1、简述一下K-means算法的原理和工作流程
聚类
1、简述一下K-means算法的原理和工作流程
随机选择K个样本点作为初始质心
分别计算其他样本到K个质心的距离,对于每一个样本将其划分到与其距离最近的簇内
对于新的簇,计算新的簇中心
重复2,3步,直到簇中心没有移动
2、K-means中常用的到中心距离的度量有哪些?
欧式距离
向量相减平方和开根号
2.曼哈顿距离
向量相减的绝对值之和
3.余弦相似度(处理文档时)
3、K-means中的k值如何选取?
手肘法
K-means聚类最优k值的选取的博客-CSDN博客聚类k的选取 4、K-means算法中初始点的选择对最终结果有影响吗?
有影响,初始点的位置的不同会影响最终聚类效果。
初始点的选择尽量使得相互之间的距离最远
5、K-means聚类中每个类别中心的初始点如何选择? 选择批次距离尽可能远的K个点选用层次聚类或者算法进行初始聚类,然后利用这些类簇的中心点作为算法初始类簇中心点。 6、K-means中空聚类的处理 选择一个距离当前任何质心最远的点。这将消除当前对总平方误差影响最大的点。从具有最大SSE的簇中选择一个替补的质心,这将分裂簇并降低聚类的总SSE。如果有多个空簇,则该过程重复多次。如果噪点或者孤立点过多,考虑更换算法,如密度聚类 7、K-means是否会一直陷入选择质心的循环停不下来?
不会,数学证明一定会收敛。大概思路是利用SSE的概念(也就是误差平方和),即每个点到自身所归属质心的距离的平方和,这个平方和是一个凸函数,通过迭代一定可以到达它的局部最优解。
代码可设置迭代次数,收敛判断距离等
8、如何快速收敛数据量超大的K-means?
分批处理 mini batch
9、K-means算法的优点和缺点是什么?
优点:
原理简单,容易实现调参只需调整一个K值参数可解释性强
缺点:
对离群点和噪声点敏感。K值的选择很难确定。初始值的选择对结果影响较大。聚类结果可能是局部最优而非全局最优。处理不了非凸数据集。如果两个类别距离比较近,结果可能也不好。
10、如何对K-means聚类效果进行评估?
轮廓系数

数据归一化
数据归一化/标准化的好处:
提升模型精度提升收敛速度
标准化:(X-mean)/std
归一化:(X-min)/(max-min)
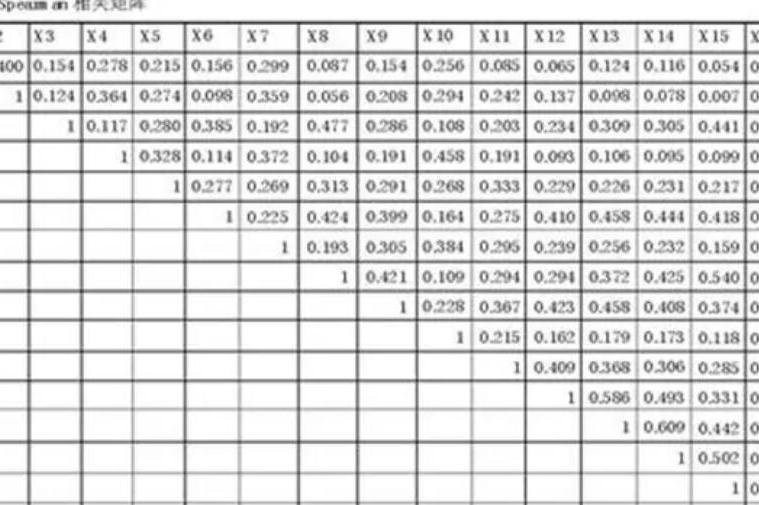
散点矩阵
散点图一般用于描述两个数值型变量之间的关系
散点矩阵解读:
对角线部分:表示第i个特征的分布,x为该特征的值,y轴为该特征的值出现的次数。表示第i个特征的密度估计非对角线部分:第i个特征与第j个特征的散点图,描述两个特征之前的相关性 轮廓系数
聚类效果评估——轮廓系数( )附代码_NLP翟-CSDN博客_轮廓系数代码
评价聚类结果好坏的一种方式
对于簇中的每个向量,分别计算轮廓系数将所有点的轮廓系数求平均就是聚类结果总的轮廓系数
算法
是一种基于密度的空间聚类算法
完整代码
import pandas as pd
from sklearn.cluster import KMeans
from pandas.plotting import scatter_matrix
import matplotlib.pyplot as plt
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn import metrics
# 加载数据
beer = pd.read_csv('E:\\ai\\main\\data.txt', sep=' ')
# 提取特征
X = beer[["calories", "sodium", "alcohol", "cost"]]# kmeans聚类
# 设置聚类核心
km = KMeans(n_clusters=3).fit(X)
km2 = KMeans(n_clusters=2).fit(X)# 聚类的结果作为标签
beer['cluster'] = km.labels_
beer['cluster2'] = km2.labels_
# 对比两种聚类
cluster_centers = km.cluster_centers_
cluster_centers_2 = km2.cluster_centers_
centers = beer.groupby("cluster").mean().reset_index()
# 画图对比
plt.rcParams['font.size'] = 14
colors = np.array(['red', 'green', 'blue', 'yellow'])
plt.scatter(beer["calories"], beer["alcohol"], c=colors[beer["cluster"]])
plt.scatter(centers.calories, centers.alcohol, linewidths=3, marker='+', s=300, c='black')
plt.xlabel("Calories")
plt.ylabel("Alcohol")
# 散点矩阵分析
scatter_matrix(beer[["calories", "sodium", "alcohol", "cost"]], s=100, alpha=1, c=colors[beer["cluster"]],figsize=(10, 10))
plt.suptitle("With 3 centroids initialized")
scatter_matrix(beer[["calories", "sodium", "alcohol", "cost"]], s=100, alpha=1, c=colors[beer["cluster2"]],figsize=(10, 10))
plt.suptitle("With 2 centroids initialized")# 对数据进行缩放
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 缩放后的数据进行聚类
km3 = KMeans(n_clusters=3).fit(X_scaled)
beer["scaled_cluster"] = km3.labels_
beer.sort_values("scaled_cluster")
beer.groupby("scaled_cluster").mean()
pd.scatter_matrix(X, c=colors[beer.scaled_cluster], alpha=1, figsize=(10, 10), s=100)# 聚类评估 轮廓系数
score_scaled = metrics.silhouette_score(X, beer.scaled_cluster)
score = metrics.silhouette_score(X, beer.cluster)
print(score_scaled, score)
scores = []
for k in range(2, 20):labels = KMeans(n_clusters=k).fit(X).labels_score = metrics.silhouette_score(X, labels)scores.append(score)
plt.plot(list(range(2, 20)), scores)
plt.xlabel("Number of Clusters Initialized")
plt.ylabel("Sihouette Score")# DBSCAN聚类
from sklearn.cluster import DBSCANdb = DBSCAN(eps=10, min_samples=2).fit(X)
labels = db.labels_
beer['cluster_db'] = labels
beer.sort_values('cluster_db')
beer.groupby('cluster_db').mean()
pd.scatter_matrix(X, c=colors[beer.cluster_db], figsize=(10, 10), s=100)