里又用到了我们的用户行为表, 也就是, 这个表确实很关键。 还记得数据长啥样吗?再看下:
在这个表中,我们需要, 和这三列数据,其中就是我们的label。而特征值呢?
所以最后我们构建的样本数据长下面这个样子:
当然这里还可以再拼接一些用户的基本信息啥的, 不过这里用了这几个,就先用这几个吧, 其他的可以作为优化空间。 但是处理逻辑都是一模一样的。下面看看如何得到上面的这个数据表。
首先,读取行为日志数据,这个在数据库里面的表里面选择出我们需要的四列特征。 这里又三个数据库, 数据库主要存业务相关的表,存的原始数据, 数据库存的是文章画像结果相关的表, 而数据库存的是用户历史行为相关的数据记录。这几个数据库是干啥的得了解。 而日志行为,当然是用数据库啦:
ctr.spark.sql("use profile")
# +-------------------+----------+----------+-------+
# | user_id|article_id|channel_id|clicked|
# +-------------------+----------+----------+-------+
# |1105045287866466304| 14225| 0| false|
user_article_basic = ctr.spark.sql("select * from user_article_basic").select(['user_id', 'article_id', 'channel_id', 'clicked'])
用户画像读取处理与日志数据合并,这里用的是里面的数据表,这个是关联的HBase上的那个表, 记载的是用户的相关信息。具体可以看第五篇文章里面的整理。具体代码如下:
user_profile_hbase = ctr.spark.sql("select user_id, information.birthday, information.gender, article_partial, env from user_profile_hbase")
user_profile_hbase = user_profile_hbase.drop('env')# +--------------------+--------+------+--------------------+
# | user_id|birthday|gender| article_partial|
# +--------------------+--------+------+--------------------+
# | user:1| 0.0| null|Map(18:Animal -> ...|
接下来,读取用户画像的Hive外部表,构造样本:
# 这里是为了只拿到用户id,而把前面的那个user:去掉,看上面表里面的user_id
def get_user_id(row):return int(row.user_id.split(":")[1]), row.birthday, row.gender, row.article_partialuser_profile_hbase = user_profile_hbase.rdd.map(get_user_id).toDF(["user_id", "gender", "birthday", "article_id"])
这时候,一运行,会报错:some of types be by the first 100 rows, train again with , 这个的意思是说对于某些有大量空值的列, 无法确定到底应该是这么类型,在后面就会发现, 这个里面的和列有大量的空值,超过了50%以上,所以这也是我们后面要删除的原因, 但是这个地方没法没法这样建表了, 那怎么办呢? 所以这里的一个知识点: 如果DF存在连续大量的空缺值, 这时候toDF这种方式无法得到这列给什么类型,就会报上面的错误。
解决方案: 手动指定类型, 方法就是用, 然后指定一个参数传入每一列的类型即可。
_schema = StructType([StructField("user_id", LongType()),StructField("birthday", DoubleType()),StructField("gender", BooleanType()), # 这里空缺值我们手动指定类型StructField("weights", MapType(StringType(), DoubleType()))
])user_profile_hbase_temp = user_profile_hbase.rdd.map(get_user_id)
user_profile_hbase_schema = ctr.spark.createDataFrame(user_profile_hbase_temp, schema=_schema)train = user_article_basic.join(user_profile_hbase_schema, on=['user_id'], how='left').drop('channel_id')
得到的结果如下(这里就会发现了空缺值)
这里不是没有考虑用户的基本信息,而是因为用户基本信息这块缺失值太多了,所以删除掉了。
接下来, 文章频道与向量读取合并,并删除掉上面缺失的那两个特征。文章向量在数据库中的表。
ctr.spark.sql("use article")
article_vector = ctr.spark.sql("select * from article_vector")# 在spark程序中,这个变量最好还是以同样的变量名处理接收,这也是一种优化方式,这种不会浪费内存。
train = train.join(article_vector, on=['article_id'], how='left').drop('birthday').drop('gender')
这样,就把文章向量合并了上来:
合并文章画像的权重特征, 这里用的依然是数据库, 文章画像在中。这里的逻辑是这样,因为这个里面是每个关键词以及权重信息,如果关键词太多的话,选择最关键的N个,这里选择了前10个关键词对应的权重。
ctr.spark.sql("use article")
article_profile = ctr.spark.sql("select * from article_profile")def article_profile_to_feature(row):try:weights = sorted(row.keywords.values())[:10] # 这里排序选择前10个关键词except Exception as e: # 如果关键词不够10个,这里会报异常, 这里给个默认值0, 之所以给0,是对线性回归不起作用,不影响weights = [0.0] * 10return row.article_id, weights
article_profile = article_profile.rdd.map(article_profile_to_feature).toDF(['article_id', 'article_weights'])# 下面前面的表连接上来
train = train.join(article_profile, on=['article_id'], how='left')
这个结果如下:
这里最后还要处理下这个特征,也就是用户的标签画像特征。
进行用户的权重特征筛选处理,类型处理
train = train.dropna()
columns = ['article_id', 'user_id', 'channel_id', 'articlevector', 'user_weights', 'article_weights', 'clicked']def feature_preprocess(row):from pyspark.ml.linalg import Vectorstry:# 获取用户对应文章频道号的关键词权重weights = sorted([row.weights[key] for key in row.weights.keys() if key[:2] == str(row.channel_id)])[:10]except Exception: # 如果不够10个,就会抛出异常, 这时候给默认值weights = [0.0] * 10# 这里的那些向量字段要转成向量才能放到逻辑回归模型用,现在是数组类型的# 所以往Hive中存的时候,这些向量数据要转成数组类型,而导入过来用的时候,数组类型要转成向量类型return row.article_id, row.user_id, row.channel_id, Vectors.dense(row.articlevector), Vectors.dense(weights), Vectors.dense(row.article_weights), int(row.clicked)train = train.rdd.map(feature_preprocess).toDF(columns)
结果如下:
这时候就得到了我们最终的数据了。但是这个数据呢? 现在还不能给LR模型训练,因为LR模型要求的输入是有格式的,所以还得需要特征格式的指定。
2.4.3 训练LR模型
LR模型训练的时候,需要指定特征参数和label参数, 所以我们还得先把特征进行拼接起来,合成一个特征列表, 这里用()收集
cols = ['article_id', 'user_id', 'channel_id', 'articlevector', 'weights', 'article_weights', 'clicked']# 这里收集第2个到第5个特征`在这里插入代码片`
train_version_two = VectorAssembler().setInputCols(cols[2:6]).setOutputCol("features").transform(train)
这里拿我之前学习的一个项目例子看下效果:
就是把前面所有列的特征拼接到一块去了。下面就能训练LR模型了,我发现,大量的工作都在数据的处理和样本的制作上, 到模型这块, 仅仅两三句代码就能搞定,就是调个包,然后构建模型,然后fit。
lr = LogisticRegression()
model = lr.setLabelCol("clicked").setFeaturesCol("features").fit(train_version_two)
# model.save("hdfs://hadoop-master:9000/headlines/models/lr.obj")
2.4.4 点击率预测结果
使用model模型加载预估
online_model = LogisticRegressionModel.load("hdfs://hadoop-master:9000/headlines/models/CtrLogistic.obj")
res_transfrom = online_model.transform(train_version_two)
res_transfrom.select(["clicked", "probability", "prediction"]).show()
逻辑回归模型预测的时候,会自动生成一个列,表示的预测结果, 这里也是拿之前项目的一个结果来看下:
这里主要说一下这个这里的格式,这个是个list, [不点击的概率, 点击的概率], 通常我们会拿点击的这个概率作为最终的预测结果。所以最后再进行一步处理保存结果,然后计算auc
def vector_to_double(row):return float(row.clicked), float(row.probability[1]) score_label = res_transfrom.select(["clicked", "probability"]).rdd.map(vector_to_double)
有了这个,下面我们就可以进行评估了。
2.4.5 模型评估 - 与AUC
这里可以画出auc曲线图竟然,看操作:
import matplotlib.pyplot as plt
plt.figure(figsize=(5,5))
plt.plot([0, 1], [0, 1], 'r--')
plt.plot(model.summary.roc.select('FPR').collect(), # collect()把rdd转成numpy数组model.summary.roc.select('TPR').collect())
plt.xlabel('FPR')
plt.ylabel('TPR')
plt.show()
如果要计算ROC或者AUC, 这里建议用的包:
from sklearn.metrics import roc_auc_score, accuracy_score
import numpy as nparr = np.array(score_label.collect()) # 这里需要转成numpy的array形式
评估AUC与准确率
accuracy_score(arr[:, 0], arr[:, 1].round())
0.9051438053097345roc_auc_score(arr[:, 0], arr[:, 1])
0.719274521004087
这样就用逻辑回归模型走完了排序的整个流程, 从制作样本 -> 模型训练 -> 模型预测 -> 模型评估
3. 离线CTR特征中心更新
这里是定时更新离线的CTR特征,特征服务中心可以为离线计算提供用户与文章的高级特征,充当着重要的角色。可以为程序提供快速的特征处理与特征结果,而且不仅仅提供给离线使用。还可以作为实时的特征供其他场景读取进行
原则是:用户,文章能用到的特征都进行处理进行存储,便于实时推荐进行读取。
目的是:模型训练,模型实时预测的时候提供遍历,快速构建样本预测,只需要用户_id, 文章_id,就能直接读取到HBase中存储的模型中要使用的特征,直接拿出来做预测即可,对于后面做推荐非常方便。
存储形式:
首先确定创建特征结果HBASE表:这里创建了两个表,分别保存我们的用户标签向量和文章向量特征
# 表名 列族(频道) 主键(user_id), 列名
create 'ctr_feature_user', 'channel'4 column=channel:13, timestamp=1555647172980, value=[] 4 column=channel:14, timestamp=1555647172980, value=[] 4 column=channel:15, timestamp=1555647172980, value=[] 4 column=channel:16, timestamp=1555647172980, value=[] 4 column=channel:18, timestamp=1555647172980, value=[0.2156294170196073, 0.2156294170196073, 0.2156294170196073, 0.2156294170196073, 0.2156294170196073, 0.2156294170196073, 0.2156294170196073, 0.2156294170196073, 0.2156294170196073, 0.2156294170196073] 4 column=channel:19, timestamp=1555647172980, value=[] 4 column=channel:20, timestamp=1555647172980, value=[] 4 column=channel:2, timestamp=1555647172980, value=[] 4 column=channel:21, timestamp=1555647172980, value=[]create 'ctr_feature_article', 'article'COLUMN CELL article:13401 timestamp=1555635749357, value=[18.0,0.08196639249252607,0.11217275332895373,0.1353835167902181,0.16086650318453152,0.16356418791892943,0.16740082750337945,0.18091837445730974,0.1907214431716628,0.2........................-0.04634634410271921,-0.06451843378804649,-0.021564142420785692,0.10212902152136256]
上面这个建表的里面的列的选取,应该是跟着我们模型用到的特征来的,对于上面的逻辑回归模型, 主要用到特征是'', '', '', '', 这里面用户的权重特征一列,所以用户表里面的value保存的就是这个特征,保存到HBase,方便后面的直接读取。 而, 和, 是文章的画像特征提取的,从后面的代码里面会看到,这里把这三列直接用()函数拼接成了一列, 这就是的value。
如果想离线分析,这里可以创建Hive外部表, 一般不需要离线分析
create external table ctr_feature_user_hbase(
user_id STRING comment "user_id",
user_channel map comment "user_channel")
COMMENT "ctr table"
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,channel:")
TBLPROPERTIES ("hbase.table.name" = "ctr_feature_user");create external table ctr_feature_article_hbase(
article_id STRING comment "article_id",
article_feature map comment "article")
COMMENT "ctr table"
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,article:")
TBLPROPERTIES ("hbase.table.name" = "ctr_feature_article");
3.1 用户特征中心更新
目的:计算用户特征更新到HBase
步骤:
获取特征进行用户画像权重过滤
# 构造样本
ctr.spark.sql("use profile")user_profile_hbase = ctr.spark.sql("select user_id, information.birthday, information.gender, article_partial, env from user_profile_hbase")# 特征工程处理
# 抛弃获取值少的特征
user_profile_hbase = user_profile_hbase.drop('env', 'birthday', 'gender')def get_user_id(row):return int(row.user_id.split(":")[1]), row.article_partialuser_profile_hbase_temp = user_profile_hbase.rdd.map(get_user_id)from pyspark.sql.types import *_schema = StructType([StructField("user_id", LongType()),StructField("weights", MapType(StringType(), DoubleType()))
])user_profile_hbase_schema = ctr.spark.createDataFrame(user_profile_hbase_temp, schema=_schema)def frature_preprocess(row):from pyspark.ml.linalg import Vectorschannel_weights = []for i in range(1, 26):try:_res = sorted([row.weights[key] for keyin row.weights.keys() if key.split(':')[0] == str(i)])[:10]channel_weights.append(_res)except:channel_weights.append([0.0] * 10)return row.user_id, channel_weights# 这个res首先是个列表,第0个元素是用户id, 第1个元素是一个二维数组, res[1][0]表示第1个频道的用户10个标签权重,依次类推
res = user_profile_hbase_schema.rdd.map(frature_preprocess).collect()
特征批量存储, 保护用户每个频道的特征
import happybase
# 批量插入Hbase数据库中
pool = happybase.ConnectionPool(size=10, host='hadoop-master', port=9090)
with pool.connection() as conn:ctr_feature = conn.table('ctr_feature_user')with ctr_feature.batch(transaction=True) as b: # 批量存储打开for i in range(len(res)): # 遍历用户for j in range(25): # 遍历每个频道b.put("{}".format(res[i][0]).encode(),{"channel:{}".format(j+1).encode(): str(res[i][1][j]).encode()})conn.close() # 关闭之后,会统一的把数据进行插入,而不是一条条的走
这样,用户画像的特征保存完毕,后面用的时候,就需要在这个数据库里面拿相应用户的特征就OK了。
3.2 文章特征中心更新
我们需要保存的文章特征有哪些?
存储这些特征以便于后面实时排序时候快速提取特征。步骤如下:
读取相关文章画像进行文章相关特征提取和处理合并文章所有特征作为模型训练或者预测的初始特征文章特征存储到HBase
下面一一看:
读取相关画像, 这里使用的数据库,文章画像在表里。
ctr.spark.sql("use article")
article_profile = ctr.spark.sql("select * from article_profile")
进行文章相关特征和提取
文章的关键词特征,也是取最关键的前10个关键词的权重特征
def article_profile_to_feature(row):try:weights = sorted(row.keywords.values())[:10]except Exception as e:weights = [0.0] * 10return row.article_id, row.channel_id, weights
article_profile = article_profile.rdd.map(article_profile_to_feature).toDF(['article_id', 'channel_id', 'weights'])article_profile.show()
文章的向量特征, 把这个拼接到前面的表上去。文章向量读取并转成向量, 这里记得要用把数组类型的向量转成向量。
article_vector = ctr.spark.sql("select * from article_vector")
article_feature = article_profile.join(article_vector, on=['article_id'], how='inner')
def feature_to_vector(row):from pyspark.ml.linalg import Vectorsreturn row.article_id, row.channel_id, Vectors.dense(row.weights), Vectors.dense(row.articlevector)
article_feature = article_feature.rdd.map(feature_to_vector).toDF(['article_id', 'channel_id', 'weights', 'articlevector'])
指定所有文章进行特征合并, 这里用到了()函数进行封装,这样可以供后面的逻辑回归直接使用。
# 保存特征数据
cols2 = ['article_id', 'channel_id', 'weights', 'articlevector']
# 做特征的指定指定合并
article_feature_two = VectorAssembler().setInputCols(cols2[1:4]).setOutputCol("features").transform(article_feature)
这样特征就处理完了,这个的长度是111维(1+10+100)
接下来保存到数据库。
# 保存到特征数据库中
def save_article_feature_to_hbase(partition):import happybasepool = happybase.ConnectionPool(size=10, host='hadoop-master')with pool.connection() as conn:table = conn.table('ctr_feature_article')for row in partition:table.put('{}'.format(row.article_id).encode(),{'article:{}'.format(row.article_id).encode(): str(row.features).encode()})article_feature_two.foreachPartition(save_article_feature_to_hbase)
3.3 离线特征中心定时更新
这里又是定时更新的那一套了,首先先把上面的代码进行合并,封装到一个类里面去。
下面就是完整的逻辑代码了, 这个要写到中, 在下面增加一个.py文件,在里面加入代码:
class FeaturePlatform(SparkSessionBase):"""特征更新平台"""SPARK_APP_NAME = "featureCenter"ENABLE_HIVE_SUPPORT = Truedef __init__(self):# _create_spark_session# _create_spark_hbase用户spark sql 操作hive对hbase的外部表self.spark = self._create_spark_hbase()def update_user_ctr_feature_to_hbase(self):#上面更新用户画像特征中心的代码def get_user_id(row):passdef feature_preprocess(row):pass# 插入到HBasedef update_article_ctr_feature_to_hbase(self):# 下面更新文章画像特征中心的代码def article_profile_to_feature(row):passdef feature_to_vector(row):pass# 保存到HBase
添加.py更新程序
def update_ctr_feature():"""定时更新用户、文章特征:return:"""fp = FeaturePlatform()fp.update_user_ctr_feature_to_hbase()fp.update_article_ctr_feature_to_hbase()
把定时更新的函数添加到中定时运行即可。
# 添加一个定时运行文章画像更新的任务,每隔1个小时运行一次
scheduler.add_job(update_article_profile, trigger='interval', hours=1)
# 添加一个定时运行用户画像更新的任务, 每隔2个小时运行一次
scheduler.add_job(update_article_profile, trigger='interval', hours=2)
# 添加一个定时运行用户召回更新的任务, 每隔3个小时运行一次
scheduler.add_job(update_user_recall, trigger='interval', hours=3)
# 添加定时更新用户文章特征结果的程序,每个4小时更新一次
scheduler.add_job(update_ctr_feature, trigger='interval', hours=4)
因为这个用户文章特征结果更新的这个程序是依赖于用户画像和文章画像的,所以更新的间隔要高于前面的两个,这样等用户文章画像更新好了再去计算它。
到这里,离线部分的定时更新任务就基本完成了,主要有上面四件事情要做, 必须要明白各个事情的目的,以及各个事情是怎么做。 这里简单的梳理下: 重点知识
文章画像和用户画像的更新,是为了后面提取特征,训练模型用的。 而用户召回更新的目的是为了能够后面快速的产生推荐候选集。 而用户文章特征中心,又直接保存着用户和文章的特征,这些特征又可以直接供模型预测。 这几个进行配合就能够很快的进行推荐。
比如, 我们先根据已有的用户画像和文章画像,抽取出特征来,去训练一个逻辑回归模型并保存起来。
这时候如果新来了某个用户, 我们拿到他的用户id, 根据用户召回更新的结果集,能够快速拿出召回回来的几百篇的候选文章, 而根据保存好的特征中心的结果, 对于这几百篇候选文章,根据用户id,文章id就立即能拿出模型可以用来预测的特征, 那么我们又有之前训练好的逻辑回归模型,就可以直接对每篇候选文章进行预测用户的点击概率,根据这个概率从大到小排序,把靠前的N篇推给用户即可。
这就完成了线下推荐的逻辑。
文章画像的更新(第三,四篇文章)
用户画像更新(第五篇文章)
用户召回(第六篇文章)
特征中心平台
4. 实时计算业务介绍 4.1 业务与需求
实时计算的目的:
下面介绍下实时计算的业务图,也就是这一块到底在干个什么事情, 先放一张图过来:
上面说了,实时计算业务主要是解决用户的冷启动问题,然后根据用户的点击实时反馈,快速跟踪用户喜好用的。 那么是怎么做到的呢? 用户冷启动问题,就是新来了某个用户,它没有任何点击行为,那么系统怎么给他推荐文章呢? 下面简单描述下这个流程,就是上面图里面画的: